一种基于TCP-ARED,的网络动态拥塞控制策略*
时间:2023-06-30 10:05:02 来源:雅意学习网 本文已影响 人 
潘成胜,张 松,赵 晨,石怀峰,2
(1.南京信息工程大学电子与信息工程学院,南京 210044;
2.南京理工大学自动化学院,南京 210094)
近年来,网络智能化已成为网络创新式发展和变革的突出特征,与传统网络不同,智能网络中存在着大量实时多媒体业务,如网页浏览、语音聊天、视频会议等,这些业务产生了巨大、多样的数据流量[1-4]。网络转发设备的缓冲区在网络处于流量负荷大的情况下易被填满,产生网络拥塞问题[5-7]。基于源端的拥塞控制是缓解网络拥塞的有效办法,“端到端原则”提供的可扩展性在客观上促进了网络的快速发展,但基于源端的拥塞控制具有一定的滞后性,网络在检测到拥塞和拥塞发生的时间间隔内会一直处于拥塞状态[8]。因此,为了保障服务质量quality of service(QoS)模型有效地运行,不仅需要在源端实现拥塞控制,网络中间节点也需要发挥作用[9]。
队列管理是指网络出现拥塞时路由节点通过丢包来调节缓冲区的占有率,不同的队列管理机制直接影响到网络节点的拥塞控制能力和网络的QoS。总的来说,队列管理机制可以分为被动队列管理机制与主动队列管理机制两大类,与被动队列管理机制相比,主动队列管理机制能够使发送节点在中间节点缓存溢出前作出反应,有效减少和避免拥塞的发生。其中,RED(random early detection)算法作为主动队列管理机制中的代表性算法在拥塞控制方面起到了关键作用[10],该方法使路由节点缓冲区的队列在没有达到极值前就开始丢包,并向源端发送拥塞反馈信息,以此来缓解网络拥塞,但它存在参数配置敏感和全局同步现象等缺陷。为了保证低时延和高吞吐量,Floyd 等在RED 算法的基础上又提出了ARED(adaptive RED)算法[11],ARED 算法针对RED 算法存在的参数敏感性问题做出了一定的改善,但它自身又引入调节参数α 和β,由此产生了新的参数设置问题。为了充分利用路由器的缓冲区,Patel 提出了URED(upper threshold RED)算法[12],在RED 算法的基础上增加了一个更大阈值(upper threshold),这在一定程度上提高了平均队列长度的稳定性,但有时也存在时延增加和链路吞吐量下降等问题。
本文提出SP-ARED 算法,丢包策略方面,利用S 型分布函数对ARED 算法进行优化,在ARED 算法基础上使用平方函数和幂函数相结合的方式来优化丢包策略。阈值方面,结合URED 算法的思想,提出增加一个新的阈值上限SPth,充分利用路由器的缓冲区,以此来缓解网络中由流量突发而导致的网络拥塞问题。NS2 的仿真结果表明[13-15],SP-ARED算法提升了平均队列长度稳定性和吞吐量,并降低了丢包率和时延抖动。
1.1 RED 算法概述
相比被动队列管理算法DropTail,RED 算法具有吞吐量较高、时延较低和丢包率较小的优点,该方法通过监控缓冲区的平均队列长度来判断网络的拥塞情况。路由器接收新到达的数据包时要先计算平均队列长度Lav,令THmin和THmax分别为平均队列长度的最小和最大阈值。若Lav<THmin,队列的丢弃概率为0;
若THmin≤Lav≤THmax,路由器需根据求得的动态丢包概率Pb来对到达的数据包进行丢弃;
若Lav>THmax,丢弃概率则为1,下一刻到达的数据包将会被全部丢弃。Lav的计算方式为:
其中,当前时刻的Lav是瞬时队列长度q(t+1)与上一时刻的Lav进行加权计算而来,权值Wq是RED根据它对数据流输入的敏感性来设置的,范围为[0,1]。
上述提到的动态丢包概率Pb如下:
Pb和最终的数据包丢弃概率Pa关系为:
式中,count 为上一刻丢包后进入缓冲区的数据包个数,这也能够看出Pa与平均队列长度和进入缓冲区的数据包数量有关。
1.2 ARED 与URED 算法概述
RED 算法参数设置相对固定的缺点使得它很难适应动态变化的网络环境,为了减小RED 算法对参数设置的敏感性,研究人员又提出了ARED 和TRED[16]等改进算法。其中最具代表性的就是ARED算法,ARED 算法是一种自适应算法,算法的核心思想是根据当前的平均队列长度来判断网络拥塞状态,并动态地调整丢弃概率。动态调整maxp的主要代码如图1 所示。
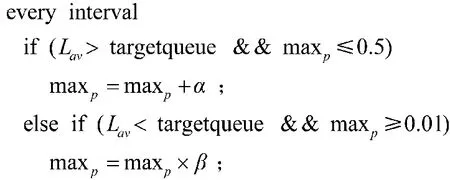
图1 ARED 动态调整代码Fig.1 Dynamic adjustment code of ARED
如果缓冲区当前的平均队列长度在THmin附近,说明数据包被过多地丢弃,丢弃策略过于激进,应该减小maxp;
反之,如果缓冲区当前的平均队列长度在THmax附近,说明数据包被丢弃得过少,丢弃策略过于保守,应该增大maxp[17]。代码中,interval为丢包概率改变的时间间隔,一般设置为0.5 s;
targetqueue 为理想的平均队列长度区间,范围为[THmin+0.4×(THmax-THmin),THmin+0.6×(THmax-THmin)];
α 与β 分别为maxp的加性增大和乘性减小因子,值为α=min(0.01,maxp/4),β=0.9[18]。
URED 算法通过引入新的阈值上限Uth来更好地利用缓冲区,在平均队列长度处于[THmax,Uth]范围时,丢弃概率由RED 算法中的直接变为1 转变成线性增大到1。Uth的引入增强了节点在流量突发时的处理能力,对于网络存在大量突发负载时,URED算法在某些方面的表现比ARED 算法更好。
2.1 SP-ARED 算法概述
与RED 算法相比,ARED 算法通过引入α 与β来提高maxp的动态调整能力,但α 与β 的引入也使得ARED 仍然存在着参数选取的问题。URED 算法提高了路由器缓冲区的利用率,但其在最小和最大阈值之间的丢包策略仍有进一步优化的空间。针对上述问题,本文在ARED 和URED 算法基础上提出改进算法SP-ARED,减小算法中固定参数值设定所带来的影响,在修改丢弃概率函数的同时保证平均队列长度的稳定性。
3 种算法的丢弃概率如图2 所示。平均队列长度在[THmin,THmax]区间时,采用类似于S 型的分布函数对ARED 算法的丢弃函数做非线性处理,目的是将算法的线性函数变得更平滑。具体实施过程中,采用分段函数的形式对平方函数(the square function)和幂函数(power function)进行有效组合。

图2 SP-ARED 丢弃概率Fig.2 Discard probability of SP-ARED


图3 SP-ARED 算法伪代码Fig.3 Pseudocode of SP-ARED algorithm
SP-ARED 算法中Pb的计算公式为:
2.2 SP-ARED 算法仿真
智能网络规模大,网络中业务类型繁多且流量具有突发性,因此,在仿真时增加流量突发的情况。具体表现为,在仿真35 s 和65 s 的时候分别开启和结束40 个TCP 连接,以此来衡量流量突发时QoS模型中的丢包率、时延、时延抖动和吞吐量等性能指标。
仿真中,节点R1和R2构成瓶颈链路,带宽设为20 Mb/s,传播时延设为15 ms。S1到Sn代表的是发射源端,D1到Dn代表的是接收源端。发射源端与R1相连接,接收源端与R2相连接,所有的链路带宽均设置为10 Mb/s,传播时延设为10 ms,发送源端Sn和相应的接收源端Dn建立起TCP 连接[19]。
仿真的拓扑结构如图4 所示。在R1队列上依次实施ARED、URED 和SP-ARED 算法。算法中相关参数的值设置如下:缓冲区大小设为156 packets,THmin=26 packets,THmax=78 packets,maxp= 0.1,Wq=0.002,依据经验将SPth设为最大阈值THmax的3/2,也为路由器缓冲区大小的3/4,即SPth=117 packets[12]。发射源端发送的数据包大小可以自行设置。

图4 仿真的拓扑结构Fig.4 Topology structure of simulation
3.1 队列长度稳定性
1)无流量突发情况
根据图4,建立80 个发射源端和接收源端的并发连接,仿真持续时间为100 s。图5~图7 分别表示3 种算法在无流量突发情况下的队列长度,蓝色和红色曲线分别表示实时以及平均队列长度情况。平均队列长度和它的变化情况是衡量算法性能的重要指标,它能够反映网络服务质量的好坏。

图5 无流量突发情况下的ARED 算法队列长度Fig.5 Queue length of ARED algorithm under no traffic burst

图6 无流量突发情况下的URED 算法队列长度Fig.6 Queue length of URED algorithm under no traffic burst

图7 无流量突发情况下的SP-ARED 算法队列长度Fig.7 Queue length of SP-ARED algorithm under no traffic burst
ARED 算法在[THmin,THmax]内缺乏有效的丢包策略,因此,随着业务量的增加,平均队列长度出现了持续性的波动且波动范围大,其平均队列长度稳定性最差。和ARED 算法一样,URED 算法在[THmin,THmax]内同样缺乏有效的丢包策略,但其通过设置更大的阈值在一定程度上提高了缓冲区的利用率,所以它的平均队列长度稳定性略优于ARED 算法。SP-ARED 算法在[THmin,THmax]采用了有效的丢包策略,并设置更大的阈值SPth来更有效地利用缓冲区,提高了数据包的转发效率。因此,相较于ARED 和URED 算法,SP-ARED 算法能够在负载增大的情况下减小平均队列长度的波动范围,提高平均队列长度的稳定性。
2)模拟流量突发情况
图8~ 图10 分别表示3 种算法在模拟流量突发时的队列长度。

图8 有流量突发情况下的ARED 算法队列长度Fig.8 Queue length of ARED algorithm under traffic burst

图9 有流量突发情况下的URED 算法队列长度Fig.9 Queue length of URED algorithm under traffic burst

图10 有流量突发情况下的SP-ARED 算法队列长度Fig.10 Queue length of SP-ARED algorithm under traffic burst
根据图4,采用相同参数来模拟流量突发的情况。开始时启动80 个TCP 连接,35 s 的时候增加40个TCP 连接,TCP 连接数此时变为120 个,并在65 s的时候减少40 个TCP 连接,重新恢复为80 个TCP连接,仿真过程持续100 s。
模拟流量突发情况下,URED 算法的平均队列长度波动幅度最大,尤其是在35 s~65 s 的时间段内,平均队列长度出现了持续的振荡,其平均队列长度稳定性最差。ARED 算法在35 s~65 s的时间段内平均队列长度也出现了持续的振荡,但其在仿真开始的0~10 s 这段时间内,平均队列长度的波动范围小于URED 算法,因而ARED 算法的平均队列长度稳定性在整体上略好于URED 算法。SP-ARED算法下的平均队列长度波动范围小于ARED 和URED 算法,仅在35 s 和65 s 附近出现了小幅度的抖动,平均队列长度总体上维持在理想区间内,这使得路由器缓冲区有空间处理突发流量,有效提高了数据包的转发效率。
图中的平均队列长度及其变化情况表明,网络无论是处于重度负载还是流量突发情况下,SP-ARED 算法下的平均队列长度稳定性均优于ARED 算法和URED 算法。
3.2 丢包率
3 种算法的丢包情况如表1 所示。丢包率是评价和衡量网络性能的重要指标,更低的丢包率能够反映出网络服务质量更好。表中,Lose 和Send 分别表示丢弃和发送的数据包数量,TCP 连接数为80时,SP-ARED 算法的丢包率相较于ARED 和URED算法分别下降了8.67%和6.78%;
模拟流量突发情况下,即TCP 连接数增至为120 时,SP-ARED 算法的丢包率相较于ARED 和URED 算法分别下降了8.62%和2.16%。通过上述分析可以得出,网络在处于重度负载和流量突发情况下,SP-ARED 算法的丢包情况均优于ARED 和URED 算法,这表明了本文改进ARED 算法与URED 算法的有效性。

表1 3 种算法丢包率Table 1 Packet loss rates of three algorithms
3.3 端到端平均时延
3 种算法的端到端平均时延如表2 所示。文中指数据包从源端到目的端的平均时延,该指标能够反映业务的体验情况,时延越大表示体验程度越不好。TCP 连接数为80 时,ARED 算法的端到端平均时延最大,URED 算法次之,SP-ARED 算法最小,SP-ARED 算法的时延相较于ARED 和URED 算法分别减少了0.62%和0.49%。模拟突发流量产生的情况下,即TCP 连接为120 的时候,URED 算法的端到端平均时延最大,SP-ARED 算法次之,ARED算法表现最好。SP-ARED 算法的时延相较于URED算法减少了1.34%,相较于ARED 算法增加了0.09%。

表2 3 种算法端到端平均时延Table 2 Average end-to-end delay of three algorithms
端到端平均时延由传播时延和排队时延组成,从3 种算法的对比中可以看出,传播时延相同的情况下。TCP 连接为80 时,数据包在路由节点缓冲区中时,SP-ARED 算法的平均排队时延最小。但当TCP连接为120 的时候,SP-ARED 算法的平均排队时延高于ARED 算法,这是因为端到端平均时延与队列长度相关,相较于ARED 算法,此时SP-ARED 算法的丢包策略能让更多的数据包进入队列等待发送,增大了平均队列长度。尤其是仿真在35 s~65 s 时,SP-ARED 算法的平均队列长度大部分时刻高于ARED 算法,导致了时延的增大。这表明SP-ARED算法在时延方面的表现较差,仍有待提高。
3.4 时延抖动
3 种算法的时延抖动如表3 所示,文中用时延的方差(σ2)表示时延抖动[20]。时延抖动是数据包时延的变化量,它反映了算法在网络系统中的稳定性。时延抖动越小,网络稳定性越好;
反之,时延抖动越大,网络稳定性越差。TCP 连接数为80 时,URED 算法的端到端时延抖动最大,ARED 算法次之,SP-ARED 算法最小,SP-ARED 算法的时延抖动相较于ARED 和URED 算法分别减少了19.38%和20.52%。模拟突发流产生情况下,即TCP 连接为120 时,结果保持一致,SP-ARED 算法的时延抖动相较于ARED 和URED 算法分别减少了9.80%和11.66%。
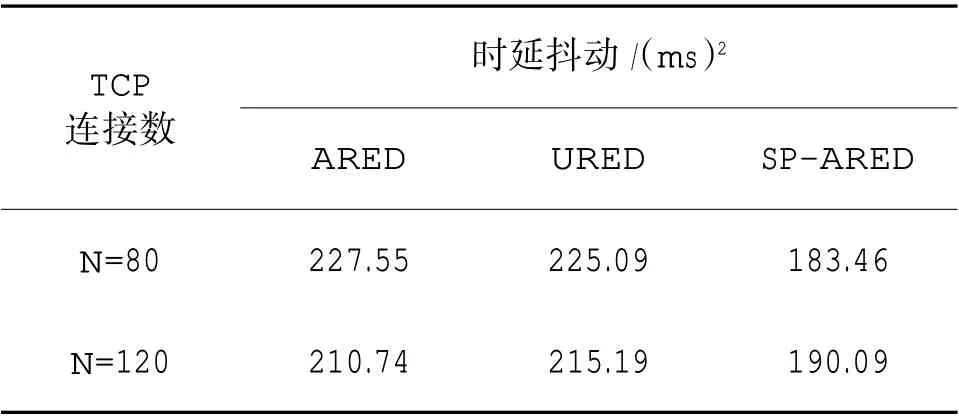
表3 3 种算法时延抖动Table 3 Delay jitter of three algorithms
通过上述分析可以得出,SP-ARED 算法在时延抖动方面的表现相较于ARED 和URED 算法有了较大的提升,这也表明SP-ARED 算法在3 种算法中稳定性最好。
3.5 吞吐量
3 种算法的吞吐量如表4 所示。较高的吞吐量能够使网络更加流畅,从而提高网络的性能。表中,TCP 连接数为80 时,SP-ARED 算法的瓶颈链路吞吐量相较于ARED 和URED 算法分别提高了0.52%和0.67%;
流量突发情况下,即TCP 连接数为120时,SP-ARED 算法的瓶颈链路吞吐量比ARED 和URED 算法分别提高了0.40%和0.38%。从上述分析可以得出,网络在处于重度负载和流量突发情况下时,SP-ARED 算法的链路吞吐量都是最高的,算法提升了网络的服务质量。

表4 3 种算法吞吐量Table 4 Throughput of three algorithms
作为拥塞控制体系中不可或缺的一环,主动队列管理机制对于提高网络服务质量起到了重要的作用。针对ARED 算法和URED 算法中存在的不足,本文提出了一种改进算法SP-ARED,SP-ARED算法通过采用分段函数优化丢弃策略和引入新的阈值上限来提高网络的服务质量。实验结果表明,除时延以外,SP-ARED 算法在平均队列长度稳定性、丢包率、时延抖动和吞吐量方面的表现都有了一定的提高,拥塞控制效果较好。下一步将思考如何提升时延的表现。
猜你喜欢包率缓冲区队列支持向量机的船舶网络丢包率预测数学模型舰船科学技术(2022年10期)2022-06-17一种基于喷泉码的异构网络发包算法*计算机与数字工程(2022年1期)2022-02-16电磁线叠包率控制工艺研究农业工程与装备(2021年1期)2021-05-17队列里的小秘密小学生学习指导(低年级)(2020年4期)2020-06-02基于多队列切换的SDN拥塞控制*软件(2020年3期)2020-04-20在队列里军营文化天地(2018年2期)2018-12-15基于网络聚类与自适应概率的数据库缓冲区替换*沈阳工业大学学报(2018年1期)2018-01-08嫩江重要省界缓冲区水质单因子评价法研究水利规划与设计(2017年11期)2017-12-23丰田加速驶入自动驾驶队列产品可靠性报告(2017年7期)2017-09-05TCN 协议分析装置丢包率研究铁道科学与工程学报(2015年4期)2015-12-24








