多任务并发边缘计算环境中最优联盟结构生成策略
时间:2023-07-01 11:00:03 来源:雅意学习网 本文已影响 人 
赵庶旭,韦萍,王小龙
(兰州交通大学电子与信息工程学院,甘肃 兰州 730071)
随着物联网的快速发展,其设备数量的爆炸性增长所产生的大量数据发送至云端处理会导致高时延、低带宽等一系列问题。移动边缘计算(MEC,mobile edge computing)[1]提供了一种新的计算范式:在更接近用户或数据源的物理位置上处理和分析数据,以此来降低时延、节省带宽。然而在此环境下,资源受限的边缘节点在面对多任务并发场景时存在以下问题。
1) 单个边缘节点由于自身资源受限无法独立完成任务,或无法满足时延敏感型任务需求。
2) 边缘资源有限且高度分布,现有的资源调度方案并不能最大化其资源利用率。
联盟结构(CS,coalition structure)作为一种用来求解合作问题的模型,广泛应用于传感器融合[2]、无线通信网络融合[3]、蜂窝网络协作[4]和资源协同调度[5]等领域。边缘计算环境中边缘节点资源受限条件下的多任务并发资源调度问题[6]可以转化为最优联盟结构生成问题。联盟结构在多任务并发条件下是所有边缘节点集合的划分。其中,边缘联盟是一组平等且通过合作共同完成任务的边缘节点集合。在多任务并发情况下,边缘节点为完成一组并发任务所产生的一组联盟称为联盟结构,其最终目的是通过生成最优联盟结构使社会福利(效用)最大化。然而在边缘计算环境中由于并发任务数量、边缘节点密度、节点计算能力、优化目标和约束条件等因素的影响,最优联盟结构的生成问题较复杂,已成为边缘计算领域的一大挑战。
在有n个智能体的系统中,可能的联盟结构的总数为贝尔数,因此无法使用穷尽法搜索得到最优的联盟结构解。胡山立等[7]在最坏条件下提出了一种新的分组方法和给定限界的联盟结构生成算法。Rahwan[8]将所有潜在联盟结构空间划分为包含相似联盟结构的子空间,从而使用分支限界法高效地搜索所选子空间。张新良等[9]针对联盟数量是智能体个数的指数倍的问题,基于智能体合作收益独立性,提出联盟快速动态生成算法,并对联盟结构图进行剪枝,降低了搜索空间大小。徐广斌等[10]利用动态规划原理针对联盟个数约束的特殊性,设计了联盟约束动态规划算法,并证明其算法时间复杂度为O(3n)。以上算法往往适用于求解小型实例下的联盟结构生成问题。但由于边缘计算环境的特殊性,边缘节点密度相对较高,使用上述算法解决边缘计算环境下的联盟结构生成问题存在一定的局限性。
启发式算法求解最优联盟结构生成问题因其简单直接并能在可接受的时间范围内找到一个相对较优的解而受到广泛关注。对于求解联盟结构,Sen 等[11]首先引入了遗传算法,并采用一维积分编码来搜索最优联盟结构。Yang[12]在Sen 等[11]工作的基础上,提出了一种基于二维二进制染色体编码及交叉和变异算子的不相交联盟形成算法。Contreras等[13]使用改进编码的遗传算法求解联盟结构生成问题,其能够在一个合理的计算时间内获得高质量的解。蒋建国等[14]引入蚁群算法解决多任务联盟问题。蚁群基于信息正反馈机制选择协作性能较好的智能体组成联盟,有效减少了联盟生成的时间以及计算量,但该算法只适用于多任务串行计算场景。Lin等[15]将二进制粒子群优化(BPSO,binary particle swarm optimization)算法扩展为二维二进制编码,并讨论了如何修复无效编码使其有效,但该编码方案效率不高。据Zhang 等[16]所述,在文献[11-15]的方法中,粒子群优化(PSO,particle swarm optimization)算法可以得到与遗传算法(GA,genetic algorithm)和蚁群优化(ACO,ant clony optimization)算法相似的结果,但计算时间明显快于GA与ACO,尤其在解决较大规模实例方面。与遗传算法相比,粒子群算法没有交叉和变异算子,且算法所需调整的参数少。基于此,本文对性能更优的粒子群算法进行了改进。
在利用粒子群算法对联盟结构进行研究方面,Zhang 等[16]开发了一种一维二进制编码方案,在每次迭代过程中使用编码修复策略确保每个编码都是近似有效的。许金友[17]对传统的基于多任务并发的联盟问题进行了分析,指出联盟资源利用方面的不足,并使用离散粒子群优化算法求解多任务联盟结构生成问题。Hu 等[18]借鉴堆智能离散粒子群优化算法解决资源分配问题的思想[19],构造了一种描述资源调度方案的联盟结构表达式。将边缘计算环境中的资源调度问题转化为优化问题模型,设计了适应联盟结构编码方式的多进制离散粒子群优化算法。Zhang等[20]在Hu等[18]的基础上结合合作博弈与启发式算法的优点,引入讨价还价集的概念。通过判断非讨价还价联盟来消除一部分不满足条件的联盟结构,从而达到缩小搜索策略空间的目的。最后使用改进的多进制离散粒子群优化(MDPSO,m-ary discrete particle swarm optimization)算法进行联盟结构的搜索,找到近似最优的联盟结构解。
综上所述,PSO 算法[21]在求解边缘计算环境下的多任务并发问题上已经取得了一定的成果。但在任务数和边缘节点数量多的情况下,算法运行时间较长、稳定性不能保证且容易陷入局部最优解。为了解决上述问题,本文从多进制离散粒子群的位置更新部分出发,提出一种新的位置更新方式——基于离散最近过去的位置更新策略(DRPPUS,discrete recent past-based position updating strategy)。在每一次迭代过程中,将粒子的更新区域确定到一个可能出现最优解的区域,以此来提高搜索效率。
本文主要研究工作及贡献如下。
1) 将资源受限边缘计算环境下的节点调度问题转化为优化问题模型,并使用联盟结构来表示节点的资源调度方案。
2) 为优化粒子群算法,提出一种新的更新策略——基于离散最近过去的位置更新策略,并使用改进的基于离散最近过去位置更新策略的多进制粒子群优化(MDPSO-DRPPUS,m-ary discrete particle swarm optimization discrete recent past-based position updating strategy)算法进行最优联盟结构的搜索。
3) 通过将MDPSO-DRPPUS 与MDPSO 和GA进行比较可知,与MDPSO 相比,MDPSO-DRPPUS的优化速度与最优解质量都得到了提高;
与GA 相比,MDPSO-DRPPUS 的运行时间大幅度降低,联盟结构效益、均衡性和节点完成任务效率都有所提高。
在边缘计算环境中,当多个大规模科学计算任务同时到达时,边缘节点由于自身资源受限无法独立完成任务或无法满足时延敏感型任务需求。为高效完成大规模科学计算的并发任务,边缘节点选择相互协作组成联盟结构处理这批任务成为一种有效的解决方案。本文方法的工作流程如图1 所示。

图1 本文方法的工作流程
首先,边缘节点生成能够处理并发任务的联盟结构,并使用基于索引的编码方式将其编码,形成策略空间。
其次,分析多目标函数,通过指定不同权重,将多目标问题转化为单目标函数。
最后,使用MDPSO-DRPPUS 搜索策略空间,找到目标函数的高质量解。
设边缘节点的集合为N= {n1,n2,n3,…,ni,…,nN},并发任务的集合为M={m1,m2,m3,…,mi,…,mM}。边缘节点可以自发地组成联盟来处理一个任务,当多个任务同时到达时,所有边缘节点组成多个联盟同时完成任务,即联盟结构 CS= {A1,A2,A3,…,Ai,…,ACS}。在联盟结构生成(CSG,coalition structure generation)问题中,联盟Ai定义为集合N的任意一个子集,CS 为集合N的一个完全划分。,对于所有的,当i≠j时,。
典型的联盟生成方法是基于特征值函数[22]的联盟生成,即一个联盟的值由一个特征函数给出,其表示联盟中成员的完成任务所能获得的最大收益。CSG考虑非超加性环境,随着联盟新成员的加入,联盟的成本也随之增加。当系统中多个任务并行处理时,求解目标就是寻找使系统总效益最大的联盟结构。该场景需同时满足以下3 个条件。
1) 参与任务的边缘节点数不小于任务数。
2) 每个边缘节点在相同的时间里只能参与完成一个任务,或者不参与完成任务。
3) 联盟产生正利润。
用集合分割的方法分析联盟结构,联盟结构其实是系统内集合的一个划分。Hart 等[23]证明了联盟结构的准确数量为,其中,Z(n,i)是由i个联盟所能组成的所有联盟结构的数量。Z(n,i)的数量也称为第二类斯特林数(联盟结构计算复杂性的具体证明参考文献[24]),其值为
其中,Z(n,n) =Z(n,1)=1。式(1)右边第一项表示新成员加入现有的联盟形成的联盟结构的数量;
式(1)右边第二项表示将新的成员加入自己的联盟中。
例如,在边缘节点集合n= {1,2,3,4}中,联盟的个数为2n-1(不包含空集),共计15 个联盟,所以联盟结构的个数为15。4 个智能体(Agent)的联盟结构如图2 所示。

图2 4 个Agent 的联盟结构
1.1 问题建模
1.1.1 时间约束
记任务完成的截止时间为DLi,要求联盟Ai完成各任务的时间ti必须小于或等于各任务完成的截止时间,即ti≤ DLi。联盟结构中的所有联盟都按时完成任务,形成一个有效的联盟结构。由木桶效应可知,联盟结构的任务完成时间取决于有效联盟结构中完成任务时间最长的联盟,即t(CSi)=max(t(Ai))。
1.1.2 效用函数
联盟完成任务后会获得一定的收益,定义Ei为联盟Ai完成任务mi的收益,CPi为边缘节点ni的计算能力。联盟的计算能力支出即组成联盟的边缘节点的计算能力支出总和,即。定义各边缘节点组成联盟的损耗函数为L(Ai),损耗函数是指节点之间组成联盟引起的开销,其包括联盟间的通信损耗、计算冗余等。由于损耗是由节点之间协同组成联盟所造成的,因此为单调递增函数,且随着联盟内成员的增加而增加,即
一个联盟完成任务mi的利润可以用联盟的收益与成本进行计算。设P(Ci)表示一个联盟完成任务mi的利润,其计算方式为收益-成本-额外损耗,即
1.1.3 均衡性
基于个体理性原则,成员所做出的决策都是明智且理性的。节点期望加入支出最小、效益最大的联盟,其可以通过性价比衡量。联盟的性价比函数定义为
为保证联盟结构中各联盟的均衡性,即要求联盟结构中各联盟间的性价比差异最小。因此,使用方差来度量其均衡性,即
1.2 解法模型
为了解决该多目标优化问题,本文使用线性加权法将多目标优化问题转化为一个综合的目标函数。对于P1、P2 和P3,其权重分别为ω1、ω2和ω3,且ω1+ω2+ω3=1。
联盟结构的特征值函数为组成联盟结构联盟的特征值总和,即
权重系数会影响最优解的求解结果,ω1是任务完成时间的权重系数,会使算法倾向于搜索更高效的联盟结构;
ω2是效用权重系数,会使算法倾向于搜索效用值较大的联盟结构;
ω3是性价比权重系数,会使算法倾向于搜索满足所有节点性价比的联盟结构。由于大多数场景更关注时延和能耗,因此本文在实验中弱化性价比权重系数ω3,并设置ω3=0.1。分析不同ω1和ω2条件下优化速度和最优解质量的影响,重复进行多次实验,实验结果表明,ω1对算法的平均运行时间影响不大,同样需弱化ω1,令ω1=0.1。因此,ω2=0.8。
启发式算法在求解联盟结构生成这类复杂的组合优化问题时,其共同点是从随机的可行解开始,经过不断的迭代、改进、变异,最终无限趋近于问题的最优解。但是面对大规模的联盟结构搜索空间,原始启发式算法因其运行时间长、易陷入局部最优解等缺点并不能获得较优的解。因此,本文提出了基于离散最近过去位置更新策略的多进制粒子群优化算法。
寻找一种适用于该场景下联盟结构的编码方式是使用启发式算法求解该问题的第一步。因此,首先使用基于索引的联盟结构编码方式对联盟结构进行编码,将编码粒子的长度与参与任务的边缘节点数对应起来,并将粒子每个维度的索引与任务编号对应起来,用以满足本场景下的约束条件。其次,本文对原始粒子群算法的更新方式进行改进,引入政治优化器(PO,political optimizer)中的更新策略——基于最近过去的位置更新策略。再次,为了使其适用于本文场景下联盟结构的编码方式,对该更新策略进行离散化改进。最后,对所提算法的复杂度进行分析。
2.1 联盟结构的编码方式
任何一个有效的联盟结构都以任务的完成为前提,联盟结构中联盟的数量就等于其所要完成任务的数量,即。联盟与联盟的结构关系如图3 所示。
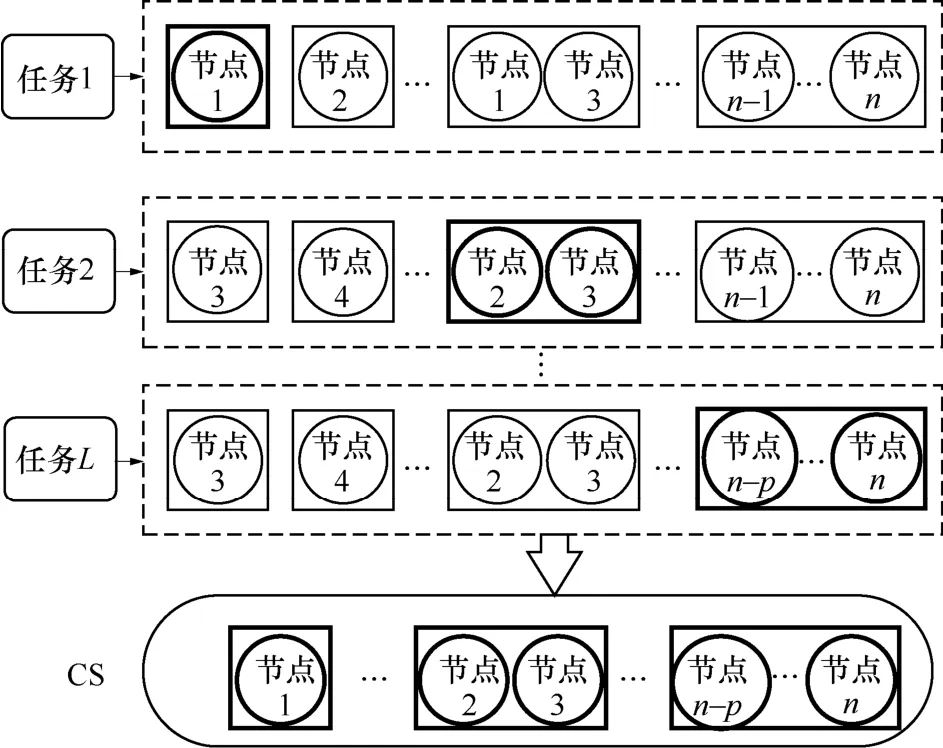
图3 联盟与联盟的结构关系
在该场景中,所要搜索的最优联盟结构需同时满足以下4 个约束条件。
1) 联盟实际完成各任务的时间应小于或等于各任务的计划完成时间。
2) 参与联盟结构节点的数量不应超过边缘节点的总数。
3) 每个节点最多只能参与完成一个任务。
4) 每个任务至少需要一个边缘节点完成。
为了使联盟结构的编码能够满足约束2)~约束4),本文选用基于索引的联盟结构编码方式。定义Di代表节点ni参与任务,且。联盟结构的编码方式可记为。


图4 基于索引的联盟结构编码方式
2.2 基于改进更新策略的MDPSO
原始的粒子群算法存在过早收敛、容易陷入局部最优值、收敛速度慢等缺点。因此,本文提出一种改进的DRPPUS 的MDPSO 算法。
2.2.1 DRPPUS
该更新策略是Askari[25]在2020 年提出的政治优化器中的更新机制[26]。
基于最近过去更新策略保存了前一次迭代时算法所学习到的信息,更新每一个成员当前最优解的位置来寻找下一次可能的最优解位置。算法使用式(7)和式(8)来更新其可能的最优解位置,根据成员当前得到的适应度值与前一次适应度值确定选择式(7)或式(8)进行位置更新。若特征值函数有所提高,则使用式(7);
反之,则使用式(8)。在这2 种情况中,位置的更新依据当前可能的最优解、变量r和可能的参考解,其中,随机数r的取值范围为[0,1] 。
RPPUS 表示如图5 所示,图5(a)~图5(c)说明了式(7)的3 种情况,图5(d)~图5(f)说明了式(8)的3 种情况,主要目的就是找到最有可能产生最优解的区域。
情况1如图5(a)所示,成员的当前位置位于可能的参考解和前一次位置之间,可能产生最优解的区域用灰色标出,其范围为。
情况2当成员的参考解位置位于当前位置和前一次位置之间时,可能产生最优解的区域如图5(b)所示,其范围为。
情况3成员的前一个位置位于参考解与当前位置之间,如图5(c)所示,可能产生最优解的区域在参考解附近,同理,因为。

图5 RPPUS 表示
2.2.2 MDPSO-DRPPUS
针对最近过去位置更新策略的离散化改进如式(9)~式(22)所示。该更新策略在一个可能产生最优解的区域内进行更新,实际更新有可能超出该区域。所以定义一个整型函数R(s,e),相关参数的范围为,算法决策变量的更新范围为。
若式(7)的C1 成立,则有
位置更新式为
其中,s=0,e为
针对式(7)的C2 和C3,有
位置更新式为
对于式(8)的C1 和C3,有
位置更新式为
对于式(8)的C2,有
位置更新式为

MDPSO-DRPPUS 算法的伪代码如算法1 所示。
算法1MDPSO-DRPPUS 算法
输入联盟结构信息(联盟结构编码、完成任务所获利润、任务截止时间、成本支出等,该列表构成策略空间),MDPSO-DRPPUS 信息(粒子信息,包括粒子更新位置、适应度值、粒子的全局最优位置),参数设置(种群个数NP、迭代次数G、编码长度(节点数N)、随机数r、决策变量上限、决策变量下限)
输出全局最优解(最优联盟结构)
1) 初始化每一个粒子的随机位置;
2) 计算每一个粒子的适应度;
4) 设迭代次数g=1;
5) 如果g≤G;
6) 判断粒子前一次适应度值与这次适应度值的大小,若适应度值有所提高,则使用式(7)的3 种情况进行判断,并按照情况选择相应离散化的位置更新式来更新粒子位置,反之亦然;
8) 判断粒子适应度值是否提高,若不提高则结束迭代,否则转步骤9);
9)g=g+1,转步骤6);
10) 输出粒子的最优解及对应粒子位置。
2.3 MDPSO-DRPPUS 的算法复杂度分析
MDPSO-DRPPUS 算法的最大计算量是粒子数与迭代次数的乘积,增加粒子数可以扩大搜索范围,降低算法陷入局部最优解的可能性,增加迭代次数则可以提高最优解质量。算法的计算量是算法对特征值函数的求解,在一次算法执行过程中,特征值函数的计算分为3 个阶段。
1) 计算任务完成时间最长的节点,计算次数为N。
2) 根据式(2),将所有形成联盟结构联盟的利润加起来,联盟结构的利润计算次数为(M+1)(N+1)。
3) 根据式(3)~式(5),联盟结构均衡性的计算次数为 (M+1)2(N+1)。
综上,MDPSO-DRPPUS 的计算复杂度最低,计算量最大为sum= NPG((M+2)(N+1)(M+1) +N)。
本文的仿真实验是在内存为16 GB、处理器为Inter Core i5-4460、频率为3.2 GHz 的Windows10 操作系统环境下使用Python3.7 实现的。通过模拟和仿真,对本文所提算法和对比实验的各项指标进行评估。
3.1 实验准备以及实验数据
创建虚拟机来模拟边缘节点,表1 给出了实验环境中虚拟机配置,表2 显示了任务工作量、计划完成时间和任务报酬,表3 显示了环境参数。

表1 实验环境中虚拟机配置
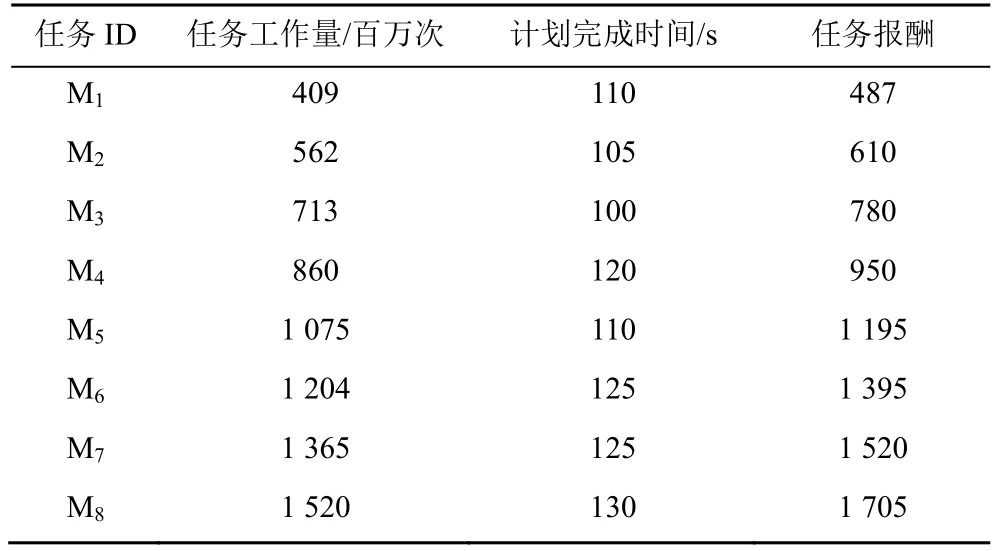
表2 任务工作量、计划完成时间和任务报酬

表3 环境参数
3.2 MDPSO-RPPUS 算法的性能实验
本节在不同迭代次数条件下比较了3 种算法(MDPSO-RPPUS、MDPSO 和GA)在16 个边缘节点上完成4 个任务(M1、M2、M3和M4)时的算法平均运行时间、最优联盟结构效益、均衡性和节点使用率,并分析了不同迭代次数对算法性能的影响。针对粒子数为100 个、不同迭代次数进行10 组实验,迭代次数从50 增加到500(每增加100 次进行一组实验,每组实验进行5 次,最终结果取平均值)。图6 是不同迭代次数下3 种算法性能比较。
由图6(a)可知,MDPSO 和GA 的运行时间都随着迭代次数的增加而增加,这是启发式算法求解问题的特点。而MDPSO-DRPPUS 算法的运行时间随迭代次数的增加变化不大,且算法运行时间在毫秒级,这是因为该算法往往能在迭代10 次以内收敛。由图6(b)可知,3 种算法联盟结构的效益随迭代次数增加变化较小,且结果不稳定。由此看来,通过增加迭代次数使3 种算法获得较好结果的做法意义不大。由图6(c)可知,与MDPSO 和GA 相比,MDPSO-DRPPUS 联盟结构均衡性较优,且GA 最不稳定。由图6(d)可知,MDPSO-DRPPUS 算法的节点调度策略对运算量较大的任务分配多个边缘节点进行计算,能够避免多个节点很快完成计算量小的任务,但仍需等待并发任务中计算量较大任务的完成。该算法使用最少数量的节点完成任务,提高了任务完成效率。

图6 不同迭代次数下3 种算法性能比较
针对不同粒子数,比较3 种算法在16 个边缘节点上完成4 个任务(M1、M2、M3和M4)时在4 种标准下分析不同粒子数对算法性能的影响。针对迭代次数为500、不同粒子数进行10组实验,粒子数从10 个增加到100 个(每次增加10 个进行一组实验,每组实验进行5 次,最终结果取平均值)。图7 是不同粒子数下3 种算法性能比较。

图7 不同粒子数下3 种算法性能比较
图7(a)、图7(c)、图7(d)所示结果与图6(a)、图6(c)、图6(d)相同,此处不再赘述。由图7(b)可知,MDPSO-DRPPUS 算法随着粒子数的增多联盟结构效益增长较快,这是因为DRPPUS 极大地提高了算法的开发能力。因此本文推测可以通过大幅度提高算法的粒子数来避免MDPSO-DRPPUS 陷入局部最优解的可能。
在迭代次数为10 的情况下大规模增加粒子数,比较3 种算法在16 个边缘节点完成4 个任务(M1、M2、M3和M4)时在4 种标准下的算法性能。针对不同粒子数进行6 组实验,粒子数从200 个增加到1 200 个(每次增加200 个进行一组实验,每组实验进行5 次,最终结果取平均值)。图8 是迭代次数为10 时不同粒子数下3 种算法性能比较。
图8(c)和图8(d)与图6(c)和图6(d)结果类似。由图8(a)可知,在迭代次数为10 的情况下,大规模增加算法的粒子数(GA 大规模增加其基因数),当粒子数增加到1 200 时,MDPSO-DRPPUS 算法平均运行时间为2 s 左右;
MDPSO 算法平均运行时间为6 s 左右;
GA 平均运行时间已达到257 s。由图8(b)可知,MDPSO-DRPPUS 算法随着粒子数的大规模增加联盟结构效益增长较快,进一步证明了之前的推断。

图8 迭代次数为10 时不同粒子数下3 种算法性能比较
在不同边缘节点(VM9-VM16、VM8-VM16、VM7-VM16、VM6-VM16、VM5-VM16、VM4-VM16、VM3-VM16、VM2-VM16、VM1-VM16)条件下测试3 种算法在4 种标准下的性能。为了避免任务量过大导致任何联盟结构都无法完成任务的情况,选择4 个计算量最小的任务(M1、M2、M3和M4)进行9 组实验(每增加一个边缘节点进行一组实验,每组实验进行5 次,最终结果取平均值)。设置3 种算法(MDPSO-RPPUS、MDPSO 和GA)的最大迭代次数G=50,最大粒子数NP=500。图9 显示了不同节点数下3 种算法性能比较。
图9(a)、图9(c)、图9(d)与图6(a)、图6(c)、图6(d)结果类似,此处不再赘述。由图9(b)可知,当边缘节点数为9 和13 时,3 种算法的最优联盟结构特征值都有了明显的提升,这是因为添加了计算能力较强的VM8和VM4,可以使其他节点提供更多的资源去处理运算量较大的任务。

图9 不同节点数下3 种算法性能比较
在不同任务数的性能实验中,设置所有节点参与任务,当任务数小于4(M< 4)时,策略数小于 4.29 ×109。实验最小任务数设置为4(每增加一个任务进行一组实验,每组实验进行5 次,最终结果取平均值)。设置3 种算法的最大迭代次数G=50,最大粒子数NP=500。图10 显示了不同任务数下3 种算法性能比较。

图10 不同任务数下3 种算法性能比较
由图10 可知,当任务数为8 个时,由于添加了任务量过大的M8,3 种算法在当前条件下均不能完成任务,这是因为M8的计算负载过大,从而导致边缘节点无法按时完成任务。
综上所述,相较于MDPSO 和GA,本文提出的MDPSO-DRPPUS 算法运行时间大幅度降低,开发能力也得到了极大提高。在面对此类复杂的组合优化问题时,MDPSO 和GA 依旧面临陷入局部最优解的困境,但所提算法可以通过大幅度增加粒子数避免这一缺陷。实验结果表明,MDPSO-DRPPUS 的粒子数增加到5 000 个时算法运行时间为10 s 左右。增加粒子数后,联盟结构效益也随之得到提升。此外,MDPSO-DRPPUS 所得联盟结构的均衡性和节点使用率均优于MDPSO 和GA。
因此,与MDPSO 和GA 相比,MDPSO-DRPPUS在优化速度及最优解质量方面都得到了较好的提升。
本文提出了MDPSO-DRPPUS 算法进行最优联盟结构搜索,很好地解决了多任务并发边缘计算环境中的最优联盟结构搜索问题。实验结果表明,MDPSO-RPPUS 算法有很强的搜索能力,收敛速度很快(能在迭代10 次以内收敛),运行时间相对于MDPSO 和GA 而言大幅度降低,搜索到的最优联盟结构效益和联盟结构均衡性也相对较优。
在本文场景中,联盟结构的数量随着任务数和边缘节点数的增加呈指数级增长。虽然智能算法对联盟结构的搜索已经取得了一定的成果,但由于策略空间巨大,下一步可否先将庞大的策略空间处理后再进行搜索成为一个值得研究的课题。
猜你喜欢边缘次数粒子机场航站楼年雷击次数计算智能建筑电气技术(2022年2期)2022-02-062020年,我国汽车召回次数同比减少10.8%,召回数量同比增长3.9%商用汽车(2021年4期)2021-10-13一类无界算子的二次数值域和谱数学物理学报(2020年6期)2021-01-14基于粒子群优化的桥式起重机模糊PID控制测控技术(2018年10期)2018-11-25基于粒子群优化极点配置的空燃比输出反馈控制浙江工业大学学报(2017年5期)2018-01-22依据“次数”求概率中学生数理化·中考版(2017年12期)2017-04-18一张图看懂边缘计算通信产业报(2016年44期)2017-03-13基于Matlab的α粒子的散射实验模拟物理与工程(2014年4期)2014-02-27基于两粒子纠缠态隐形传送四粒子GHZ态山西大同大学学报(自然科学版)(2014年3期)2014-01-23在边缘寻找自我雕塑(1999年2期)1999-06-28








