基于改进YOLO,v3模型的多类交通标识检测
时间:2023-06-25 12:45:03 来源:雅意学习网 本文已影响 人 
张志佳,范莹莹,邵一鸣,赵永茂
(1.沈阳工业大学 人工智能学院,沈阳 110870;
2.沈阳市信息感知与边缘计算重点实验室,沈阳 110870;
3.沈阳美行科技有限公司,沈阳 110169)
自动驾驶汽车与辅助驾驶可以减轻驾驶员的精神负担,协助预防交通事故,将人从大量的驾车时间中解放出来.准确地从复杂的交通场景中检测交通标志、交通信号灯以及停止线对于实现自动驾驶及辅助驾驶的研发具有重要意义.
交通标识检测模型主要可分为基于颜色、形状等特征的传统目标检测模型和基于卷积神经网络的深度学习目标检测模型.传统目标检测模型[1-3]往往需要人工设计不同的特征来检测交通标识,虽然结合了颜色、亮度、形状等信息,但在复杂的背景环境中干扰物众多,检测速度慢,鲁棒性差.近年来随着智能计算的不断发展,基于卷积神经网络的目标检测模型也逐渐开始应用于交通标识检测研究[4-7].基于卷积神经网络的目标检测模型主要分为两个研究方向:二阶段目标检测和一阶段目标检测.
二阶段目标检测模型将目标检测任务分两步来完成.第一步对输入图像截取一定数量的候选区域送入卷积层提取特征;
第二步根据候选区域提取出的特征进行细分类与位置回归,得到最终的检测结果.二阶段目标检测模型主要代表网络有R-CNN系列模型、SPP-net等.一阶段目标检测模型将提取候选区域的步骤融合到特征提取中,仅对输入图像进行一次所有像素点的特征提取即可完成位置回归和分类任务.一阶段预测推理过程相对简单,实现了提速的目的,但也增加了检测难度,降低了检测精度.典型一阶段检测模型有单发多框检测器(SSD)及其改进模型、YOLO系列[8-10]检测模型等.Zhu等[11]提出了TT100K交通标志数据集,并利用二阶段目标检测模型实现了多类交通标识牌的检测.Meng等[12]采用改进的一阶段检测模型,结合图像金字塔模型实现对不同尺寸交通标识的检测.张淑芳等[13]针对现有目标检测方法仅适用于大尺寸、特定种类交通标志的检测,且对复杂交通场景图像检测效果不佳的问题,以抗退化性能较强的ResNet101为基础网络,增加若干卷积层构建残差单发多框检测器模型,对高分辨率交通图像实现了多尺度分块检测.
为了提高复杂交通场景中多类交通标识的检测精度,本文提出了基于YOLO v3目标检测模型的改进T-YOLO模型,在分析多类交通标识真实标注框的基础上,重新设计符合多类交通标识检测的先验框个数与尺寸比例,提升了多类交通标识等小目标检测的召回率.
T-YOLO模型采用Darknet-53作为特征提取结构,并且在该特征提取结构的末端加入数个卷积层和3个上采样层,进一步提取多类交通标识的特征.模型检测部分使用4种不同尺度的特征图进行待测交通标识定位任务,同时在检测层中,每个网格设有5种不同尺度的先验框来拟合待测交通标识.
1.1 YOLO v3模型
YOLO v3检测模型的结构如图1所示,其中第1列为模型层操作类型,第2、3列为卷积核尺寸,第4列为输出尺寸.输入图像经过带有跳跃连接层的Darknet-53卷积层提取特征后,分别在3种不同尺度特征图上进行边界框预测.在整个预测过程中,YOLO v3模型中首先将原图像分成一定数量的栅格;
其次,每个栅格预设3种不同比例的先验框,若待测目标的中心落入该栅格,则由该栅格的先验框负责预测目标位置及分类信息;
最后,通过非极大值抑制模型对上一步生成的大量预测框进行筛选,选取出最逼近待测目标真实位置的预测框,完成最后的边界框回归和分类任务.

图1 YOLO v3模型结构图
1.2 多尺度检测
在公开交通标识数据集中,图像尺度不尽相同,为使卷积网络更好地学习图像特征,在输入模型前都需要对图像进行预处理,将输入图像缩放到某个固定尺寸,本文采用608×608像元.而其中的交通标志、交通信号灯在原图像中已分属小目标,经过尺度调整后所占像元数更少.
在使用YOLO v3模型对交通标志检测时发现,使用32倍下采样获取的13×13像元特征图进行交通标识检测时,基本检测不到交通标识.这是由于下采样倍数高,特征图的感受野比较大,因此容易丢失信息,不适合检测图像中尺寸比较小的对象.
为解决上述问题,获得更多的细节信息用于检测多类交通标识,在原YOLO v3模型基础上增设第4种尺度的检测层.通过该方法将预先统计的先验知识加入到模型训练中,可使深度神经网络模型在训练学习过程中大大增强拟合性能,有助于提高模型的收敛速度.
在本文中,待检测的多类交通标识无论是按照像素数量还是所占全图的比例,均属于小目标检测.YOLO v3模型中先验框是基于COCO集分析获得的,该数据集图像待测目标有80余种,大中小目标繁杂.为更好地检测多类交通标识,本文对交通标识的真实框进行重新聚类与分析,设置交通标志的背景框长宽比为1,交通信号灯的背景框长宽比为0.3,停止线的背景框长宽比大于10.
除先验框形状与尺度外,预设的先验框个数对多类交通检测效果也存在较大影响.如图2所示,随着各检测层预设先验框的增加,TT100K与SUTDB数据集中背景框与预设框的平均交并比(Avg IOU)有明显提高.但是当检测层预设的先验框个数大于10时,Avg IOU涨势减缓.
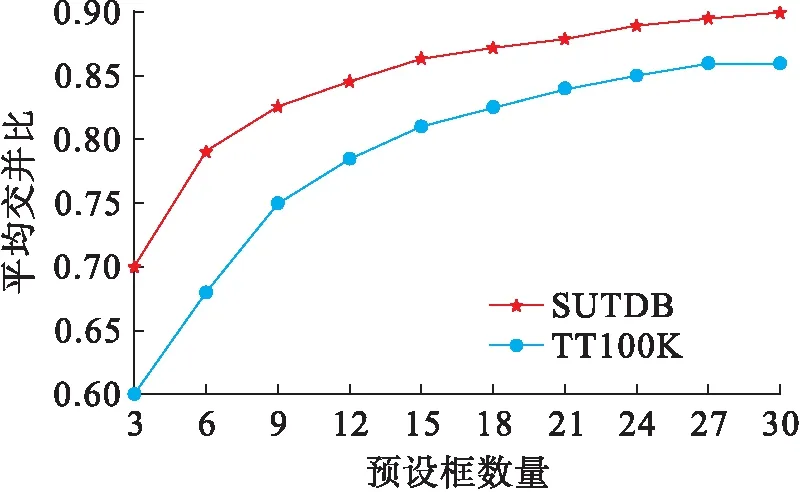
图2 TT100K与SUTDB数据集平均交并比与预设框数量关系
由于含有交通标识的清晰图像获取困难且标注过程需要耗费大量时间,导致目前交通标识公共数据集匮乏,故T-YOLO模型对多类交通标识检测实验在自制多类交通标识检测数据集SUTDB上完成.为证明该网络的泛化性和鲁棒性,也将在交通标志数据集TT100K、交通信号灯数据集LaRA上进行对比实验.
2.1 交通标志数据集
清华大学与腾讯共同推出的TT100K数据集,是清华学者基于10万个腾讯街景全景图创建的一个大型交通标志数据集,涵盖了不同角度和自然交通环境中的200多类交通标志.德国公开的交通标志检测数据集GTSDB涵盖了城市、高速公路与郊区,晴天与阴天,白天与傍晚等多种真实路况,是交通标识检测常用的公认数据集.本文采用TT100K数据集中6 105张图像作为训练集,3 071张图像作为测试集;
GTSDB数据集中600张图像作为训练集,300张图像作为测试集.
2.2 交通信号灯数据集
由于国内暂无公开交通信号灯数据集,所以本文采用LaRA数据集作为交通信号灯数据集.LaRA为巴黎交通信号灯数据集,由车载相机在自然场景下采集,是交通信号灯数常用公开数据集.本文选取3 487张图像作为训练集,1 246张图像作为测试集.
2.3 停止线数据集
不同于交通标志与交通信号灯等公开数据集,国内外有关于停止线的数据集较少,本文整理自制了停止线数据集.停止线数据集中图像主要来自于其他数据库,其中在TT100K数据集中挑选455幅带有停止线的图像,在GTSDB数据集中挑选358幅带有停止线的图像,自主采集326幅带有停止线的图像,共计生成1 139幅图像.其中训练集911张,测试集228张.
2.4 多类交通标识数据集
本文自主采集、标注制作了13 000幅的多类交通标识检测数据集.采集图像所用相机为维视图像MV-EM系列的彩色摄像机,搭配5百万像素工业镜头,将摄像机安装于支架上,并置于车顶,于辽宁省沈阳市市区与周边干道进行不同天气情况与不同时间的采集.将获得的图像使用LabelImg图像标注工具进行标注,标注类别为交通标志、交通信号灯以及停止线3类,其中训练集图像9 100张,测试集图像3 900张.
为验证T-YOLO模型检测性能,首先对交通标志、交通信号灯以及停止线在各自数据集中分别进行单项实验,然后在SUTDB数据集上进行多类交通标识检测的综合实验.软件环境:操作系统为Ubuntu16.04,深度学习框架Darknet;
硬件环境:CPU为Intel(R)Core(R)i7 8700,GPU为NVIDIA(R)GTX(R)2080TI,硬盘为2 TB.
3.1 交通标志实验
在交通标志数据集TT100K、GTSDB中对比了YOLO v3与T-YOLO模型的检测性能,结果如表1所示.由表1可知,利用两个数据集进行测试后,T-YOLO模型的召回率(R)和平均准确率(AP)均高于原始YOLO v3模型.将T-YOLO与其他应用于TT100K数据集的基于卷积神将网络的目标检测模型进行对比实验,结果如表2所示.与其他模型相比,T-YOLO模型对TT100K数据集检测的准确率与召回率更高.
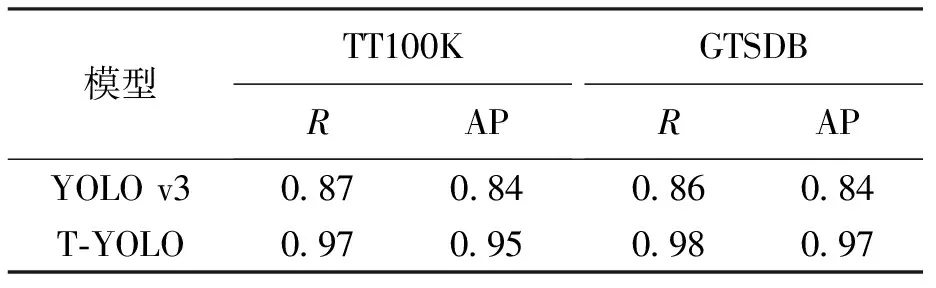
表1 T-YOLO与YOLO v3模型的性能对比

表2 T-YOLO模型在TT100K数据集上的横向对比
3.2 交通信号灯实验
为验证T-YOLO模型对交通信号灯的检测能力,使用T-YOLO模型与YOLO v3模型在LaRA数据集上进行实验,结果如表3所示.使用T-YOLO检测交通信号灯召回率高达99%,平均精度为98%,均高于原始YOLO v3模型.

表3 交通信号灯检测性能对比
3.3 停止线实验
为验证T-YOLO模型检测停止线的能力,使用T-YOLO模型与YOLO v3模型在自制停止线数据集上进行实验,结果如表4所示.T-YOLO模型的召回率和平均准确率较YOLO v3模型分别高出了11%和14%.
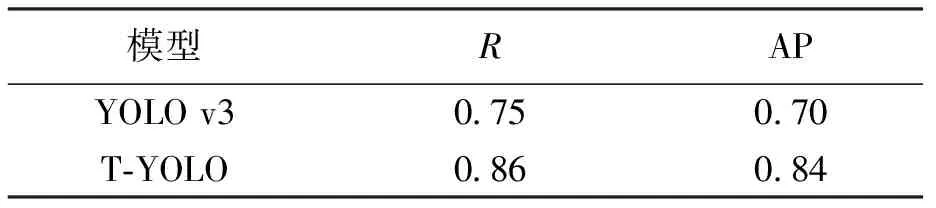
表4 T-YOLO与YOLO v3模型检测停止线的性能对比
3.4 多类交通标识检测实验
使用T-YOLO与YOLO v3模型检测多类交通标识,检测结果如表5所示.T-YOLO检测效果图如图3所示.

图3 T-YOLO模型检测结果图
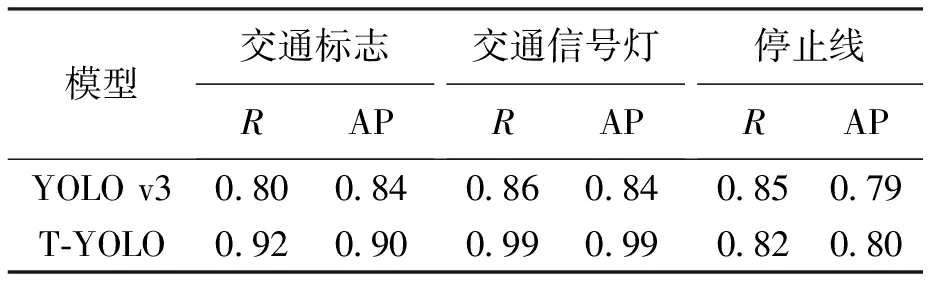
表5 T-YOLO与YOLO v3模型综合性能对比
提出的T-YOLO模型对于交通标志、交通信号灯以及停止线的召回率均有明显提升.本文提出的T-YOLO模型检测速率每秒可达31帧,高于图像模型检测交通标识的帧率要求.对模型检测结果分析发现,当交通信号灯及交通标志牌目标处在图像中的位置较远时,模型容易发生漏检情况,分析其原因是待测目标在当前图像中所占像素比例过小,最终导致的漏检.当出现地面停止线磨损不清晰、前车遮挡的情况时,由于待检测目标不够完整,导致停止线的检测效果也相对较差.综上分析,本检测模型在对常规多类交通标识检测效果良好,而对于像素比例占比较低或不完整的目标进行检测时,模型检测性能还有待提高.
针对YOLO v3模型检测多类交通标识召回率与平均精度低的问题,本文提出了一种适用于多类交通标识检测模型T-YOLO.该模型重新设计先验框的比例及数目,加入更大尺度的特征图进行边界框回归预测.在交通标志、交通信号灯、停止线与多类交通标识检测数据集上进行实验,本文设计的T-YOLO模型在复杂交通场景下,检测平均精度可达93%,具有一定工程实用性.
猜你喜欢交通标志信号灯卷积基于双向特征融合的交通标志识别汽车实用技术(2022年9期)2022-05-20基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02从滤波器理解卷积电子制作(2019年11期)2019-07-04交通信号灯小学科学(学生版)(2019年3期)2019-03-30信号灯为什么选这三个颜色?小天使·一年级语数英综合(2018年6期)2018-06-22基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20交通标志小课堂小天使·一年级语数英综合(2016年8期)2016-05-14安装在路面的交通信号灯华人时刊(2016年19期)2016-04-05交通信号灯控制系统设计山西大同大学学报(自然科学版)(2015年1期)2015-01-22我们欢迎你!小天使·一年级语数英综合(2014年7期)2014-06-26






