基于帕累托效应视角下的推荐系统多角度公平性
时间:2022-12-09 13:20:02 来源:雅意学习网 本文已影响 人 
杜清月,黄晓雯,桑基韬
(北京交通大学 计算机与信息技术学院,交通数据分析与挖掘北京市重点实验室,北京 100044)
推荐系统通过学习用户的行为捕捉用户偏好,继而为用户推荐符合用户兴趣的物品或信息。目前常见的推荐系统应用场景有:电子商务、电影和视频、音乐、社交网络、阅读、基于位置的服务、个性化邮件和广告等。在线平台使用推荐系统挖掘用户潜在的兴趣从而获得巨大的商机和盈利。
尽管推荐系统在工业应用中获得广泛应用,并已被验证其有提升平台效益的作用,然而推荐系统使用的用户行为数据是观察性的,这使得数据中广泛存在的各种偏差会导致推荐系统的结果出现不公平的现象。推荐系统是一个多利益相关者的复杂系统,其中涉及的角色有作为接受推荐物品的用户和提供物品的商家,如图1所示。根据推荐系统影响的角色可以将推荐系统公平性分为用户角度公平性和物品角度公平性。用户角度公平性指推荐系统会根据用户私有敏感属性提出推荐建议,而不是用户的真实偏好,这对具有不同敏感属性的用户来说是不公平的。物品角度公平性是由于物品私有属性(例如曝光,位置)不同,导致物品得到的点击概率不同,从而影响推荐系统捕捉用户偏好而造成推荐误差,从而引起物品角度的不公平现象。

图1 推荐系统中用户角度和物品角度公平性示意图Fig.1 User fairness and item fairness in recommender system
用户角度公平性是由于推荐系统的数据是观察得到的,推荐系统在分析这些数据后往往会得出一些虚假的相关性结论,即用户的偏好与其私有敏感属性(例如性别、年龄、职业等)高度相关,这导致推荐系统会根据用户的敏感属性做出推荐建议。例如,美妆视频的点击量大部分来源于女性,NBA相关视频则更受男性青睐,推荐系统往往倾向于向女性推荐美妆视频,向男性推荐NBA视频,在这种情况下,推荐系统受到用户敏感属性的严重影响,对美妆和NBA都喜欢的用户无法获得足够的推荐信息,对这类用户来说是不公平的。公平的推荐系统在给用户做出推荐时并不过分依赖用户敏感属性。目前许多研究工作提出消除用户敏感属性信息来获得公平的推荐,但是这些策略在消除用户敏感属性信息时往往会出现多目标的帕累托效应问题。通常情况下,提高用户角度公平性会损害推荐准确率[1],这与推荐系统保证推荐性能的基础目标相悖。因此,解决用户角度存在的不公平性,构建用户公平感知的推荐系统具有两个目标:一是提升用户角度公平性,二是保证推荐系统准确率。
物品角度的公平性是由于物品某些私有属性导致其得到的推荐概率不同,推荐系统经过数据分析会加重这种偏差。常见物品角度公平性问题有物品曝光偏差和位置偏差等。针对物品角度的偏差问题,很多研究工作使用采样的方式通过对数据进行处理从而均衡偏差[13-14]。大多数推荐算法普遍将与用户发生交互的物品作为正样本,与用户未发生交互的物品作为负样本。然而实际情况下,由于曝光偏差的存在,被曝光的物品与用户发生交互,在训练过程中作为正样本,没被曝光的物品作为负样本,而没被曝光的物品用户尚未接触,并非不喜欢,从而产生偏差。通过这种数据训练的推荐系统模型会根据曝光来选取推荐的物品,导致高曝光的物品推荐率越来越高,低曝光的物品推荐率越来越低。本文通过基于曝光的负采样策略更准确地捕捉用户偏好,缓解曝光偏差问题,提高推荐系统的准确率。
本文采用对抗学习方法,通过训练对抗正则化器来消除用户向量中的偏见属性信息,提升用户角度公平性。由于解决用户角度公平性存在公平性和推荐准确率之间的帕累托最优,因此,本文采用基于曝光的负采样策略来解决物品角度的曝光偏差问题,使得推荐系统能够准确地捕捉用户偏好,在保证用户角度公平性的同时提高推荐系统准确率,从而达到帕累托最优。在加入基于曝光的负采样策略之后能够让高质量的物品得到更高的曝光,低质量的物品则得到更低的曝光,与质量成正比的曝光率对于提供物品的商家来说是公平的曝光策略[18]。本文的方法在解决用户角度的帕累托最优问题的同时保证了用户和物品的多角度公平性。
本文的主要贡献包括:
1) 通过对抗学习解决用户角度公平性问题,主要包括性别、年龄、职业3个用户属性的公平性。
2) 针对用户角度公平性中存在的帕累托效应问题,通过引入基于曝光的负采样策略提高推荐系统准确率从而达到帕累托最优。
3) 基于曝光的负采样策略在一定程度上解决物品曝光偏差的问题,保证了物品角度的曝光公平性,从而达到推荐系统的用户和物品的多角度公平性。
1.1 用户角度公平性中的帕累托效应
推荐系统中用户角度的公平性研究目的是使推荐系统在做出推荐意见时与用户的私有敏感属性(例如性别,年龄,职业,种族等)无关。目前很多工作致力于消除用户敏感属性信息,使得拥有不同敏感属性的用户拥有公平的推荐建议。常用于解决用户角度公平性的一类方法是对抗学习。对抗学习的目的是消除用户敏感属性信息得到公平的用户表示,基本思想是通过在推荐模型和对手模型之间玩一个最大最小的游戏,最小化对手模型对于用户敏感属性的预测能力是通过降低对手模型的预测能力来消除用户表示中的敏感属性信息。EDWARDS et al[2]首先提出了对抗的框架ALFR(Adversarial Learned Fair Representation)来消除数据表示中的敏感属性信息。BOSE et al[1]使用组合对抗的思路,去除数据中的多种敏感属性信息(例如MovieLens数据集中性别,年龄和职业等敏感信息)。随后,WU et al[3]提出了由于用户之间并不是独立的,而是具有一定的联系,在组合对抗中加入图谱信息建立用户关系,以图谱的视角利用组合对抗去除数据中的多种敏感属性信息。BEIGI et al[4]从隐私保护的角度使用对抗学习的思路消除推荐系统中用户敏感属性对于推荐结果的影响,使得推荐系统在受到攻击时能够保护用户敏感属性。WU et al[5]提出了一种基于分解对抗学习和正交正则化的公平新闻推荐方法,可以解决推荐系统中用户偏见属性带来的不公平性问题,该方法在解耦用户偏见属性信息时加入正交正则化策略,使得偏见信息更好地和用户偏好解耦,提高了推荐系统的公平性。但是这些方法都普遍存在帕累托效应问题。在解决用户角度公平性时往往是问题建模成多目标优化问题,在平衡用户角度公平性和推荐系统推荐性能时通常存在帕累托效应,即:公平性和推荐性能之间存在冲突,如何优化这两个目标是推荐系统公平性问题中需要解决的问题。在帕累托优化问题中的一个经典的方法[6]是基于scalarization method的MGDA(Multiple gradient descent algorithm)模型,通过加权的方式将多目标转化成一个目标,这种加权的权重通常是人为定义,但并不能保证帕累托最优。XIE et al[7]提出了一种个性化近似帕累托最优的多目标推荐框架PAPERec,通过一个强化学习模块来近似逼近帕累托最优。另一种方法是启发式搜索,主要流行算法是进化算法,主要应用在推荐系统多样性和长尾分布的场景中。
1.2 推荐系统多角度公平性
在解决用户角度公平性和推荐系统准确率之间的帕累托效应之后,还要考虑推荐系统中用户和物品的多角度公平性问题。推荐系统的数据中存在很多物品角度的偏差,这些偏差会造成推荐系统在给出推荐建议时存在物品角度的不公平问题,例如物品曝光偏差、位置偏差、流行度偏差等。CHEN et al[8]提出了一种基于元学习的通用去偏框架,将寻找最优去偏策略问题转化为设置框架中的去偏参数问题,利用少量的无偏数据作为监督信息,采用元学习的策略来学习框架中的去偏参数。在解决流行度偏差时通常使用因果图[9]、反事实推理[10]、对抗学习[11]等方法来消除物品角度的流行度偏差的公平性问题。在本文中主要关注曝光偏差带来的推荐系统公平性问题。用于解决曝光偏差的方法目前有基于曝光函数的推荐[12],基于负采样的推荐[13-14]等。例如WANG et al[14]提出基于强化负采样的方法通过寻找真实的负样本来解决曝光偏差为推荐系统带来的负面影响,从而提高推荐性能和物品角度的公平性。推荐系统是一个多利益相关者的复杂系统,ABDOLLAHPOURI et al[15]按照推荐系统中相关利益的角色总结出对应不同角色的公平性。BURKE et al[16]提出了一种基于最近邻的改进版本的稀疏线性方法(SLIM)来解决推荐系统多角度公平性的问题。ABDOLLAHPOURI et al[17]通过对数据的实验分析推荐系统中的曝光偏差对多角度公平性的影响,并提出衡量多角度曝光偏差公平性的评价指标。WU et al[18]提出了多角度公平感知的推荐模型(TRFOM),通过调整推荐列表中物品的排名来解决多角度公平性的问题。
本文提出一种多角度公平的推荐系统(multi-side fairness recommendation system,MsFRS),从帕累托视角解决推荐系统多角度公平性。本节首先对推荐系统中的帕累托效应进行实验验证,再对MsFRS的具体方法进行详细阐述。图2为整体框架图,主要包含3个部分:1) 推荐模型,即根据用户和物品历史数据为用户提供推荐物品;
2) 基于对抗学习的用户角度公平性模块,使用对抗正则器消除用户敏感属性信息;
3) 基于曝光的负采样模块,计算物品的曝光度,通过采样策略选择合适的负样本缓解曝光偏差,提高推荐系统准确率。其中涉及的符号定义如表1所示。
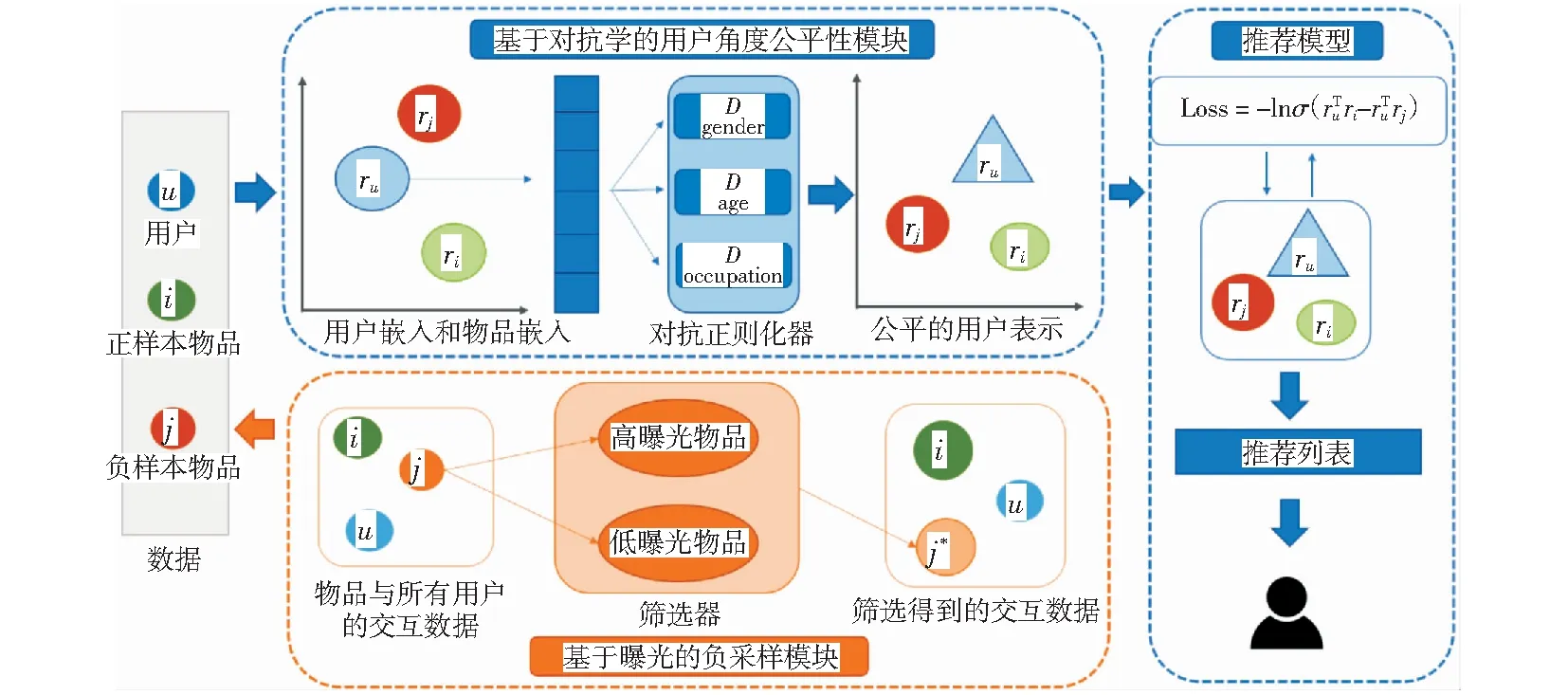
图2 MsFRS方法框架图Fig.2 Architecture of MsFRS approach

表1 符号及其描述Table 1 Notations and descriptions
2.1 推荐系统的帕累托效应问题
表2是使用组合对抗方法[1]解决用户角度公平性时在用户性别、职业、年龄公平性结果。其中性别使用分类AUC,职业和年龄使用F1作为评价指标。组合对抗方法是对单一的敏感属性采用对抗学习的方法来去除敏感属性信息,随后将过滤掉敏感属性信息的用户进行组合,从而达到去除多种敏感属性信息的目的。

表2 不同方法在用户性别、职业、年龄公平性对比Table 2 Comparison of different methods in the fairness of users’ gender, occupation and age
组合对抗的方法与无对抗对比方法相比,在性别、职业、年龄3个属性上的分类指标都有明显的下降,说明组合对抗的方法能够很好地消除用户敏感属性信息,提高用户角度公平性。图3是使用组合对抗方法[1]解决用户角度公平性在推荐性能上的实验结果,与没有使用对抗的基线相比,其推荐系统均方误差RMSE提高10%,说明组合对抗方法在提高用户角度公平性时,会损失推荐性能,证明在解决用户角度公平性时确实存在公平性和推荐准确率之间的帕累托效应。

图3 组合对抗准确率RMSEFig.3 Compositional adversary RMSE
2.2 推荐模型
为了验证多角度公平的推荐系统MsFRS在推荐性能和公平性上有效性,本文采用了相对简单的线性推荐模型矩阵分解(MF)[19]作为推荐器R.给定数据集D,假设用户和物品历史数据为O+={(u,i)|u∈U,i∈I},其中U为数据集中的用户集合,I为物品集合。矩阵分解将用户和项目信息参数化为用户嵌入和项目嵌入,并利用用户嵌入和物品嵌入来预测用户u对于物品i的购买可能性,其目标函数为:
(1)

为了能够与基于曝光的负采样模块相结合,采用成对的BPR[19]的损失函数。特别的,BPR损失函数的目标是对于任何一个用户来说,有历史数据的物品评分应该大于没有历史数据的物品评分,如下:
(2)
式中:σ(·)是激活函数,训练推荐器来计算用户相对于j更喜欢i的概率。j~fS(u,i)是通过负采样策略得到负样本。
2.3 基于对抗学习的用户角度公平性
在推荐系统的用户数据中通常包括用户的私有敏感属性,例如用户的性别、年龄等属性。假设对所有的用户u∈U都有K个偏见属性ak∈A,k=1,…,K.用户角度公平性的目的是让推荐系统根据用户的偏好提供推荐意见,与用户的私有敏感属性无关。对于用户u形式上可以表示为:
fR(u,i)⊥a,∀i∈I.
(3)
而在矩阵分解中,假设用户的敏感属性信息仅存在于用户嵌入ru中,则上述公式可以写为:
ru⊥a,∀u∈U.
(4)
换言之,用户嵌入与偏见属性之间的互信息为0,即I(ru,a)=0.
为了训练消除偏见属性信息的公平的用户向量,使用了一个对抗正则化器,对于敏感属性k∈K,使用一个分类器Dk:Rd×Ak├[0,1],它用来从用户嵌入ru中预测第k个偏见属性ak,由推荐器选择使用矩阵分解方法,使用BPR的损失函数,加入对抗正则化的损失函数可以定义如下:

(5)
式中:λ是一个控制对抗正则化强度的一个超参数。为了优化这个损失函数,采用交替训练的方式:1) 固定LD参数,更新优化推荐损失LR.2) 固定推荐损失LR,更新优化对抗正则化损失LD.理论上来说,当对抗正则化器的权值λ增加到无穷大时,用户嵌入与偏见属性之间的互信息为0,此时达到最公平的效果。但是当λ无穷大时,会影响推荐准确率,所以在现实的实验设置中,λ是推荐准确率和用户公平性之间的一个权衡。所以本文的方法后续通过基于曝光的负采样模块在不影响用户公平性的前提下,提高推荐准确率。fS是基于曝光的负采样策略,j是通过fS得到的负样本。
2.4 基于曝光的负采样策略
为了解决用户角度公平性问题中存在的帕累托效应,本文通过基于曝光的负采样方法解决物品角度的曝光偏差来提高推荐准确率和物品公平性。在成对的正负样本数据中,曝光偏差主要影响在负样本的选择上。通常负样本会随机选择与用户没有历史行为的物品。但是由于曝光偏差的存在,这样的物品并不是真正意义上的负样本。随机选择的负样本因为曝光偏差的存在会影响推荐准确率。基于曝光的负采样策略首先是对物品进行分组,根据物品与用户交互的次数分成高曝光物品组Ihigh和低曝光物品组Ilow。
I=Ihigh∪IlowandIhigh∩Ilow=φ .
(6)
正样本通常选择与用户交互的物品,而这些物品通常是具有高曝光率的物品。文献[21]的研究工作表明,基于流行度采样也就是静态的对流行度过采样会使迭代收敛过程中过早停止,导致负样本缺乏多样性,且会影响推荐质量。所以本文并没有从高曝光的物品中进行采样。其次,对于高曝光的物品更有可能是真实的负样本问题,对于召回模型的训练样本来说,既要有和用户最匹配的样本,也要有和用户最不匹配的样本。而高曝光率的物品很有可能是上一版本的推荐模型给用户筛选后得到的,推荐系统认为这些物品对于用户来说是比较匹配的,如果继续拿高曝光的物品去做召回会影响推荐模型,而低曝光的物品对用户来说则是最不匹配的。所以本文最终采用在低曝光组对负样本进行采样。
j~fS(u,i),i∈Ilow.
(7)
基于曝光的负采样策略是通过提高推荐系统的准确率从而解决帕累托效应,通过在一定程度上缓解曝光偏差的问题来保证物品角度的公平性,从而达到推荐系统的用户和物品的多角度公平性。
3.1 数据集
本文选择推荐系统中常用的数据集MovieLens2数据集来验证提出的多角度公平的推荐系统MsFRS.数据集相关的统计信息如表3所示。本文使用的是正负样本对的BPR损失函数,而MovieLens数据集是评分数据,所以对数据集中的评分进行预处理:将所有用户与物品的历史数据视为正样本并且标记为1,负样本通过负采样的策略得到并标记为0.MovieLens数据集中的3个用户属性性别、年龄和职业作为用户的敏感属性。其中性别为二值敏感属性,年龄和职业建模为多值敏感属性。

表3 数据集统计Table 3 Statistics for the dataset
3.2 评价指标
本文采用3方面评价指标,分别是用户角度公平性评价指标,推荐准确率评价指标,物品角度公平性评价指标。
3.2.1用户角度评价指标
用户角度公平性评价指标选择敏感属性对抗正则化分类器的评价指标。分类准确率越低则代表用户向量中的敏感属性信息越少,推荐建议受敏感属性的影响越小,用户角度的公平性越高。
由于性别是二分类目标,选择AUC作为性别分类的评价指标,理想状态下,AUC为0.5时达到公平性的最优状态。年龄和职业为多分类问题,选择宏F1值作为评价指标。具体定义如下:
(8)
(9)

3.2.2推荐准确率评价指标
推荐系统准确率使用常用的评价指标:HR@K,NDCG@K,具体定义如下:
(10)
(11)
式中:N为用户数目,hits(i)为第i个用户访问的物品是否在推荐列表中,pi为第i个用户真实访问的物品在推荐列表的位置。
3.2.3物品角度公平性评价指标
物品角度评价指标主要是衡量曝光偏差的公平性,我们认为质量越高的物品曝光越高对于推荐系统是越公平的,在评估物品质量时,本文参考了论文[18]中关于物品质量的定义,物品的曝光与物品质量成正比对于推荐系统来说是公平的。具体地,本文参考论文[20]中对于物品质量的定义:将与用户交互次数来定义物品的质量,与用户交互次数越高,则质量越高。对于推荐系统来说,并不是对所有的物品具有相等的曝光率是公平的,这样会严重影响推荐性能,所以采用了和质量成正比的曝光率,具体定义如下:
(12)
式中:ehigh和elow分别表示高曝光组物品的曝光率和低曝光组物品的曝光率;
Ihigh和Ilow分别表示高曝光组和低曝光组物品的质量,在具体的实验设置中,本文采用了在全局数据中物品与用户交互次数来表示该物品的质量,即与用户交互次数越多的物品其质量越高。理想状态下,当高曝光组物品和低曝光物品的曝光与质量的比值相等时,推荐系统达到物品角度曝光偏差的公平。在实验中,使用高曝光组物品与低曝光组物品的曝光与质量比值的差值来衡量推荐系统的物品角度的公平性,即:
(13)
3.3 对比方法介绍及参数设置
本文实验采用以下3种对比方法:
1) 无对抗+随机采样。使用选择的MF推荐算法设置λ=0,即没有对抗正则化器,负样本选择采用随机采样。
2) 对抗+随机采样。使用对抗正则化器消除敏感属性,且负样本选择采用随机采样。
3) MsFRS.使用对抗正则化器消除敏感属性,且负样本通过基于曝光的负采样策略得到。本方法为本文提出的多角度公平的推荐系统。
数据集按照9∶1的比例划分为训练集和测试集。用户嵌入的维度ru设置为32.与用户交互次数大于1 000的物品集为高曝光组,小于1 000的物品集为低曝光组。本文将敏感属性分类器实现为多层感知器(MLPs),使用带有默认参数的Adam优化器。在对比不同的物品角度的采样方法时,不对敏感属性分类器做改动。
3.4 总体性能比较
表3总结了对比方法和MsFRS分别在用户角度公平性、推荐系统性能、物品角度公平性的性能对比。可以得到如下结论:

表3 不同方法在推荐准确率、用户角度公平性和物品角度公平性上的性能对比Table 3 Performance of different methods in recommendation accuracy, user fairness, and item fairness
1) MsFRS与对比方法相比,在性别、年龄和职业3种敏感属性的分类效率明显降低,说明基于对抗的用户角度公平性方法很好地消除了用户向量中的敏感属性信息,保证了用户角度的公平性。
2) 加入对抗正则化器后,用户公平性提高,推荐系统准确率下降,存在公平性和准确率之间的帕累托效应。
3) 基于曝光的负采样策略提高了推荐系统准确率,有效地解决了公平和效率之间的帕累托效应。
4) 基于曝光的负采样策略一定程度上解决了曝光偏差的问题,保证了物品角度公平性。
下面将从用户角度公平性、推荐系统准确率、物品角度公平性3个角度详细介绍MsFRS方法的实验结果。
3.4.1用户角度公平性分析
实验从性别、年龄、职业3个敏感属性进行分析。从实验结果来看,在没有加入对抗正则化器时,对于敏感属性的分类准确率较高,在性别属性上的预测AUC达到0.7,说明用户嵌入中的性别信息将会严重影响给用户的推荐建议。通过加入对抗正则化器之后,性别、年龄和职业分类准确率明显降低。图4是训练过程中不同方法在性别分类上的AUC的对比图,可以看出对敏感属性进行对抗学习之后,分类准确率下降,用户嵌入中的敏感属性信息减少,在使用用户嵌入为用户提供推荐意见时能够降低对敏感属性的依赖,从而达到提高用户角度公平性的目的。对于年龄和职业2个敏感属性,多角度推荐系统公平性方法中的负采样方法相比随机采样来说,分类器的准确率有略微的上升,如图5所示,猜测可能是目前的对抗方法只针对用户嵌入进行敏感属性的预测,而物品嵌入中其实也隐形存在着用户的敏感属性信息,所以不同的采样方法中改变了物品嵌入从而影响了敏感属性的预测准确率。

图4 不同方法在性别分类上的AUC对比图Fig.4 Comparison chart of AUC of different methods on gender classification

图5 不同方法在年龄分类上的F1对比图Fig.5 Comparison of F1 of different methods on age classification
3.4.2推荐系统准确率分析
在组合对抗[1]方法中存在明显的分类准确率提高,推荐性能下降的现象。在使用随机采样加入负样本之后,NDCG@10指标提高,如图6、图7所示,负样本增加了捕捉用户偏好的信息,提高了推荐系统性能。但是对于随机采样负样本来说存在曝光偏差的问题,随机采的负样本并不是真正意义上的负样本,没有与历史用户有数据的物品可能是用户不喜欢,也可能是物品并没有曝光给用户。基于曝光的负采样策略通过将样本分组为高曝光组和低曝光组来采样负样本,进一步考虑了曝光偏差对用户偏好的影响,从提高了推荐系统的准确率,达到用户公平性与推荐系统准确率的帕累托最优。

图6 不同方法在加入性别对抗的推荐准确率NDCG@10对比图Fig.6 Comparison of different methods in recommendation accuracy NDCG@10 with gender adversarial
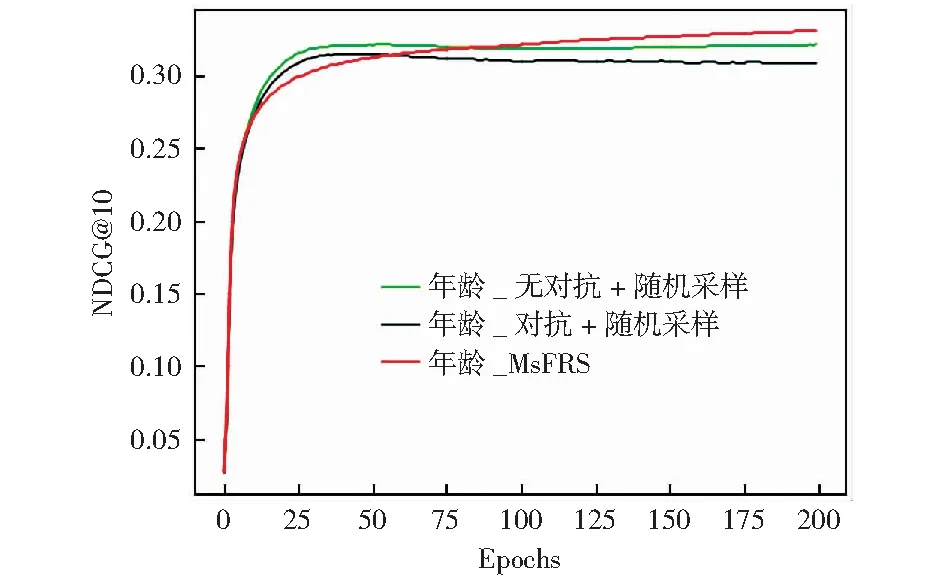
图7 不同方法加入年龄对抗的推荐准确率NDCG@10对比图Fig.7 Comparison of different methods in recommendation accuracy NDCG@10 with age adversarial
3.4.3物品角度公平性分析


图8 不同方法在物品角度公平性上性能分析Fig.8 Performance analysis of different methods in item fairness
3.5 参数分析
λ是一控制对抗正则化强度的超参数,本文最终选取1 000.图9为性别分类与不同超参数λ之间的权衡,随着λ值的增大,对抗正则化的强度增大,敏感属性性别分类AUC持续降低,说明对抗正则化器起到了消除敏感属性信息的作用,当λ为1 000时,AUC的值不再继续下降。图10显示推荐系统准确率与不同λ的权衡,可以看到随着对抗正则化强度的增大,推荐准确率在下降,在λ为1 000时有轻微的提高,随着λ值的提高,推荐系统准确率依旧持续下降,为了权衡用户公平性和推荐系统准确率,最终超参数λ选择取值1 000.

图9 性别分类AUC与不同λ的权衡Fig.9 Tradeoff of gender AUC versus different λ

图10 推荐系统准确率与不同λ的权衡Fig.10 Tradeoff of recommendation accuracy versus different λ
本文针对推荐系统中存在的用户公平和推荐准确率之间的帕累托问题提出了推荐系统多角度公平性方法。通过加入对抗正则化器提高了用户角度公平性,引入基于曝光的负采样策略提高了推荐系统准确率从而达到帕累托最优,基于曝光的负采样策略在一定程度上解决物品曝光偏差的问题,保证了物品角度的曝光公平性,从而达到推荐系统的用户和物品的多角度公平性。在真实的数据集上进行实验后,结果表明在用户角度公平性、推荐系统准确率、物品角度公平性3个评价指标上有很好的表现。但是目前的从帕累托视角解决推荐系统多角度公平性方法(MsFRS)还处于一种问题定义的探索阶段。在用户角度公平性方面使用基本的对抗方法来实现,生成的用户嵌入只需要欺骗对抗正则化器,因此它尚不能完全消除用户敏感属性的信息,这是将来可以改进的一个方向。除此之外,基于曝光的负采样模型也可以考虑使用更加复杂且有效的负采样模型。
猜你喜欢 公平性偏差准确率 50种认知性偏差商界评论(2022年1期)2022-04-13乳腺超声检查诊断乳腺肿瘤的特异度及准确率分析健康之家(2021年19期)2021-05-23多层螺旋CT技术诊断急性阑尾炎的效果及准确率分析健康之家(2021年19期)2021-05-23不同序列磁共振成像诊断脊柱损伤的临床准确率比较探讨医学食疗与健康(2021年27期)2021-05-13颈椎病患者使用X线平片和CT影像诊断的临床准确率比照观察健康体检与管理(2021年10期)2021-01-03如何走出文章立意偏差的误区学生天地(2020年6期)2020-08-25加固轰炸机数学大王·趣味逻辑(2019年10期)2019-11-06核心素养视阈下中小学课堂评价的公平性研究福建基础教育研究(2019年6期)2019-05-28真相草原(2018年2期)2018-03-02云环境下能耗感知的公平性提升资源调度策略计算机应用(2016年10期)2017-05-12






