基于随机森林与支持向量机的回采工作面瓦斯涌出量预测方法
时间:2023-06-04 19:30:23 来源:雅意学习网 本文已影响 人 
成小雨,周爱桃,郭焱振,程 成,李德波
(1.中煤能源研究院有限责任公司,陕西西安 710054;
2.中国矿业大学(北京)应急管理与安全工程学院,北京 100083;
3.中煤新集刘庄矿业有限公司,安徽阜阳 236200)
瓦斯涌出量是指在矿井建设及生产过程中从煤与岩石内涌出的瓦斯量,是煤矿安全生产的主要威胁之一[1]。通过对矿井瓦斯涌出量进行预测,进而采取必要的防范措施可以减少乃至有效预防瓦斯事故的发生,从而保证矿井安全生产以及保障工作人员生命安全。开采过程中,瓦斯涌出量随自然条件和开采技术变化而改变,这些因素间存在着耦合性、非线性[2]。近年来许多学者从深度学习领域积极探寻瓦斯涌出量的预测方法:王艳晖等[3]基于改进果蝇算法(MFOA)结合支持向量机(SVM)对瓦斯涌出量进行了预测;
董晓雷等[4]将遗传算法(GA)与支持向量机(SVM)结合,建立了回采工作面瓦斯涌出量预测模型;
王生全等[5]借助BP 神经网络结合遗传算法(GA)建立了瓦斯涌出量预测模型。部分学者将特征筛选方法[6]运用到瓦斯涌出量预测中:李树刚等[7]将因子分析与BP 神经网络结合,对瓦斯涌出量预测展开了研究;
卢国斌等[8]借助主成分分析法结合BP 神经网络对回采工作面瓦斯涌出量进行预测;
付华等[9]提出一种基于LSTM 的瓦斯涌出量预测模型,并结合量子粒子群算法对相关参数进行了优化,测试表明该模型有着较好的表现;
吴奉亮等[10]、汪明等[11]提出了以随机森林算法进行瓦斯涌出量预测的方法。从前人研究来看,灰色理论在预测精度上难以满足要求;
神经网络类深度学习方法调参耗时费力,对数据要求较高且易过拟合。支持向量机与随机森林算法以其原理清晰等优点在农业[12]、生物学[13]、地球物理[14-15]等领域得到广泛应用。此外,部分学者将随机森林自身特征筛选功能与支持向量机(SVM)结合展开了相关研究[16-17],结果表明,与未进行特征筛选相比,该种方法在有效减少数据采集工作量的同时,基本取得了较为接近甚至更为理想的效果,这为解决该类多影响因素问题提供了思路:可以采取数据降维类方法对影响因素进行筛选后结合相关算法进行求解。为此,针对当前瓦斯涌出量预测中数据处理粗糙及数据利用程度不足等问题,将交叉验证、数据降维方法结合对数据进行处理;
针对预测方法单一、预测方法选取不合理问题,选取支持向量机与随机森林算法分别建立预测模型,通过对比筛选出较优的瓦斯涌出量预测模型。
1.1 随机森林原理
随机森林[18]是由多个决策树构成的集成算法,属于集成学习的一个子类,可用于分类及回归问题,它主要对样本单元和变量进行抽样,进而生成大量决策树。对每个样本单元来说,所有决策树依次对其进行分类,预测类别中的众数即为随机森林所预测的该样本单元所属类别(用于回归时,输出即为所有树预测值的均值)。
假设给定样本集X 中共有N 个样本单元,M 个特征属性,用于回归问题时随机森林算法大致如下:①采用Bootstrap 法从给定样本集X 中随机、有放回地抽取Q 个样本,生成决策树;
②在每一个节点随机抽取m 个特征(m
④对于新的样本点,用所有树对其预测,取各个树预测值的均值为模型最终预测值。


图1 RF 原理图Fig.1 Principle diagram of random forest
1.2 支持向量机原理
支持向量机是一种监督式机器学习模型,可用于分类及回归分析。处理非线性问题时借助核技巧将其由原始空间映射到高维空间,转换为该空间内的线性问题,进而寻找一超平面使得所有样本与该超平面的距离最小。该超平面的表达式可写作:

式中:ω 为权值向量;
b 为偏置值;
φ(xi)为非线性映射函数。
将上述问题转化为二次规划问题:

式中:ξi、ξi*为松弛变量;
C 为惩罚系数。
借助Lagrange 优化方法将上述问题转化为对偶问题,最终得到回归模型表达式为:

式中:αi、αi*为拉格朗日乘子;
K(xi,xj)为核函数。约束条件:

径向基核函数(RBF)表达式为:

式中:σ 为RBF 的径向量宽度。
2.1 数据来源和数据处理
实验所用样本数据取自中煤新集刘庄煤矿若干工作面历史监测数据,整理共计24 组,回采工作面瓦斯涌出量与影响因素见表1[19-20]。
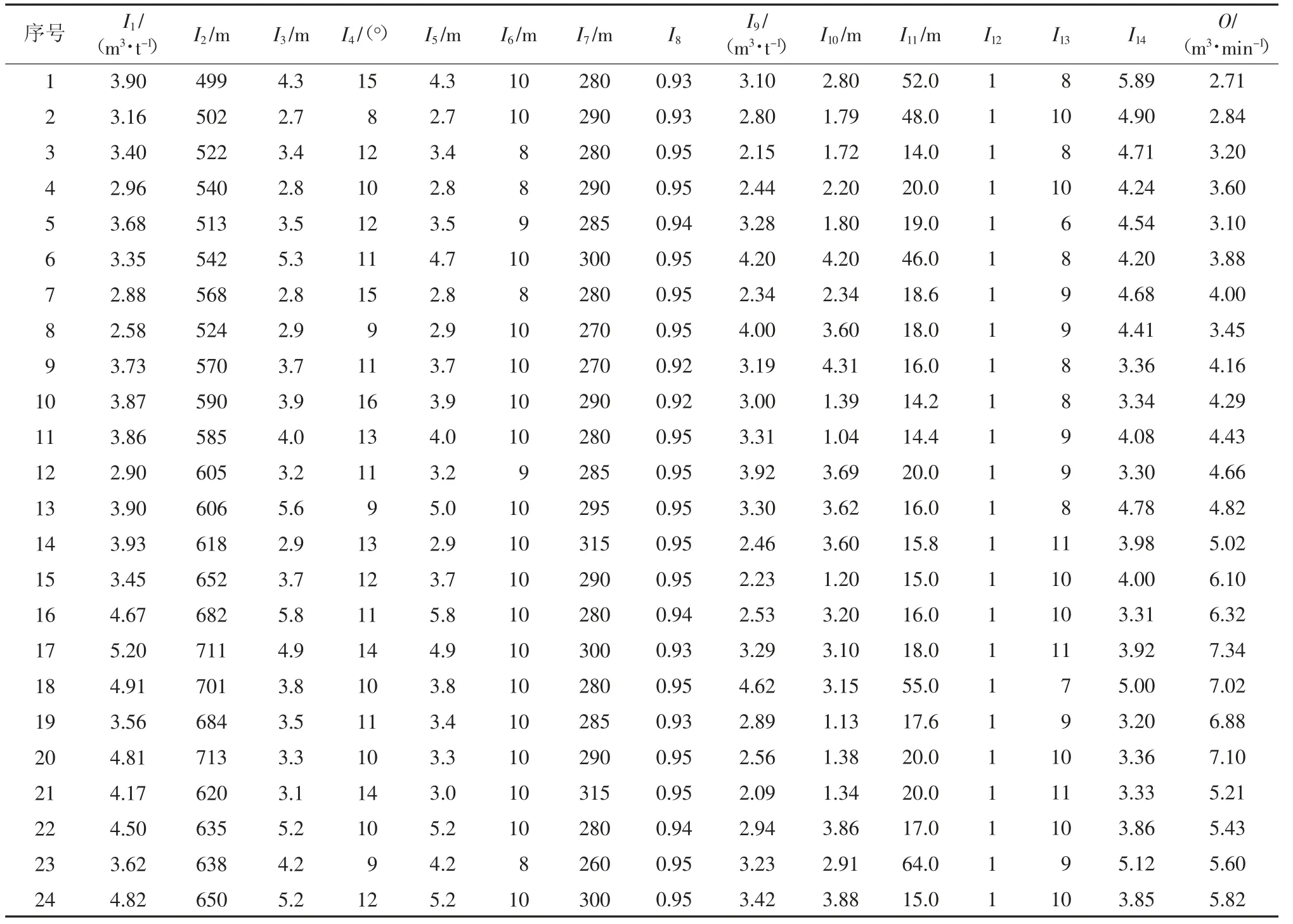
表1 回采工作面瓦斯涌出量与影响因素Table 1 Gas emission and influencing factors in mining face
为充分利用现有数据,综合考虑数据量及测试稳定性,采取K-折交叉验证(K-CV)处理数据集,K-折交叉验证原理如图2。
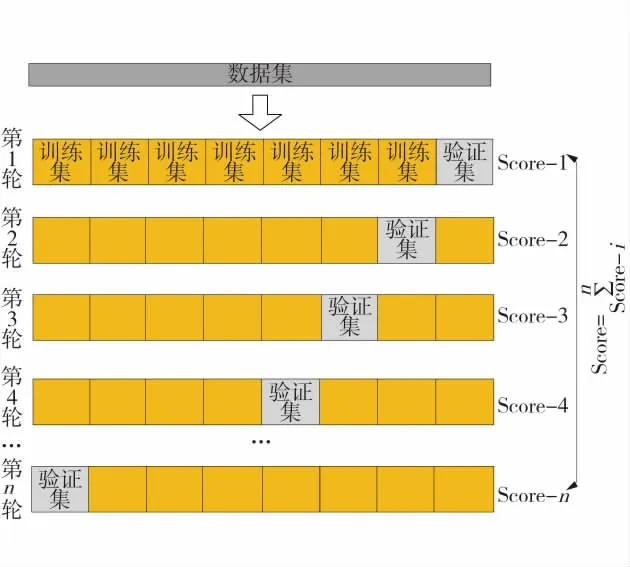
图2 K-折交叉验证Fig.2 K-fold cross validation
具体做法如下:
将数据集均分成K 份规模相同互斥子集,每次取其中K-1 份子集进行训练,余下1 组作为测试集,如此循环直至所有子集都作一次测试集。一般K 从3 取起,当K 与样本数相等时即为留一法交叉验证。
2.2 预测模型构建
相关预测模型构建工作均借助Python 编程语言中Sklearn 机器学习工具进行。支持向量回归模型(SVR) 中核函数有线性核、多项式核及高斯核(RBF)等,这里选取泛化能力强、待调参数少的RBF为核函数,惩罚系数C 与σ 按网格搜索法确定,其中C 搜索范围:[1、5、10、15、20、50、100、200];
σ 搜索范围:[0.01、0.02、0.03、0.04、0.05、0.1、0.2、0.5、1、5、10]。
随机森林回归模型(RFR)中待调节参数主要有2 个:树的数量N 以及最大特征数M,以网格搜索法确定二者取值,设置N 的范围为50~500,梯度50;
最大特征数取值方法有开方取值法、取对数值法、取整数法等,为了节省测试时间及直观查看其值对预测效果的影响,按取整数法设置M 搜索范围为3~10,梯度为1,其余参数按默认值选取。
2.3 实验流程
瓦斯涌出量预测模型构建流程如图3。

图3 瓦斯涌出量预测模型构建流程Fig.3 Flow chart of establishing gas emission prediction model
首先以交叉验证法对数据集随机拆分(shuffle=True)处理,通过SVR、RFR 预测模型得到各个子集预测结果,对其效果进行对比分析。
随后对特征筛选后数据集进行测试,经综合对比得到最优预测模型,并进一步对模型效果验证及分析。为确保测试合理性与可对比性,除预测模型中参数设置外,2 模型在其余处理上均保持同步。
2.4 K-折交叉验证(K-CV)
为增加测试可信度,K 值一般从3 取起,但随着K 值增加模型性能趋于稳定,而工作量也会随之增加。通过查阅相关文献确定在工程应用中K 值取作5 和10[21]。综上,为动态表述模型性能随折数K 变化趋势,设定K 范围为3~10,并从MSE、MAE、测试耗时T 3 个方面来考察模型性能,不同模型MSE、MAE、测试耗时T 与折数关系图如图4。

图4 不同模型MSE、MAE、测试耗时T 与折数关系图Fig.4 Relationship between MSE, MAE, test time T and fold number of different models
1)随折数K 增加,2 种模型的预测误差均呈现出下降趋势,并在K=10 时达到相对较低水平,MSE稳定在0.21 左右,此时SVR 模型参数C 为20,σ 为0.01;
RFR 模型参数取值N 为100,M 为10。
2)从测试耗时T 来看,SVR 模型每轮耗时约在0.015 s 甚至更低,而RFR 模型耗时约1~3 s,远高于前者。因此,SVR 模型整体表现上稍优于后者。
2.5 留一法(Leave-one-out)交叉验证
为探究10-折交叉验证与留一法交叉验证效果优劣,对数据集进行留一法处理后得到相关指标,得到留一法处理下SVR 模型参数C 为50、σ 为0.01,RFR 模型参数为N 为250,M 为10。不同交叉验证方法效果对比见表2。
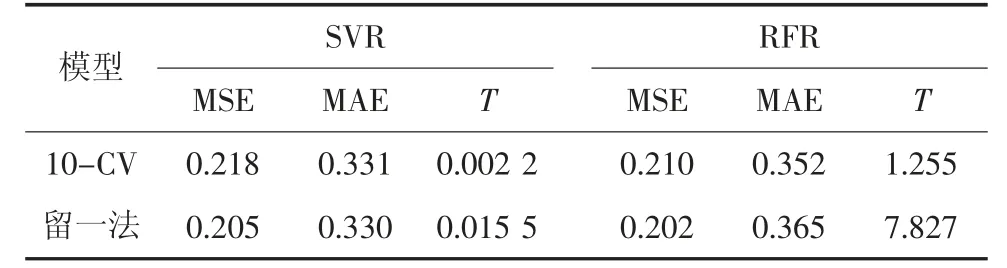
表2 不同交叉验证方法效果对比Table 2 Comparison of different cross-validation methods
留一法处理后模型性能有着小幅提升,测试过程中模型误差较为稳定,表现也相对优于10-折交叉验证,因此最终确定按留一法对数据集进行处理,不同模型预测效果对比图如图5。

图5 不同模型预测效果对比图Fig.5 Comparison of prediction performance of different models
2.6 特征筛选和结果分析及模型验证
应用随机森林算法获得14 个输入因素中特征重要度前8 位的因素依次为埋深、层间岩性、煤层瓦斯含量、邻近层厚度、煤厚、开采强度、采高、采出率,其值依次为0.539、0.151、0.116、0.042、0.04、0.033、0.022、0.021,累计重要程度达到95%以上。将其余因素“剔除”后建立新的数据集进行测试。
测试需调整RFR 模型中参数M 范围为3~8,梯度为1,其余设置不做改动。测试得到SVR 模型参数C 为100、σ 为0.01;
RFR 模型参数N 为350、M为8。特征筛选前后效果对比见表3,特征筛选后2 种模型预测效果对比图如图6。

表3 特征筛选前后效果对比Table 3 Comparison of indicators before and after feature screening
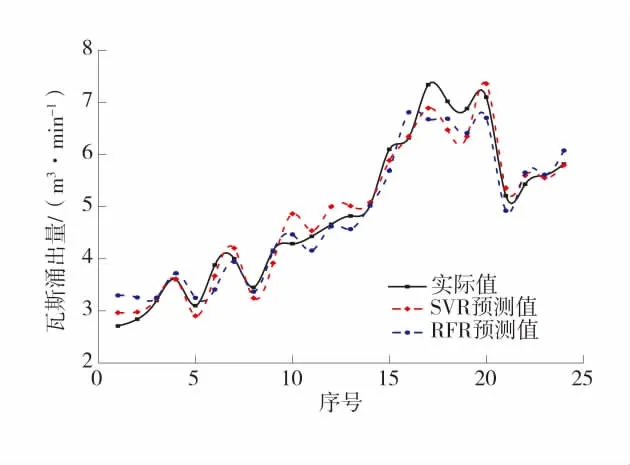
图6 特征筛选后2 种模型预测效果对比图Fig.6 Comparison of prediction performance of different models after feature screening
1)对输入因素进行降维处理后,2 种模型的预测性能均有大幅提高,MSE 值降低近50%,MAE 减少约30%;
其中SVR 模型MSE 值降低至0.073,MAE值低至0.216 左右。
2)测试耗时方面,SVR 模型基本稳定在0.015 5 s,而后者最高增加至10 s 左右,可能是建树量增加造成。
3)除极个别样本点波动稍大外,2 模型预测值与瓦斯涌出量真实值误差较小,几乎吻合。特征筛选后的预测模型均展现出了较好的预测效果。
选取处于回采阶段的若干工作面进行测试,验证工作面相关参数见表4,不同模型预测误差对比见表5,可以看出SVR 预测模型的性能最优,其平均绝对误差约为0.18 m3/min,平均相对误差约3.26%。
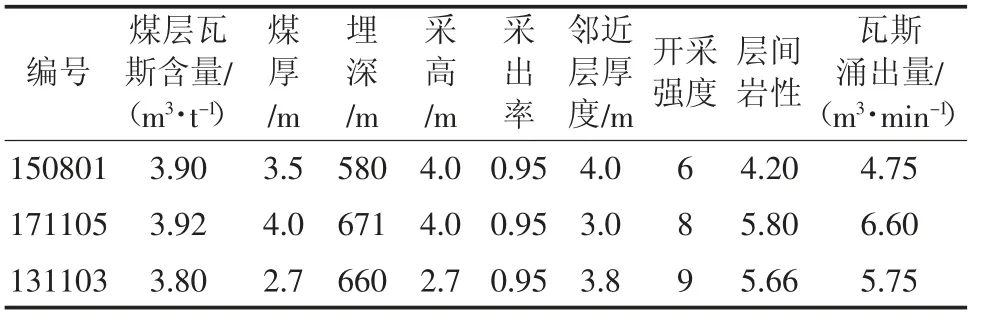
表4 验证工作面相关参数Table 4 Relevant parameters of selected mining faces
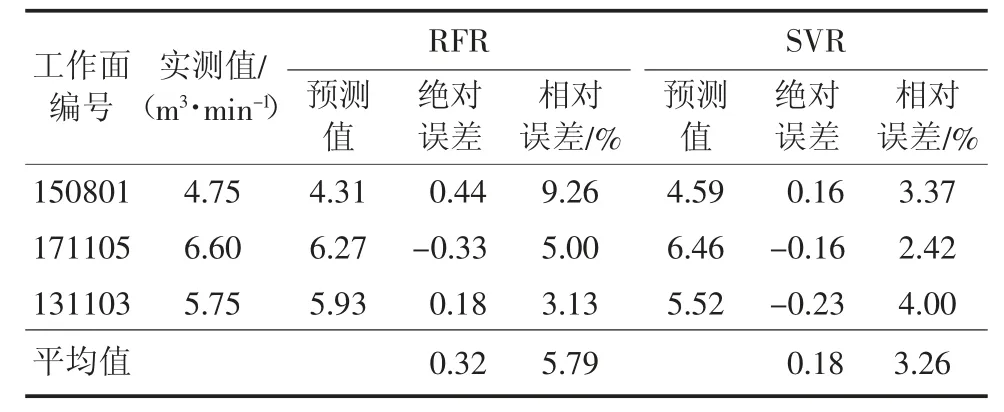
表5 不同模型预测误差对比Table 5 Comparison of gas emission prediction error of different models
选取影响煤矿瓦斯涌出量的14 个参数为特征,结合中煤新集刘庄煤矿历史监测数据,对数据进行交叉验证及降维处理,运用支持向量机与随机森林算法对工作面瓦斯涌出量预测进行了研究。
1)通过观测2 种预测模型性能随交叉验证折数K 变化情况,得到10 折交叉验证相对较优;
与留一法交叉验证进行二次对比后,确定以留一法进行数据处理时模型更为稳定、精度更高。
2)SVR 模型每轮测试耗时约在0.015 s 甚至更低,而RFR 预测模型则由0.3 s 开始增加,最高达10 s 左右,推测由于建树量增加导致。
3)对输入进行降维后,2 种模型的预测性能有着显著提升,其中RBF-SVR 模型MSE 低至0.073;
进一步验证得到,特征筛选后的SVR 模型表现最佳,其平均绝对误差约为0.18 m3/min,平均相对误差3.26%,表明采取降维处理在一定程度上简化了工作量,同时也保证了模型预测效果。







