基于,MacBERT,和对抗训练的城市内涝信息识别方法
时间:2023-06-25 08:45:04 来源:雅意学习网 本文已影响 人 
方美丽 郑莹莹 陶坤旺 赵习枝 仇阿根 陆 文
1(江苏海洋大学海洋技术与测绘学院 连云港 222005)
2(中国科学院软件所 北京 100190)
3(中国测绘科学研究院 北京 100830)
目前,全球气候变暖,极端天气突发,由于强降水或连续性降水造成的城市内涝灾害,对人们的出行、交通造成了影响,严重时甚至会造成财产损失、危害人身安全。据有关资料统计,在我国 500 多个城市中,约有 62% 的地区经历过内涝,其中,出现内涝灾情 3 次以上的城市为137 个,积水连续时间>12 h 的城市为 57 个[1]。由此可见,城市内涝问题已经成为当前我国城市安全发展所面对的重大挑战。当灾害发生时,能够准确有效地从各大社交媒体中获取灾害的发生时间、空间位置、造成损失及灾害影响、致灾原因等信息,不仅有助于提高城市管理工作者的灾害应急响应能力,还能为灾害监测[2]和城市舆情分析[3]提供数据支持。
城市内涝信息识别过程即命名实体识别的过程,主要分为 3 种类型:基于规则与词典的方法、基于传统机器学习的方法和基于深度学习的方法[4]。其中,基于规则与词典的方法,主要是利用由语言学家基于数据集特征人工构建的特殊规范模板或特殊字典,完成特征实体识别[5]。但这种方法不仅需要大量的人力和时间,而且当实体类型不同时,须重新制定相应的规范,可移植性较差;
基于传统机器学习的方法,意在将命名实体识别归为序列标注问题[6],但该方法依附于特征模板的选取,泛化能力较差;
目前,基于深度学习的方法逐渐兴起,深度学习是由多层神经网络组成的机器学习算法[7],可有效提取特征并进行学习。
本文利用深度学习的方法对城市内涝信息进行识别,将原始数据集送入 MacBERT 预训练模型获得初始向量表示,再加入一些扰动生成对抗样本,然后依次输入双向长短期记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)[8]
和条件随机场(Conditional Random Field,CRF)[9]进行训练学习,最后在微博数据集和 1998 年人民日报数据集上测试该模型的性能。
2.1 基于规则与词典的方法
基于规则与词典的方法是手工编写、人为设定的规则。Wang 等[10]结合规则与本体理论,从Web 文档中提取灾害事件的时空和语义信息,探讨了事件在时空上的关系。霍娜等[11]基于规则匹配的方法,对 3 类灾难性追踪事件的相关文档进行信息提取,精确率均达 91% 以上,效果较好。将基于规则与词典的方法用于不同的领域时,由于不同领域内实体的规则不同,需要对规则进行改动,耗时耗力。当规则能较好地反映实体关系时,基于规则和词典的方法才较为方便。
2.2 基于传统机器学习的方法
目前,基于传统机器学习的方法主要有:支持向量机[12]、条件随机场(CRF)[13]、隐马尔可夫模型[14]等。基于传统机器学习的方法利用大规模语料进行学习,进而标注出模型,以发现特征。基于传统机器学习的方法进行语料的标注时不需要很多专业知识,且应用于其他领域时,可直接使用,无须再做很多烦琐的工作。Imran 等[15]通过朴素贝叶斯设计了一个信息消息检测系统,用于获取灾害属性信息,完成信息识别。梁春阳[16]基于条件随机场模型,识别灾害文本中包含的时空和灾损信息,精确率为 90.3%,识别效果良好。但基于传统机器学习的方法对语料库依赖较大,且评估命名实体识别系统的大规模通用语料库较少,实用性较差。
2.3 基于深度学习的方法
无论是基于规则和词典的方法还是基于传统机器学习的方法,都需要人工处理大量的数据,且基于规则与词典的方法相对于传统机器学习方法需要很多的领域知识和资源,深度学习中的神经网络则可以自动学习和提取特征。目前,命名实体识别中的深度学习方法主要包括卷积神经网络、循环神经网络等[17],还有经过一系列改良的长短期记忆网络(Long Short-Term Memory,LSTM)[18]、BiLSTM[19]等模型。Bengio 等[20]提出将神经网络语言模型用于训练参数奠定了深度学习模型在自然语言处理中的基础。Kumar 等[21]基于卷积神经网络模型,提取推特网上灾难事件及相关人员的地理位置,识别效果良好。Chanda[22]利用 BERT 模型,对 Twitter 数据使用不同类型的词嵌入以预测灾难,F1值为83.16%,表明该模型的识别效果良好。Liu 等[23]将信息提取过程视为序列标注任务,结合 BERT模型,从定制语料中提取台风灾害事件元素,有助于分析台风灾害的演化过程。刘淑涵等[24]利用卷积神经网络模型对北京特大暴雨灾害事件进行信息提取,精确度、召回率和F1值均高达 80%,表明该方法对灾害主题的识别准确性较高。王荩梓[25]基于 BiLSTM 与 CRF 模型提取上海市内涝灾害的地名信息,与条件随机场模型相比,该模型的F1值提高了 12%,地名实体识别效果显著。吴建华等[26]针对微博中的突发事件,采用 BiLSTM、CRF 模型和分类分层标注进行时空信息识别,进一步提高了时空信息识别的精度。黄中元[27]基于 BERT 预训练模型,使用序列标注方法为每个字预测标签,对输出结果进行约束,并结合实际应用需要进一步对抽取出的时间和地点进行推理分析,得到时间和地点的标准化表达,应用效果较好。
虽然上述方法取得了良好的效果,但仍存在问题。首先,BERT 预训练模型包含数以亿计的参数,受模型规模大、延迟时间长等影响,模型预训练的工作量较大。同时,BERT 在训练时引用掩码语言模型,但目前大多数下游任务进行微调时,数据集中没有掩码数据,导致训练前数据集和微调数据集不一致,从而影响微调效果。其次,相关实验研究证明,神经网络模型常常表现为局部不稳定,即使输入很小的扰动,也可能会在一定程度上误导模型,这种恶意扰动的输入即为对抗样本[28]。
本文利用 MacBERT 模型获取输入数据的向量表示,不仅可以减少预训练,而且可以不使用掩码标记,将掩码标记位置的词替换为一个近义词,然后让模型进行词语纠错。输入样本中由于没有掩码标记,将大大减少微调阶段的差异。此外,本文还通过对抗训练解决完善神经网络模型局部不稳定的问题。对抗训练是指在建立些许对抗样本的基础上,将其添加到原数据集中,以提高模型对对抗样本的鲁棒性,强化模型对输入扰动的鲁棒性,从而使其更有效运用于城市内涝信息识别任务。
3.1 相关概念
3.1.1 预训练模型
预训练模型是神经网络方法中不可或缺的内容,预训练模型能够从没有标记完全的文本信息中获得先验语义知识,从而促进下游任务的实施。2018 年,Devlin 等[29]提出了 BERT 预训练模型,其编码器利用双向 Transformer,实现了预训练的深度双向表示。BERT 模型采用掩码语言模型,可以任意掩蔽输入词的 15%。其中,直接被替换为[MASK]的占 80%,任意词被更换占 10%,剩下 10% 保留原始词。但目前大多下游任务进行微调时,数据集中没有掩码数据,导致预训练任务与下游微调任务不统一;
而 MacBERT 将[MASK]标记位置的词更换为另一个近义词,可缓减预训练与微调阶段的误差,从而获得词级信息。BERT 和 MacBERT 的掩码方式对比如表 1 所示。
由表 1 可知,输入文本“今天的风实在太大了,还赶上了暴雨”,BERT 是以字为粒度的掩码方法,如对于原属于一个词的“今日的风”中的部分字“风”,将其随机掩码并通过预测被掩码掉的字,学习到字粒度的语义表示。而MacBERT 则使用近义词代替[MASK],没有近义词的用随机词替换,学习词级别的语义表示,该方法更适用于城市内涝信息识别任务。因此,本文中输入文本的向量表示采用 MacBERT 模型获取。

表1 BERT 和 MacBERT 的掩码方式对比Table 1 Comparison between BERT’s and MacBERT’s mask methods
3.1.2 对抗训练
2015 年,Goodfellow 等[30]首次提出对抗训练的概念,通过不断向模型输入扰动,增强模型的鲁棒性。即向原始的输入样本 X 中加入些许扰动后得到对抗样本,然后将对抗样本放入模型中进行训练。Yasunaga 等[31]在 POS 任务中使用对抗训练,不但提升了整体标注的正确率,还增强了模型的鲁棒性。李静等[32]基于局部对抗训练方法,既减缓了边界样本混淆限制命名实体识别的问题,又降低了传统对抗训练中由于计算增加引起的对抗样本冗余,提高了命名实体识别效果。对抗训练的过程可以抽象为一个公式,如公式(1)所示。


3.1.3 双向长短期记忆网络模型
循环神经网络对于文本序列的历史信息拥有记忆保存的能力,常用于执行序列的标注任务[33]。但由于序列长度的不断增加,出现了长距离依赖、梯度消失或爆炸等问题。因此,Hochreiter等[34]提出了长短期记忆网络模型,有效地解决了循环神经网络的长距离依赖与梯度消失的问题。然而,需要进行文本分析的词不仅与上文有关,还与下文密不可分。因此,Graves 等[35]提出了BiLSTM 模型,该模型基于前向长短期记忆网络和后向长短期记忆网络两个方向,能够同时对文本的上下文信息进行分析,有效地解决了长短期记忆网络分析文本信息的单向问题。双向长短期记忆网络模型的网络结构如图 1 所示。
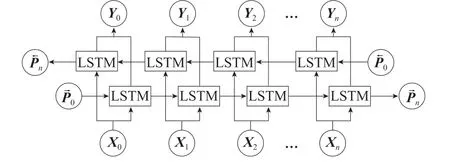
图1 双向长短期记忆网络模型结构图Fig. 1 BiLSTM model structure drawing

3.1.4 条件随机场模型

3.2 AT-MBC 方法流程


图2 AT-MBC 模型结构图Fig. 2 The AT-MBC model diagram

条件随机场常被标签解码层用以计算最有可能的命名实体类别,它通过学习一些规范以确保有效的最终预测结果,减少非法序列的出现。条件随机场的规范如下:(1)实体以“B-”开头,句子首字符以“B-”或“O”开始,实体或句首均不能以“I-”开始。(2)对于连续标签,如以“B-place”为首,后面的标签只能是“I-place”标签或“O”标签。
如在输入层中输入郑州市遭遇强降雨天气,在输出层就会输出郑/B-place 州/I-place 市/I-place遭/O 遇/O 强/B-attribute 降/I-attribute 雨/I-attribute天/O 气/O。
4.1 实验环境与数据
本文的实验硬件环境如表 2 所示。

表2 实验硬件环境Table 2 Experimental hardware environment
首先,本文基于网络爬虫技术,根据“内涝”“积水”“冲走”“水淹”等关键词及时间范围,获取相关的新浪微博内容,共收集整理了关于河南省郑州市 7 月 20 日内涝灾害事件的110 473 条文本数据。
然后,对原数据进行清洗去重、中文分词、去除停用词等工作。其中,清洗去重是将原数据中无用的信息去除,便于后期分析;
中文分词是将某个中文句子变换成词序列;
去除停用词是去除自然语言中频繁出现,但不一定代表句子实质语义的词[37],如“的”“地”“得”等,该工作可以提升模型的运算效率并降低错误率。
最后,结合对抗训练、MacBERT、BiLSTM和 CRF 模型,提取郑州市内涝事件的时间信息、地理位置信息和属性信息。其中,属性信息包含灾害产生的原因,造成房屋破坏、道路损毁、车辆损坏、人员伤亡、经济损失等影响。数据集采用 BIO 标注机制:B-time 表示时间在此段的开头,I-time 表示时间在此段的中间位置;
B-place 表示地名在此段的开头,I-place 表示地名在此段的中间位置;
B-attribute 表示属性在此段的开头,I-attribute 表示属性在此段的中间位置;
O 表示不是实体。时间信息、地理位置信息和属性信息部分数据如表 3 所示。

表3 部分数据Table 3 Part of data
将数据按照 7∶3 划分训练集和测试集,即在语料库中随机选取 14 331 条语句作为训练集,余下的 6 142 条为测试语料库,数据集整体情况如表 4 所示。

表4 语料数据统计Table 4 Corpus statistics
4.2 实验参数与评价标准
本实验使用 Google 发布的 MacBERT 预训练模型,模型参数如表 5 所示。本文利用精确率(Precision,P)、召回率(Recall,R)和综合值F1对模型效果进行评估,计算公式如下:

表5 MacBERT 模型参数Table 5 MacBERT model parameters

其中,TP为识别到正确实体的个数;
FP为识别到非实体的个数;
FN为未识别到正确实体的个数。
4.3 实验结果分析与讨论
本实验基于微博数据集对 AT-MBC 模型进行超参数敏感性和有效性分析:分别将训练样本批大小和正则化 Dropout 作为变量,探究模型对参数的敏感性;
选择另外 3 种信息识别模型与本实验改进模型 AT-MBC 对比分析,探究模型的有效性。
4.3.1 模型敏感性分析
批大小会影响模型的优化程度和速度,合适的批大小能够提高训练的速度,反之则会导致数据不收敛或运行内存不足。将模型批大小分别设置为 8、16、32、64、128 进行实验,实验结果如图 3 所示。当批大小为 32 时到达顶峰值,而召回率则达到低谷值。

图3 批大小对模型评价指标的影响Fig. 3 Effect of batch size on model evaluation index
正则化 Dropout 是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,可增强模型的泛化性。将 Dropout 值分别设置为 0.2、0.5 和 0.7 进行实验,实验结果如图 4 所示。当 Dropout 值为 0.5时,模型效果最好。

图4 Dropout 对模型评价指标的影响Fig. 4 Influence of Dropout on model evaluation index
4.3.2 模型有效性分析
为证实本文设计的 AT-MBC 模型的有效性,在同一训练集和测试集下,选取 BiLSTMCRF(BC)[38]、BERT-BiLSTM-CRF(BBC)[39]和MacBERT-BiLSTM-CRF(MBC)[40]共 3 种模型进行实验对比,表 6 为不同模型的内涝信息识别实验结果。

表6 实验结果Table 6 The experimental results
由表 6 可知,AT-MBC 模型的精确率为98.82%,召回率为 93.11%,F1值为 92.28%,信息识别状况表现良好。
BC 模型的精确率为 98.69%,召回率为91.55%,F1值为 92.00%。与 BC 模型相比,BBC 模型的精确率提升了 0.06%,召回率提升了1.27%,F1值提升了 0.19%。BC 模型的识别效果较差,是因为该模型的预训练过程是静态的,未考虑位置信息词的多层特性。当引入 BERT 预训练模型后,模型的精确率、召回率与F1值均有所提升,说明 BERT 预训练模型训练得到的向量具有更多、更好的文本特征,能较好地表征位置信息词的多义性。
BBC 模型的精确率为 98.75%,召回率为 92.82%,F1值为 92.19%。与 BBC 模型相比,MBC 模型的精确率提升了 0.02%,召回率提升了 0.52%。MBC 识别效果较好,是因为MacBERT 模型改进了 BERT 模型的预训练任务,将原本需要掩码标记位置的词替换为别的近义词,然后让模型进行词语纠错,使得输入样本中没有掩码标记。这样不仅减少了预训练,还大大降低了微调阶段的差异。
MBC 模型的精确率为 98.77%,召回率为93.34%,F1值为 92.11%。与 MBC 模型相比,AT-MBC 模型的精确率提升了 0.05%,F1值提升了 0.17%。AT-MBC 模型的识别效果较好,是因为对抗训练是直接在模型的向量表示上添加一些扰动生成对抗样本,而对抗样本会在一定程度上模拟数据集中的自然误差,使模型更能容忍模型参数波动带来的变化,从而增强了模型对对抗样本的鲁棒性。
综上所述,本文提出的 AT-MBC 模型信息识别方法的性能更优。
为更加直观地研究参数对于模型的敏感性和有效性,本文通过设置不同的迭代次数,以分析模型的精确率和F1值涨幅情况,如图 5、图 6所示。

图5 迭代次数对模型精确率的影响Fig. 5 Effect of iteration number on model accuracy
由图 5、图 6 可知,随着训练迭代次数增加,各个模型的指标曲线呈先增长后逐渐拟合并趋于稳定的趋势。其中,AT-MBC 模型精确率和F1值的增速较快,在第 10 次迭代时达到最大值,且相较于其他模型,该模型的效果最好。

图6 迭代次数对 F1 指标的影响Fig. 6 The influence of iteration times on F1 index
为再次证明本文方法的先进性,本文选用公开数据集(由北京大学标注的 1998 年《人民日报》语料)进行实验,并与部分现有方法进行实验对比,对比结果如表 7 所示。

表7 实验对比Table 7 The experimental contrast
如表 7 所示,杨贺羽等[41]通过双向长短期记忆网络和 FOFE 编码,对向量化表示的文本进行特征提取和编码表示,精确率高达 90.36%。金彦亮等[42]提出基于分层标注的实体抽取方法,F1值达到了 91.41%,有效地改善了中文嵌套命名实体识别的效果。蔡庆[43]利用 BERT 预训练结合深度神经网络和 CRF 模型,提升了实体识别的效果。而本文提出的 AT-MBC 模型的精确率、召回率和F1值均高于上述模型。因此,本文提出的 AT-MBC 模型具有更强的信息提取能力,可有效地应用于信息识别任务。
在本文提出的 AT-MBC 算法模型中,MacBERT 层减少了预训练次数和微调阶段差异,BiLSTM 层负责提取文本上下文语义特征,CRF 层负责生成最优标签序列,并通过对抗训练提高了该模型的鲁棒性,可有效实现城市内涝信息识别。由实验结果可知,本文提出的 AT-MBC算法的各种指标均较好,可为城市管理工作的信息识别分析研究提供参考。本文提出的识别方法还存在一定弊端,尤其是面对复杂地理位置信息和复杂属性信息时,需进一步完善信息识别方法。下个阶段可收集其他各大社交媒体网络网站上的复杂地理位置数据集与复杂属性数据集,对实验结果进行分析和深入研究,同时不断优化参数设置,以取得更好的识别效果。
猜你喜欢掩码内涝实体前海自贸区:金融服务实体中国外汇(2019年18期)2019-11-25低面积复杂度AES低熵掩码方案的研究通信学报(2019年5期)2019-06-11基于布尔异或掩码转算术加法掩码的安全设计*通信技术(2018年3期)2018-03-21实体的可感部分与实体——兼论亚里士多德分析实体的两种模式哲学评论(2017年1期)2017-07-31两会进行时:紧扣实体经济“钉钉子”领导决策信息(2017年9期)2017-05-04振兴实体经济地方如何“钉钉子”领导决策信息(2017年9期)2017-05-04国外应对城市内涝的智慧:从“驯服”到“巧用”公民与法治(2016年16期)2016-05-17基于掩码的区域增长相位解缠方法浙江大学学报(工学版)(2015年4期)2015-03-01基于掩码的AES算法抗二阶DPA攻击方法研究电子设计工程(2015年20期)2015-01-29城市内涝的形成与预防河南科技(2014年1期)2014-02-27








