基于LightGBM算法的漏洞利用预测研究
时间:2022-12-06 21:30:03 来源:雅意学习网 本文已影响 人 
尹毅峰, 杨显哲, 甘 勇, 毛保磊
(1.郑州轻工业大学 计算机与通信工程学院,河南 郑州 450001;
2.郑州工程技术学院 信息工程学院,河南 郑州 450001;
3.郑州大学 河南省教育信息安全监测中心,河南 郑州 450001)
网络安全预警的重点在于及时发现安全漏洞,而漏洞的两个关键要素是漏洞危害与漏洞利用[1],两者共同决定了一个安全漏洞的危害程度。安全漏洞是否会大规模爆发,在一定程度上取决于该漏洞是否存在漏洞利用,它对漏洞危害的范围起到了至关重要的作用。当然很多漏洞由于攻击成本、难度以及利益等问题,并没有漏洞利用的价值。相关研究表明,主流厂商的已知漏洞中只有15%曾经被“利用”,但这一小部分漏洞对攻击造成的影响占比却高达80%[2]。正是由于网络安全漏洞利用情况的不确定性,使得很多网络安全工作变得十分被动。如何判断漏洞是否被利用,是当下各个企业网络安全从业人员都十分关心的一个问题。确定了漏洞利用的存在情况,便可以提前做好漏洞预警工作,并将更多的精力放在此类漏洞修复上,优先对其进行安全加固与策略调整[3-4]。
在国内关于漏洞利用方面的研究相对较少,大多都以漏洞本身为重点,而国外近几年则已开展了相关的研究,例如Bullough等[5]提出了使用开源数据预测已披露软件漏洞利用的相关方法,但由于采集的数据集以及使用的算法等问题,没有达到一个理想的预测效果,难以在工业实践中应用。
基于上述研究背景与问题,本文通过采集常见漏洞披露(common vulnerabilities & exposures,CVE)[6]的漏洞数据并整合标记出新的数据集,提出了一种基于决策树算法的提升框架LightGBM(light gradient boosting machine)[7]的漏洞利用预测模型,通过仿真实验,预测CVE公开漏洞的利用情况,并实现了较高的预测准确率。相较之前国内外漏洞利用的研究,本文优化了之前数据模型并引入新的LightGBM算法模型,该算法基于直方图算法拥有更快的训练效率,同时采用离散Bins来替换传统的连续值存储,使其更适应现代工业实践环境[8]。
本文研究主要以漏洞结果为导向,可快速获得漏洞利用情报并易于规模化应用,最终达到提升企业网络安全预警能力,精确安全加固范围,降低修复成本。
1.1 漏洞评估体系
CVE就像一个字典,为全球广泛认知的网络安全漏洞或者风险弱点给出一个公共代号。漏洞利用EXP(exploit)一般指通过编写的代码或工具,利用某个安全漏洞攻击目标主机或者得到目标主机权限的过程[9]。每年都会有大量的CVE漏洞被公开,一旦漏洞公布,漏洞被利用的风险也随之增加。然而大多数漏洞实际上从未被利用过,也没有出现过漏洞攻击。虽然漏洞公开一般都需要进行修复,但实际工作环境中,由于编写、测试和安装软件补丁可能涉及大量的资源,因此工业实践中往往需要优先修复可能被利用的漏洞。
通用漏洞评分系统(common vulnerability scoring system,CVSS)是当前公开的漏洞评价标准[10]。目前已公布到V3.0版本,从基础、时间和环境3个维度进行度量评价,而且每一组又由单独的度量指标组成。其中基础度量标准组代表漏洞的固有特征,该特征在一段时间内以及在整个用户环境中都是恒定的,并由两套度量标准组成:可利用性度量标准和影响度量标准。时间度量标准反映了该漏洞可能会随时间而变化,但不会在用户环境中变化。环境度量标准代表特定环境下执行漏洞的分数,允许根据相应业务需求提高或者降低该分值。综合上述3个维度的评分,得到CVSS的最终评分,同时还会生产一个向量字符串,该向量字符串是用于对漏洞进行评分的度量值的文本表示形式,如图1所示。当然针对时间与环境的分值属于可选项,会根据用户情况与商业环境进行改变并通常情况下未有详细评价,为更加客观地进行实验,本文实验数据仅采集基础评分的度量信息[11]。CVSS漏洞评分系统的设计初衷是为了更加直观地评测漏洞危害的严重程度,各度量指标的分数值分布在0~10.0之间,可以量化地帮助相关人员确认要应对该漏洞的紧急度与重要性[12]。

图1 CVSS 3.0评分测量模型Figure 1 CVSS 3.0 scoring measurement model
1.2 基于LightGBM算法预测模型建立过程
在机器学习中,基于梯度提升树(gradient boosting decision tree, GBDT)算法,是目前业内公认的对真实分布拟合效果较好的算法之一[13]。它通过采用加法模型以及不断迭代减少前一轮的误差残值,从而达到将数据分类或者回归的效果。该模型具有训练效果好、可以灵活处理各类数据等优点。其中,针对二分类的GBDT算法过程如下所示。
首先,利用先验信息来初始化学习器,如式(1)所示:
(1)
式中:P(y=1|x)为训练样本中y=1的比例。然后,建立M棵分类回归树m=1,2,…,M,对i=1,2,…,N,计算第m棵树对应的残差值,如式(2)所示:
(2)
对于n=1,2,…,N,利用CART回归树拟合数据(xi,rm,i),得到第m棵回归树,其对应的叶子节点区域为Rm,j,其中j=1,2,…,Jm,且Jm为第m棵回归树叶子节点数。对Jn个叶子节点区域计算出最佳拟合值并更新得到强学习器Fm(x):
(3)
(4)
整合得到最终的强学习器FM(x)的表达式:
(5)
LightGBM是微软在GBDT算法基础上提出的一种改进的实现GBDT算法的框架模型,使用了基于直方图的分割算法取代了传统的预排序遍历算法,比GBDT算法具备更快的并行训练效率、更低的内存消耗、更高的准确率,并支持分布式,更加适应处理海量数据,且有效防止过拟合等优点[14]。
本文基于LightGBM算法构建了用于判断CVE漏洞是否存在被利用的风险预测模型,如图2所示,主要包含了数据采集、数据标记、数据预处理、LightGBM二分类器等主要过程[15-16]。

图2 基于LightGBM算法漏洞利用预测模型Figure 2 Vulnerability exploitation prediction model based on LightGBM algorithm
1.3 基于LightGBM算法模型最佳参数
实验采用的基于LightGBM算法模型包含了众多参数,经过26次迭代实验得到了该模型最佳效果的参数值,如表1所示。实验模型的场景为二分类,选取数据集中连续的10 000条数据作为实验数据集,然后利用随机函数进行样本分割,分割比例为9∶1,其中90%的数据为训练集,10%的数据为测试集。参数优化整体思路为先取一个较大的学习率即0.25,然后对决策树、正则化的基本参数进行调整,最后降低学习率,按0.01的步长减少,逐步提高准确率。在模型参数中为了提高准确率主要对learning_rate、max_depth以及num_leaves等进行调整优化,为了降低过拟合则通过min_data_in_leaf、feature_fraction、bagging_fraction等进行测试优化[17]。
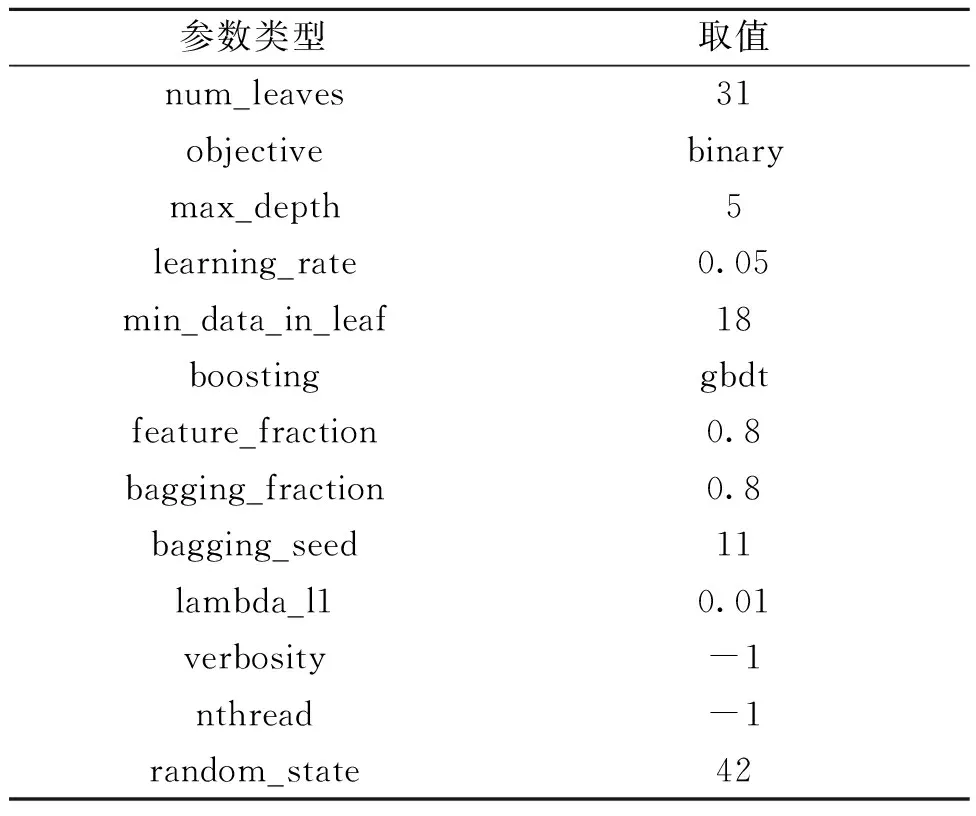
表1 LightGBM模型参数Table 1 LightGBM model parameters
2.1 实验环境与配置
实验数据主要是通过采集2015—2020年CVE公开的漏洞信息,其中包含有ID、Name、Descript、Severity、CVSS_score、CVSS_base_score、CVSS_impact_subscore以及CVSS_exploit_ subscore这8个数据类型共计78 246条数据信息。实验环境与配置信息:操作系统Windows 10,处理器为Intel(R) Core(TM)i7-9700K,内存16 GB,实验编程语言使用Python3.6。
2.2 实验数据与处理
在采集到的数据信息基础上,对这些数据进行整理分类并标记。其中对漏洞描述字段,提取包括厂商、中间件、操作系统、版本号、端口、开发语言、通信协议7种类型,针对漏洞进行分类标记Tpye类型,种类包括有缓冲溢出、代码注入、权限控制、信息泄露等共计22种。然后以目前国内外主流的漏洞利用情报库Exploit-DB与Seebug漏洞平台为主,对收集到的漏洞进行利用存在性标记,如果被这两个平台收录则漏洞利用确认存在,不收录则默认不存在,因此标记的漏洞利用均为已公开的漏洞利用。最后整合数据并作线性相关性分析,得到本文实验所采用的数据集,数据集特征类型如表2所示,表2中Severity字段根据CVSS评分划分为低危[0.1~4.0)、中危[4.0~7.0)、高危[7.0~9.0)、超高危[9.0~10.0]4个评级。使用Python3.6调取Pandas、Sklearn库完成对漏洞数据的预处理,针对漏洞描述的本文信息,根据正则表达式提取关键标签,并将其转化成哑变量后进行编码的方式,漏洞等级与类型则通过映射后统一进行编码规范化处理。

表2 实验数据集特征类型Table 2 Feature type of experimental data set
最后为了验证本文模型的优势,还对比实现了支持向量机SVM、人工神经网络ANN(反向传播)、朴素贝叶斯NB、以及K邻近算法KNN的建模[18]
2.3 评价指标
采用准确率ACC、精准率P、召回率R、F1值以及ROC曲线等统计指标来进行评价,对比实验中各算法在漏洞利用预测上的性能[19]。
如表3所示,TP为真实存在的漏洞利用且模型分类结果也为存在;
TN为未发现的漏洞利用且模型分类结果也为不存在;
FP为未发现的漏洞利用但模型分类结果为存在;
FN为真实存在的漏洞利用但模型分类结果为不存在。根据二分类混淆矩阵得到的数值利用式(6)~(9)得到量化的评价指标:

表3 二分类混淆矩阵Table 3 Two-class confusion matrix
(6)
(7)
(8)
(9)
从上述公式可以看出,精准率P可以弥补准确率ACC在正负样本不平衡的情况下的缺陷,使得评价指标更加客观真实;
召回率R衡量了分类器对预测真正存在漏洞利用占全部真实存在漏洞利用的比例;
精准率与召回率相互影响,为了平衡二者,采用F1值来进行调和平均。
2.4 结果与分析
使用本文提出的评价指标进行实验对比,包含运行效率、二分类问题的模型评价参数、ROC曲线以及灵敏度AUC值,统一设置阈值为0.5,大于0.5的判断为存在漏洞利用,反之则不存在。为了验证本文模型在CVE漏洞的利用预测的优势,将预处理过后的10 000条数据分别通过KNN、SVM、Naive Bayes、ANN以及本文模型进行分类效果实验,对比算法均进行了参数优化,并从不同维度进行比较分析,得出如表4、5和图3所示的实验结果。

表4 各类模型运行时间对比Table 4 Various models running time comparison

图3 各类模型ROC曲线对比图Figure 3 Various models ROC curve comparison chart
分别在相同实验环境与数据集的条件下,测试上述5种模型的运行效率,由表4的实验结果可知,SVM模型的运行时间最短,但与本文所提出的模型相差不多,ANN模型由于需要建立多个神经元层在本文环境下运行时间较长,其他几种模型整体运行时间均高于本文模型。
通过表5可知,本文模型除了召回率略低于SVM外,在准确率、精准率、F1值上均高于其他算法模型。相比其他模型,本文模型在F1值上分别高出了0.25、0.08以及0.12,说明该模型在针对CVE漏洞利用的预测上具有较好的效果。

表5 各类模型实验效果对比Table 5 Various models experiment effect comparison
综合上述对比实验数据,可以看出本文模型虽然在运行效率以及召回率上不及SVM模型,但SVM在预测准确率远低于本文模型。同时对比其他算法模型,无论是从时间、准确率等方面,本文提出的基于LightGBM算法模型的漏洞利用预测效果最好,且有一定的优势。
另外如图3所示为5种模型的ROC曲线图。ROC曲线是一种用于度量分类中的非均衡性的工具,也是评价一个二分类器优劣的重要指标。在ROC空间中,ROC曲线下的面积为AUC值,数值一般在0.5~1.0,其值越大代表分类器效果越好。从图3中可以清晰地看出,本文模型的AUC高于其他分类器模型,AUC值为0.78,相较其他模型分别高出了23.1%、25.6%以及17.9%,LightGBM模型整体表现出良好的漏洞利用预测效果。
通过上述针对ACC、P、R、F1值以及ROC曲线和AUC值的实验对比分析,在保证其准确率的情况下,本文模型的评价指标、运行效率以及预测效果均优于其他4种算法模型,并且整体准确率达到了83%,精准率和召回率分别达到了85%、76%,AUC值为0.78。综合评价数据以及对比分析,本文算法模型可以满足部分实际网络安全漏洞利用预测方面的工作需求,同时本文也验证了该算法模型的性能和可行性。
提出了一种基于LightGBM算法的漏洞利用预测模型,通过充分挖掘安全漏洞的数据特征,构建出新的漏洞利用数据集并结合LightGBM算法进行应用研究。实验结果表明,本文模型在漏洞利用的预测方面,无论在准确率、召回率还是在AUC值上均取得了较好的效果,具有较高的应用价值。当然本文模型还有很多需要提升的地方,目前模型仅实现对CVE漏洞的利用预测且只考虑CVSS基础评分,忽略了时间与环境因素的影响。在未来计划尝试对更多漏洞平台进行采集,扩大应用范围,同时也考虑引入遗传算法来对LightGBM模型参数进一步优化改进。
猜你喜欢 度量准确率漏洞 漏洞今日农业(2022年13期)2022-09-15鲍文慧《度量空间之一》上海文化(文化研究)(2022年3期)2022-06-28乳腺超声检查诊断乳腺肿瘤的特异度及准确率分析健康之家(2021年19期)2021-05-23多层螺旋CT技术诊断急性阑尾炎的效果及准确率分析健康之家(2021年19期)2021-05-23不同序列磁共振成像诊断脊柱损伤的临床准确率比较探讨医学食疗与健康(2021年27期)2021-05-13颈椎病患者使用X线平片和CT影像诊断的临床准确率比照观察健康体检与管理(2021年10期)2021-01-03不欣赏自己的人,难以快乐作文与考试·初中版(2019年15期)2019-04-28突出知识本质 关注知识结构提升思维能力江西教育B(2019年2期)2019-04-12侦探推理游戏(二)阅读(低年级)(2018年2期)2018-05-14三参数射影平坦芬斯勒度量的构造华东师范大学学报(自然科学版)(2018年3期)2018-05-14








