基于数据特征的电力数据隐私保护模型研究
时间:2023-06-22 17:05:04 来源:雅意学习网 本文已影响 人 
张岚, 王献军, 程勇
(1.国网河南省电力公司营销服务中心,河南 郑州 456000;
2.国网陕西省电力公司,陕西 西安 710000)
电力的数据安全是智能电网建设和运行过程中电网隐私保护的重要内容。保障智能电力数据传输安全,需对数据传输过程中隐私泄露风险实行防御,保证数据传输过程中的机密性、传输后的完整性,避免数据发生缺失和泄露问题,保护智能电网数据隐私安全[1-3]。
当下智能电表隐私保护和用电数据隐私保护是两种应用较为普遍的隐私保护方法,其中用户对前者的应用满意度较低,后者则是当下重点研究和应用的方法。针对提升数据隐私保护的效果,陈智雨和陈思光等人,各自通过量子密钥[4]和多级云雾理论[5],设计保护模型完成电力数据隐私保护。但是由于这些模型不具备数据属性特征选取,无法根据数据属性特征判断数据的重要程度,因此,无法完成数据筛选,统一完成数据加密导致模型完成数据通信的开销较大,同时数据中无需加密的数据也被加密后,增加数据的处理步骤。为此,本文研究基于数据特征的电力数据隐私保护模型,采用基于最大信息系数分类模型,完成电力数据属性特征分类,依据数据属性特征,通过差分隐私的数据匿名隐私保护模型完成隐私保护。
1.1 基于最大信息系数的特征分类模型
最大信息系数特征分类模型(feature classification model based on maximum information coefficient, MICFC)主要用于原始数据集的分类。将4种隐私级别依次分别命名为1~4级,以隐私级别为基础确定特征集,在1级和3级数据属性中选取。剩余数据属性为候选集,采用最大信息系数(MIC)对特征集和候选集实行处理,获取两者关联性较高的特征数据,用数据集表示,并作输出[6]。为保证数据的高效处理,仅对隐私属性实行保护。模型的流程见图1。

初始变量用求解获取的最大MIC值表示为:

图1 基于最大信息系数的数据属性特征分类流程
(1)
式中:K为空集。

(2)
式中:p为设定的特征数量。输出条件为获取的特征数量满足p,该获取过程通过贪心算法完成,且输出结果为H,并包含选定变量[7-9]。
1.2 基于差分隐私的数据匿名隐私保护模型
1.2.1 模型相关定义

图2 保护模型
本文保护模型从两方面完成数据隐私保护,分别为数据集隐私泄露和过程隐私泄露,结合两方面的保护设计数据隐私保护模型[10],见图2。
模型主要由两个部分完成数据隐私保护。第一部分是实行数据的微聚集k-划分,其采用平均矢量的最大距离(maximum distance to average vector, MDAV)算法完成,该部分主要目的是确定数据集中心点,并采用属于数据集的众值表示;
以该数据点为参照,选取距离其最远的距离为起点实行划分处理,形成等价类,每个等价类中包含元组的数量为K;
对该类实行定位后,将类中的敏感特征属性用其替代。第二部分为隐私保护,且通过差分隐私技术完成。对差分隐私实行定义:设有随机算法M,其输出构成的全部可能的集合用PM表示;
σM表示其任意子集;D和D′均表示近数据集,且两者间相差的记录不可超过1条。当M符合式(3)时,则表示M可完成ε-差分隐私保护。
PrM(D)∈SM≤exp(ε)×Pr[M(D′)∈SM]
(3)
式中:Pr·为隐私泄露的风险,由M控制;
ε为隐私保护预算,其可体现隐私保护的程度,且该保护仅由M提供。
加入噪声,是完成差分保护的基础,选取拉普拉斯噪声机制,0和b均为该机制的参数,前者属于标记位置,后者属于尺度,该机制分布用Lap(b)表示,则其密度函数计算公式为:
p(x)=b/2exp(-x/b)
(4)
1.2.2 模型实现
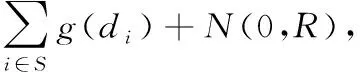
(5)

基于上述内容可发现,算法具备差分隐私保护,可较大程度提升匿名数据集的安全性,算法的详细步骤如下所述:
输入:数据集H。
输出:隐私保护匿名数据集。
(1) 求解相异度矩阵A,且属于同质性测度,并位于类中,n为元组数量。
(2) 求解数据集中心a,且依据A完成,确定与其距离最远的点r,并用其描述max{d(a,b)}中的b点,以r为基准,确定距离其最远的点s,并用其描述max{d(b,c)中}的c点。其中,距离计算公式为:
(6)
式中:X、Y为向量;
Xi、Yi为第i个特征属性。
(3) 分别以r和s为中心,确定分别距离两者距离最近的点,且数量为k-1,将其组成等价类。
(4) 如果n>2k,返回(1); (7) (6) 求解类质心,将其代替其他值: (8) (7) 输出H′实现整个数据集的差分隐私保护。 选取某电力公司某地区的智能电网6个月的用电数据集,并将Adult数据集加入其中,将结合后的数据集作为测试对象。 图3 参数测试结果 不同ε取值下的损失率结果见图3。分析图3测试结果可得:数据的输出损失率在ε取值不断增加的情况下呈不断降低趋势。其取值在<0.03时,损失率均在9%以上; 模型性能测试包含两个方面,分别是数据属性特征选取性能和微聚集性能测试。前者通过保留的数据属性特征数量和均方根误差衡量,后者通过F-Measure(综合评价指标)衡量,测试结果分别见表1和图4。分析图4测试结果可得:当ε取值在0.04~0.1时,随着该取值的增加,保留的数据属性特征数量逐渐增加,均方根误差则逐渐减小,并且F-Measure的取值也随着ε取值的增加而增加,该结果与图3的测试结果相符合,表明本文模型在运算过程中,具备良好的运算性能。 表1 数据属性特征选取性能测试结果 图4 模型微聚集性能测试结果 为分析本文模型对于发布数据的隐私保护的私密性,采用引入记录连接(record linkages, RL)作为衡量标准,判断本文模型的隐私性。RL是指模型从匿名数据集中完成原始数据匹配的正确率,将文献[4]和文献[5]的基于量子密钥和基于雾计算的保护模型作为文本模型的对比模型,用于完成相关测试,直观衡量文本模型的优劣。采用式(9)获取三种模型的RL结果,该测试在两种条件下完成,分别为不同属性数量下和不同数据量大小下,结果见图5。分析图5测试结果可得:不同属性数量下和不同数据量大小下,三种模型的RL结果整体均呈现上升趋势,但是文本模型的RL结果明显低于两种对比模型,分别在0.23和0.20以下,两种对比模型均在0.25以上。因此,应用本文模型保护后,数据的隐私性更高。 图5 三种模型的隐私性对比结果 为避免发生隐私泄露和数据缺失,保护智能电网数据隐私安全,本文结合智能电力数据属性特征,设计了基于数据特征的电力数据隐私保护模型。测试结果表明:该模型在合理的隐私保护预算范围内,运算性能良好,保护后数据RL值低于0.23,可较大程度保证数据的隐私性和可用性,降低数据损失率,应用性较好。由此可知,本文在避免发生隐私泄露和数据缺失、保护智能电网数据隐私安全方面有着较大的优势和应用前景。
如果k
2.1 参数确定

当该取值>0.04以后,损失率显著降低,低于5%,并且该取值越接近0.1则损失率越接近0。结合期望标准,则确定ε取值范围为0.04~0.1,并用于后续试验中。2.2 模型性能测试


2.3 模型的隐私性测试










