基于自适应尺度边缘特征的建筑施工图重叠字符识别方法研究
时间:2023-06-05 15:45:25 来源:雅意学习网 本文已影响 人 
王 正,邓雪原,2
基于自适应尺度边缘特征的建筑施工图重叠字符识别方法研究
王 正1,邓雪原1,2
(1. 上海交通大学船舶海洋与建筑工程学院,上海 200240;
2. 上海市公共建筑和基础设施数字化运维重点实验室,上海 200240)
目前非重叠字符的识别技术已趋于完善,但难以识别建筑工程图纸标注等场景中的重叠字符,阻碍了基于二维扫描图纸的自动建模技术的突破。针对传统字符识别方法无法识别重叠字符的现状,提出了一套基于自适应尺度边缘特征的建筑施工图重叠字符识别新方法。基于像素空间分布特征初步确定重叠字符区域,定义并提取字符的自适应尺度边缘特征;
借助双变量匹配概率函数筛选“位置+内容”的结果组合,并以全局最优原则代替绝对阈值作为识别标准,最终输出正确的识别结果。不同于先修复后识别的常规思路,该方法将特征匹配与干扰过滤相结合、字符定位与字符识别相关联,能解决百度等成熟商用OCR无法解决的重叠字符识别问题,且经数据实验证实具备较高的识别准确率。
重叠字符;
字符识别;
自适应尺度;
分布概率;
投影分割
随着我国建筑行业信息化[1]和智慧城市建设的不断推进,建筑信息模型(building information modeling,BIM)技术已越发广泛应用于建筑行业设计、施工、运维的全过程。BIM技术目前在运维阶段的主要问题是大量既有建筑缺乏准确、规范的BIM,需要根据工程蓝图人工建模。为节省建模成本,ZHAO等[2]提出从工程图纸图像上识别图形及标注,实现既有建筑快速、准确地自动化建模,但工程蓝图中普遍存在的标注字符重叠问题,其严重影响识别准确率。因此,如何有效解决重叠字符的识别问题成为BIM技术在运维阶段应用的重要一环。图1为工程标注中重叠字符的举例。

图1 含有重叠字符的工程标注图像
光学字符识别由字符检测和字符识别2个核心任务组成,主要包含预处理、分割、特征提取和识别4个步骤。重叠导致的信息缺失给特征提取和匹配造成困难,导致传统OCR方法无法识别重叠光学字符(简称重叠字符);
机器学习在处理高维图像时具备明显优势,但用于识别重叠字符等特征简单图像并不经济。
重叠字符识别需要从根本上解决信息缺失的问题。本文通过改进字符识别的流程,实现了无需预先确定匹配区域的字符识别,为图像识别提供了新的思路;
用C++语言编写测试程序,证明该方法具备可行性且具有较高的识别准确率。
重叠字符识别方面,CAO和TAN[3]根据图线长度分离图线和字符,而后识别其中的字符,平均识别准确率达到82.2%,但只适用于被简单线条干扰的字符;
CHAME和KUMAR[4]借助颜色阈值检测重叠边界,使用支持向量机(support vector machine,SVM)分类器区分字符,重叠字符的识别率可达93%,但需要字符的颜色各异。
在重叠手写体识别领域,LIANG等[5]提出一种基于过分割的识别方法;
WAN等[6]采用笔划级别评估与字符级别评估相结合的合并策略;
LV等[7]基于笔划序列的路径搜索;
LIANG等[8]后续又开展了几何特征降维、候选模式精简以及识别方法的改进研究。但手写体的重叠区域占比小,笔划特征易于简单,其研究方法对重叠字符的识别并不适用。
目前国内识别干扰字符的思路是先修复后识别。肖坚[9]根据亮度差异识别并去除干扰区域;
段荧等[10-11]依据笔画的宽度特征修复干扰字符。此类识别方法要求干扰与字符特征区别明显,且不具备重叠字符识别条件。
重叠字符识别的关键是如何有效弥补信息的缺失。图2(a)为传统识别流程,红色箭头表示无法适用于重叠字符的环节,位置信息和尺寸信息的缺失阻碍了特征提取区域和尺度的判定;
图2(b)为本文方法的识别流程:改进的行切分获取字符高度和自适应尺度,同时提取同一行所有字符特征;
根据空间分布概率筛选匹配结果,即可求出该行内的字符种类、个数及顺序。
为数字化、规范化描述,图像像素的位置表示默认采用像素坐标系,即以图像左上角为原点建立的以像素为单位的坐标系-,像素的横坐标与纵坐标分别是图像中该像素所在的列数与行数。图1的像素坐标系如图3所示,图像宽为像素,高为像素。
2.1 改进的行切分
本研究的目的是找到适合重叠字符改进的行切分方法(如图4中区域2),为自适应尺度和特征提取区域选择创造条件。
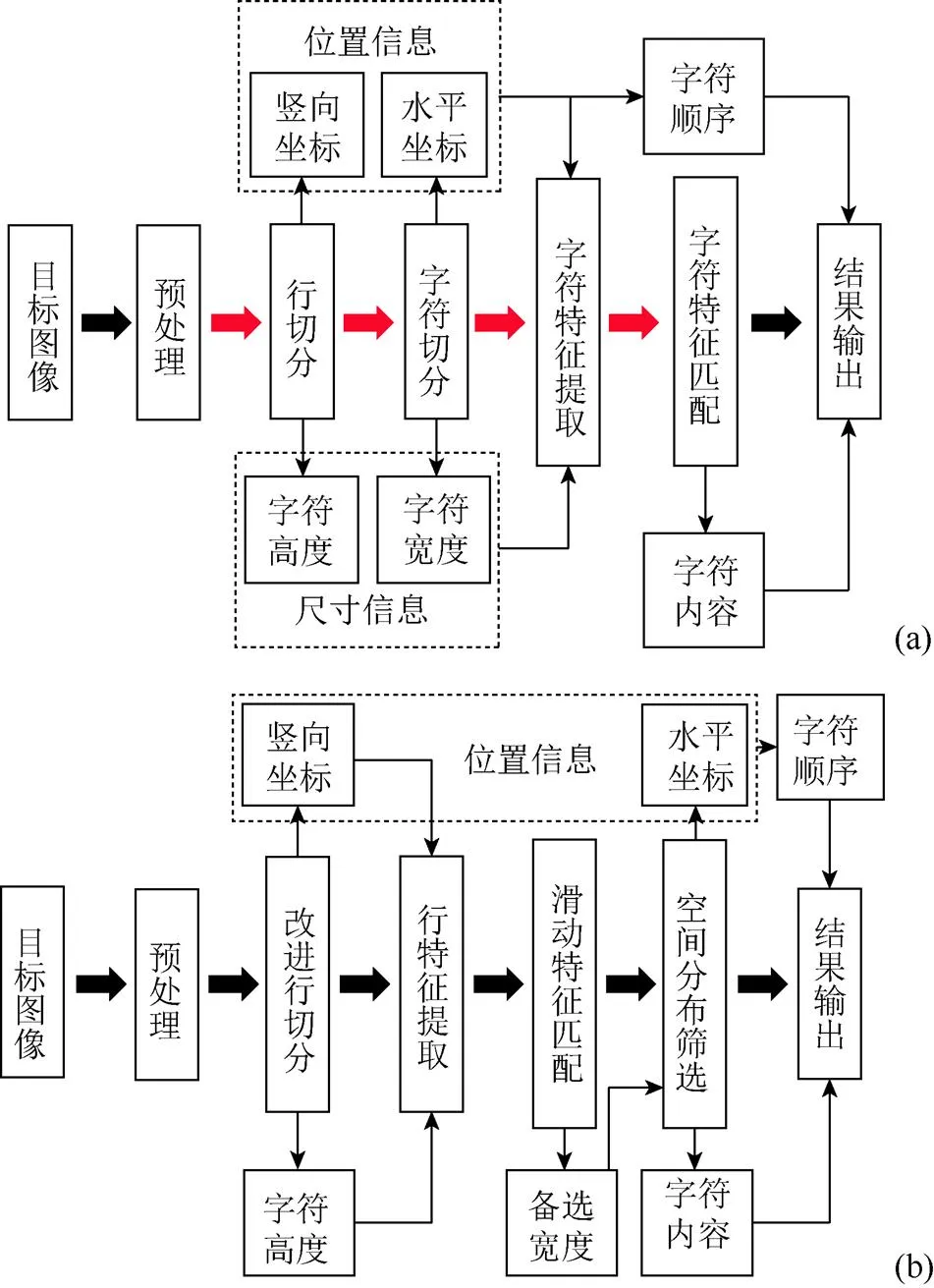
图2 识别流程对比((a)传统识别流程;
(b)本文识别流程)

图3 像素坐标系示例

图4 精确行切分示意图
传统字符识别中列分割通常采用水平投影的方法。定义(,)为二值化图像(,)处像素的灰度值(0或255),分别取1和0作为图像中黑白像素的代表值,即


式(2)统计了各像素行黑色像素的个数,其中1为水平投影值。图5是图1的水平投影统计图,由图5可以看出,传统方法的水平投影法在重叠字符行切分时并不适用。

图5 水平投影统计图
在水平投影基础上补充考虑像素的垂直分布特征。首先对图像做垂直投影,得到

其中,为各像素列黑色像素的个数。
然后在式(1)的基础上引入–2,用2重新表示图像中的像素,即
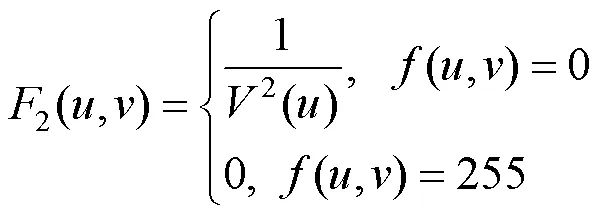
其中,–2可使所在列黑色像素少的区域2值更大,而这些区域均处于目标区域。
对每一像素行中的垂直投影的像素表示值2进行逐行求和,得到改进后的水平投影值为

图6是图1改进的水平投影统计图。相较于图5,图6中区域边界更加清晰。改进行切分的成果如图7所示完整准确。该方法综合考虑图像在水平和垂直方向的像素分布特征,求得的重叠字符真实高度确保了自适应尺度的有效性。事实上,改进前的水平投影可以看作式(4)中恒取1时的特殊情况。
2.2 自适应尺度的边缘特征提取
找到具有较强表示能力且易于提取的特征是图像识别的关键。当前图像识别中常用的几类图像特征见表1。

图6 改进后的水平投影统计图

图7 图像切分结果

表1 常用于识别的图像特征
重叠字符的干扰区域面积占比高,颜色无明显边界,代数、区域等特征并不适用。图像边缘是图像区域属性突变处,不同于灰度属性的区域之间的灰度分割线。尽管重叠字符边缘存在一定干扰,但可较好保留原有的边缘特征(图8实线)。二值化图像边缘明确且易于提取,所以选取边缘作为识别特征。
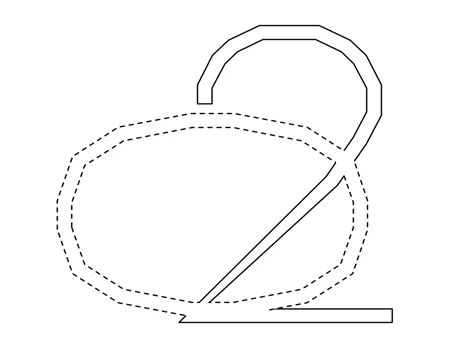
图8 重叠字符边缘特征
提取得到的像素坐标数据多、利用难,且像素尺度不易反映宏观特征,于是基于改进的行切分方法,在自适应尺度下提取特征线段表示边缘特征。
若行切分图像的高度为像素,做+1条等距水平辅助线将图像分为个区域,2条相邻平行线间距为/,可称其为特征描述的尺度。将辅助线穿过的边缘像素作为特征点,沿边缘路径每2个相邻特征点确定一条特征线段,图像的边缘特征可简化为若干个成对的端点坐标。图9展示了尺度为/9时特征点和特征线段。
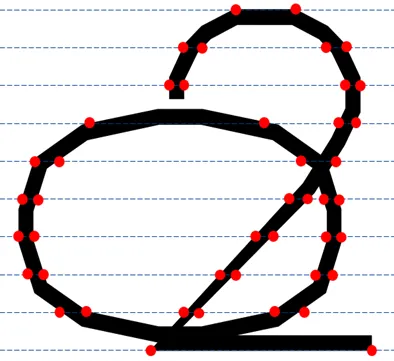
图9 尺度为h/9时特征示意图((a)特征点示意图;
(b)特征线段示意图)
为避免特征遗漏,通常取30~60之间,再结合即可确定特征提取时特征点的坐标。
尺度选取合理的前提是准确地切分,本文方法在自适应尺度选取过程中引入了改进的行切分方法,相比传统方法更易获取最合理的特征尺度。
2.3 基于空间分布概率的匹配与筛选
传统方法的匹配是基于字符切分,为多个比对字符图像和一个未知字符图像的匹配;
重叠字符无法实现字符切分,需要引入空间分布变量,多个比对图像和同一行中所有字符同时匹配。
将行切分图像(图7)作为目标图像0,宽度为0像素,高度为0像素;
将37个无重叠字符(10个数字,序号为1~10;
26个大写英文字母,序号为11~36;
1个连字符“–”,序号为37;
如图10所示)作为比对图像P(=1,2,···,37),等比例缩放至高为0像素,宽度为w像素(w<0)。

图10 比对图像示例
分别建立0和P的像素坐标系如图11所示,并得到相同自适应尺度下边缘特征。图中箭头指向图像区域的特征线段,红色线段为匹配的特征线段。线段匹配的定义如下:若0中某条特征线段1的端点为(1,1)和(1ʹ,2ʹ),P(=1,2,···,37)存在特征线段2,其端点(2,2)和(2¢,2¢)满足
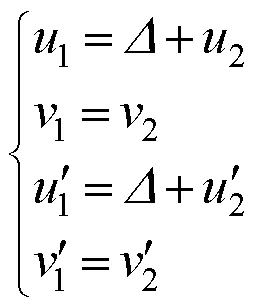
则称1为0在=处与P(=1,2,···,37)匹配的一条特征线段。

图11 匹配示例
0在=处与P的分布概率函数为

其中,为比对图像序号,=1,2,···,37;
为空间分布变量,表示0中匹配区域左边界的横坐标,取整数且0≤≤0–w;
M为P的特征线段总数;
为0在=处与P匹配的特征线段数。
分布概率的匹配方法较传统方法额外考虑了字符的空间位置,表示目标图像的不同位置与比对图像匹配的可能性。考虑到缩放对图像边缘的影响,匹配时可将判定线段匹配的条件适度放宽,在式(6)中用约等号代替等号进行线段匹配的判定。图12为比对字符“3”在0各处的分布概率,其中有2处位置概率较高。

图12 P0中“3”的分布概率
自适应尺度下分布概率较高即作为备选,汇总如图13所示,不同字符的分布概率用颜色区分。

图13 分布概率汇总
重叠字符概率数值低,所以不能仅凭概率数值选取结果,需做进一步筛选。
筛选逐轮进行。每轮在未经筛选的备选结果中选出最大的一组,若其在0的匹配区域与已通过筛选的区域存在交集,则放弃该组;
若不存在交集,则通过筛选。表2记录了图13中所有备选结果的筛选过程。
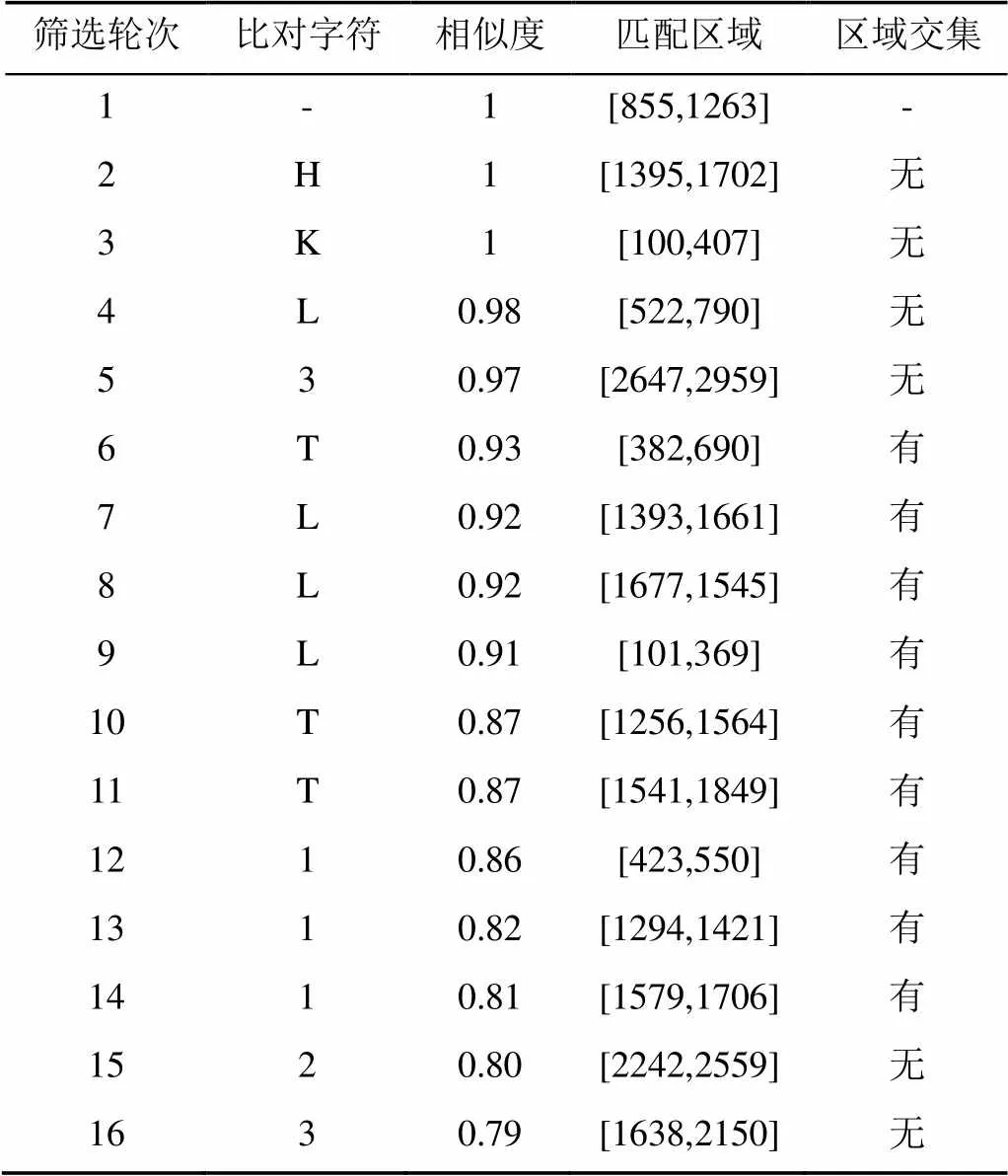
表2 识别结果筛选过程
经过16轮,第1~5,15~16轮中的“-” “H” “K” “L” “3” “3” “2”7个比对字符依次通过筛选。根据其各自区域位置确定字符顺序,输出结果“KL-H323”。
基于概率分布对整行所有字符同时进行匹配,其充分利用空间关系,无需字符切分也能实现字符识别。尽管该方法旨在解决重叠字符的识别问题,但对同一行中非重叠字符的识别同样适用,故识别时无需预先区分字符是否存在重叠。
3.1 样本图集
样本图集包含56张样本图,根据字符行列数分为1×1,1×2,2×1,2×2,2×3,3×2和3×3的7类,每类各8张图像。图像每行/列均含字符6~10个不等,内容均为随机产生。图集中待识别字符共900个,其中有重叠字符443个,无重叠字符457个。图14为3×3样本图中的一张,其中25个横排字符(无重叠字符10个,有重叠字符15个)为待识别的字符,其他均视为干扰。

图14 样本图示例
3.2 实验环境
实验采用Intel(R) Core(TM) i9-10900K处理器,128 G内存以及NVIDIA GeForce RTX 3090显卡的硬件配置,在Windows 10操作系统上运行整个实验过程,选择C++为编程语言并搭配OpenCV库实现程序编写。
3.3 初始实验结果
初始实验结果见表3。其中:56张图片全部实现正确行切分;
无重叠字符识别率为100%,重叠字符平均识别率为90.52%。重叠字符识别率不高,需做出改进。

表3 初始实验结果(%)
3.4 方法改进
实验中错误识别包括3类:
错误1:受干扰“H”识别为“L” “1”和“E”等字符,如图15(a)所示。
错误2:“D”的右半部分受到重叠干扰被错误识别为“L”,如图15(b)所示。
错误3:图15(c)中“E”识别成“P”,为重叠造成干扰过大的偶然情况,不易修正。

错误1和2均由于相似度计算时以比对图像的特征线段数作为分母,使“L”等特征线段少的字符更易取得较大的相似度。
在原方法基础上做出以下改进:当最终识别结果为“L” “T”和“1”时,补充计算该处与“H”和“D”的相似度,当大于80%时判定为“H”或“D”。
改进后再次实验,结果见表4。改进前后对比发现2类系统性错误得到有效修正,识别率大幅提高,重叠字符平均识别率提升至97.74%,证明该法能较好实现重叠字符的识别。
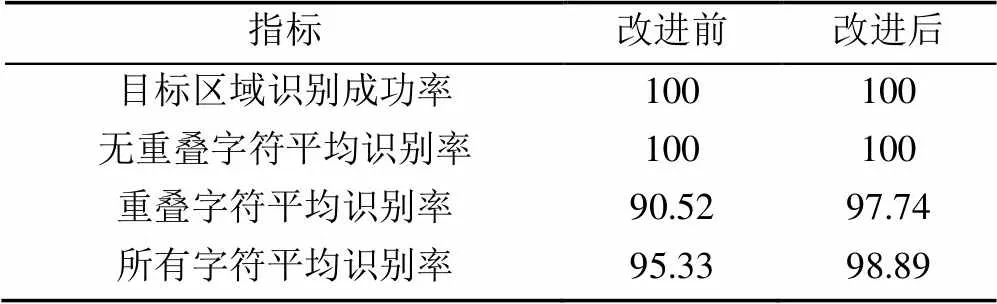
表4 改进前后结果对比(%)
图16对比了本文方法与已有OCR产品的识别效果。图16(b)和(c)分别是本文识别方法和调用百度api“通用文字识别(高精度位置版)”的结果。百度OCR共识别出4部分,分别为“/” “5R6” “40Y8”和“(”,效果不佳。图16(d)为百度OCR软件排行榜中表现最好的2款软件,其测试结果如图16(e)和(f)所示,可以看出成熟的OCR产品也无法准确识别重叠字符。这证明了该方法在重叠字符识别问题上的创新性和先进性。

图16 已有产品与本文方法对比((a)测试图;
(b)本文方法识别结果;
(c)百度高精度含位置版通用文字识别结果;
(d)市面常用的几款OCR软件;
(e)转易侠扫描王识别结果;
(f)闪电OCR识别结果)
从建筑工程图纸中的字符重叠问题出发,提出一套基于自适应尺度边缘特征的重叠字符识别方法。该方法不同于先修复后识别、先定位后识别的常规思路,基于改进投影、自适应尺度边缘特征、分布概率函数等新概念,将干扰过滤与特征匹配相结合、字符定位与字符识别相关联,无需确定干扰区域即可实现重叠字符的识别。不仅解决了商用OCR尚未解决的技术难题,也为局部数据缺失的复杂重叠图像识别(如口罩或眼镜遮挡下的人脸识别等实际场景)提供了新思路。然而,该方法主要针对简单字符的重叠识别,是否适用于重叠汉字或重叠复杂图像的识别尚需进一步研究。
[1] 国务院. 国务院关于印发“十三五”国家信息化规划的通知[J]. 中华人民共和国国务院公报, 2017(2): 35-68.
State Council of the People’s Republic of China. Circular of the State Council on printing and distributing the “Thirteenth Five-Year” national informatization plan[J]. Gazette of the State Council of the People’s Republic of China, 2017(2): 35-68 (in Chinese).
[2] ZHAO Y F, DENG X Y, LAI H H. Reconstructing BIM from 2D structural drawings for existing buildings[J]. Automation in Construction, 2021, 128: 103750.
[3] CAO R N, TAN C L. Separation of overlapping text from graphics[C]//The 6th International Conference on Document Analysis and Recognition. New York: IEEE Press, 2001: 44-48.
[4] CHAME S D, KUMAR A. Overlapped character recognition: an innovative approach[C]//2016 IEEE 6th International Conference on Advanced Computing. New York: IEEE Press, 2016: 464-469.
[5] LIANG J J, ZHU B L, KUMAGAI T, et al. Character-position-free on-line handwritten Japanese text recognition by two segmentation methods[J]. IEICE Transactions on Information and Systems, 2016, E99.D(4): 1172-1181.
[6] WAN X, LIU C S, ZOU Y M. On-line Chinese character recognition system for overlapping samples[C]//2011 International Conference on Document Analysis and Recognition. New York: IEEE Press, 2011: 799-803.
[7] LV Y F, HUANG L L, WANG D H, et al. Learning-based candidate segmentation scoring for real-time recognition of online overlaid Chinese handwriting[C]//2013 12th International Conference on Document Analysis and Recognition. New York: IEEE Press, 2013: 74-78.
[8] LIANG J J, NGUYEN C T, ZHU B L, et al. An online overlaid handwritten Japanese text recognition system for small tablet[J]. Pattern Analysis and Applications, 2019, 22(1): 233-241.
[9] 肖坚. 基于学习的OCR字符识别[J]. 计算机时代, 2018(7): 48-51.
XIAO J. OCR character recognition based on Learning[J]. Computer Era, 2018(7): 48-51 (in Chinese).
[10] 段荧, 龙华, 瞿于荃. 中文文字图片同色长干扰线的去除算法[J]. 数据通信, 2021(4): 42-46.
DUAN Y, LONG H, QU Y Q. An algorithm for removing long interference lines with the same color in Chinese text images[J]. Data Communications, 2021(4): 42-46 (in Chinese).
[11] 段荧, 龙华, 瞿于荃, 等. 文字图像不规则干扰修复算法研究[J]. 小型微型计算机系统, 2021, 42(7): 1427-1434.
DUAN Y, LONG H, QU Y Q, et al. Irregular interference inpainting algorithm research on text image[J]. Journal of Chinese Computer Systems, 2021, 42(7): 1427-1434 (in Chinese).
Research on recognition method of overlapped characters in construction drawings based on adaptive scale edge feature
WANG Zheng1, DENG Xue-yuan1,2
(1. School of Naval Architecture, Ocean & Civil Engineering, Shanghai Jiao Tong University, Shanghai 200240, China; 2. Shanghai Key Laboratory for Digital Maintenance of Buildings and Infrastructure, Shanghai 200240, China)
At present, the recognition technology of non-overlapped characters has been perfected, but it remains difficult to solve the recognition problem of common overlapped characters in scenarios such as the annotation of architectural engineering drawings, which hinders the breakthrough of automatic modeling technology based on 2D scanned drawings. To address the incapability of traditional character recognition methods to recognize overlapped characters, a new method was proposed for overlapped characters recognition in construction drawings based on adaptive scale edge features. Based on the spatial distribution characteristics of pixels, the overlapped character areas were preliminarily determined, and the adaptive scale edge features of characters were defined and extracted. The result combination of “position + content” was screened with the help of the bivariate matching probability function, and the global optimal principle was used instead of the absolute threshold as the identification standard. Finally, the correct recognition of overlapped characters was achieved. Different from the conventional idea of recognizing after repairing, the new method combined feature matching and interference filtering, character positioning and character recognition. The proposed method can solve the overlapping character recognition problem insolvable for mature commercial OCR such as Baidu,and the data experiment proves that this method is of high recognition accuracy.
overlapped characters; character recognition; adaptive scale; distribution probability; projection segmentation
5 January,2022;
“Thirteenth Five-Year” National Key R&D Plan (2016YFC0702001)
WANG Zheng (1997-), master student. His main research interest covers image recognition based on computer vision. E-mail:907022655@qq.com
TU17
10.11996/JG.j.2095-302X.2022040729
A
2095-302X(2022)04-0729-07
2022-01-05;
2022-02-07
7 February,2022
“十三五”国家重点研发计划项目(2016YFC0702001)
王 正(1997-),男,硕士研究生。主要研究方向为基于计算机视觉的图像识别。E-mail:907022655@qq.com
邓雪原(1973-),男,副教授,博士。主要研究方向为建筑CAD协同设计与集成、基于BIM技术的建筑协同平台等。Email:dengxy@sjtu.edu.cn
DENG Xue-yuan (1973-), associate professor, Ph.D. His main research interests cover architectural CAD collaborative design and integration, building collaborative platform based on BIM technology, etc. E-mail:dengxy@sjtu.edu.cn
猜你喜欢 字符识别字符投影 全息? 全息投影? 傻傻分不清楚军事文摘(2022年8期)2022-05-25论高级用字阶段汉字系统选择字符的几个原则汉字汉语研究(2020年2期)2020-08-13基于最大相关熵的簇稀疏仿射投影算法新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25字符代表几小学生学习指导(低年级)(2019年12期)2019-12-04一种USB接口字符液晶控制器设计电子制作(2019年19期)2019-11-23图片轻松变身ASCⅡ艺术画电脑爱好者(2019年8期)2019-10-30找投影学生天地·小学低年级版(2019年5期)2019-06-05找投影学生天地(2019年15期)2019-05-05融合字符及字符排列特征的铭牌识别方法现代电子技术(2016年22期)2016-12-26一种基于OpenCV的车牌识别方法软件导刊(2016年11期)2016-12-22






