一种用于心脏运动估计的快速图像配准方法
时间:2023-06-18 21:40:02 来源:雅意学习网 本文已影响 人 
赵华秋,谢勤岚
(中南民族大学 生物医学工程学院,武汉 430074)
据2018年的中国心血管病报告[1],心脏疾病在我国的发病率和致死率一直高居不下.心脏疾病与心脏形态和运动功能密切相关,在整个心跳周期内会影响着左心室(Left Ventricle,LV)及左心室心肌(Left Ventricular Myocardium,LVM)的结构和功能,心脏磁共振电影成像(Cardiac Cine MRI)常用来衡量心脏的复杂三维运动,从临床的角度出发,详细了解心脏功能和心肌的运动状态,具有潜在的诊断意义.
传统图像配准方法如对称图像的归一化方法Syn[2]以及Demons[3]形变图像配准方法,通过对两幅图像之间的多次迭代,同时使用高斯滤波器对位移场进行平滑处理,得到图像配准所需的基本变化.也有相应的Elastix[4]工具包直接用于医学图像的配准.陆雪松等[5]采用最小距离树方法对传统方法进行改进,完成了对待分割图像之间的非刚性配准.传统方法速度慢,且不能有效地学习到数据间的关联信息,局限性较大.为解决这些问题,近几年已经有很多深度学习方法在配准领域的应用,如ROHE等[6]从一对标签图像中建立真实形变并用以训练.WANG等[7]将低维傅里叶表示引入配准网络降低了计算的复杂性.FAN等[8]通过一个分层的双重监督网络,利用间隙填充及粗到细的引导来修正网络,得到了更好的结果.HU等[9]利用标签进行弱监督,通过标签之间的相似性来训练网络.这些都是有监督的学习方法,需要图像标签(Ground Truth,GT)作为核心支持,但医学图像的标签稀少难得,模型的性能过于依赖标签质量.
空间变换网络[10](Spatial Transformer Network,STN)提出以来,无监督学习进行图像配准的方法逐渐流行,且无需额外的标签支持训练[11].ZENG等[12]提出CorrNet3D通过变形重建点云序列建立精确的对应关系,实现了无监督学习下的点云配准.DEVOS BD等[13]提出的深度学习配准框架DLIR是利用卷积神经网络实现的无监督医学图像配准技术.BALAKRISHNAN等在UNet[14]模型的基础上改进的经典VoxelMorph[15]网络是一种端到端配准网络,在脑部配准任务上取得了与传统方法相媲美的精度,同时有着更快的配准速度.SHEIKHJAFARI等[16]提出了一个全连通网络的可变形图像配准算法,通过深监督网络优化空间变换,用于2D心脏图像的配准.DEVOSBD等[17]提出DIRNet,是第一个基于深度学习的无监督端对端的图像配准模型,在MNIST手写数据和心脏MRI扫描图像的结果优于Elastix方法.但如SHEIKHJAFARI的工作是在2D图像上进行的,DEVOSBD等人的工作并未使用正则化项约束位移.而无监督学习方法在心脏运动估计方面的应用较少,不同于脑部图像相对静止的情况,心脏跳动产生的非线性形变会带来巨大挑战.
基于此,本文提出一种无监督学习的心脏运动估计方法,利用卷积神经网络实现三维心脏运动估计.心脏运动估计网络通过优化相似性度量和正则化项的和来训练,不需要监督信息.接收一对输入的三维心脏CineMR图像并输出一个预测的形变场,正则化项对形变场施加平滑约束.实验结果表明:该网络在开销较小的情况下,让心脏运动估计任务的性能得到提升,能够推导出兼具平衡运动特征和图像配准精度的运动模型.
用于心脏运动估计的快速图像配准框架由心脏运动估计网络、空间变换网络组成,如图1所示.完整的心跳周期由舒张末期(End Diastole,ED)至收缩末期(End Systole,ES)构成,Fixed Image和Moving Image分别表示定义在三维空间上的固定图像和运动图像,以F和M表示.F对应着ED的一帧,M对应着ED到ES期间的每一帧,因此从ED开始到ES有n帧的单个病人数据,有(n-1)对样本组成输入.

图1 心脏运动估计的快速图像配准框架Fig.1 Fast imageregistration framework for cardiac motion estimation
传统图像配准方法的本质是将图像配准转化为参数优化问题,通过反复迭代得到最佳参数.而本文提出的方法将心脏运动估计转换为数据驱动的学习任务,将其定义为一个参数函数gθ(F,M)=Φ,采用心脏运动估计网络对函数进行建模,其中θ为网络的可学习参数,Φ为形变场(Deformation Field),通过给定的输入图像对参数θ进行优化.空间变换网络STN通过预测出的形变场Φ将运动图像M扭曲为形变图像M·Φ,训练过程中计算形变图像与固定图像之间的相似性Lsim(F,M·Φ)和形变场的正则化项Lsmooth(Φ),两者组成损失函数L(F,M,Φ)优化网络,其中正则化项用以对形变场施加平滑约束,加强局部区域的形变学习,保证形变场的平滑度.
1.1 心脏运动估计网络结构
用于快速配准方法的心脏运动估计网络结构如图2所示,矩形内的数字为相应的通道数,下方括号内的数字代表图像的尺寸变化,最初为1,1/2表示尺寸缩减一半.网络的输入是一对大小为80×80×16的固定图像F和运动图像M,输入图像被连接成一个双通道三维图像.该网络的所有卷积层均采用步长为1、大小为3×3×3的卷积核,每层后伴有一个权重为0.2的LeakyRelu激活函数.编码器部分,下采样层采用内核大小为2×2×2的最大池化替代VoxelMorph中的跨步卷积,以保留更多图像信息.解码器部分交替经过三次上采样、跳跃连接和卷积层,跳跃连接将编解码部分的信息融合,使网络在更丰富的特征下预测形变场.最后应用一次卷积输出预测的3×80×80×16的张量即形变场,分别代表着xyz三个方向上的体素变形.该网络仅有三层,相比于Voxelmorph的四层结构,其层数更少,便于搜寻图像之间的细微变换.

图2 心脏运动估计网络结构Fig.2 Cardiac motion estimation network structure
1.2 空间变换网络
受输入数据在空间多样性方面的影响,对于大尺度空间变换,卷积神经网络稳定性较弱,空间变换网络能够灵活嵌入已存在的卷积神经网络结构中,使其具备空间变换的能力,主动在空间上转换特征映射并学习相应的变换,其结构如图3所示.

图3 空间变换网络结构Fig.3 The structure of spatial transformer network
Input和Output分别为输入图像和输出图像,定位网络(Localization Net)根据输入图像产生空间变换Tθ的参数θ,随后网格生成器(Grid Generator)根据定位网络产生的参数θ构建采样网格,代表着输出图像与输入图像之间像素点的映射关系;
采样器(Sampler)则是将产生的采样网格作用于输入图像上,通过插值方式产生相应的输出图像.
1.3 损失函数
在图像配准中,将一幅运动图像M配准到一幅固定图像F,描述的是从固定图像到运动图像的映射,建立了像素级的对应关系.而形变场的平滑性以及形变图像与固定图像的相似度,是衡量模型效果的重要因素,因此模型的损失函数由两部分组成:

其中Lsim测量形变图像M·Φ与固定图像F之间的相似度,λ为正则化参数,正则化项Lsmooth保证形变场Φ的平滑性.
采用归一化互相关(Normalized Cross Correlation,NCC)作为图像的相似性度量Lsim:

在大小为n3的图像块上计算NCC,其中表示大小为n3的图像块中点p周围的像素点,Ω即是大小为n3的空间域,NCC的值越高表明图像之间的相似性越高,因此将损失函数中的相似度定义为Lsim(F,M,Φ)=-NCC(F,M·Φ)去不断优化网络,但一味地追求最大化图像相似性测度,网络预测的形变场在图像的局部区域会出现不连续的情况,对预测形变场的空间梯度使用扩散正则化进行平滑,以加强对局部小区域的敏感性.正则化项为:

其中Ω表示形变场图像的空间域,p表示空间域内的不同体素点,∇Φ则表示相邻体素之间的差异,用以近似空间梯度.
2.1 实验数据集
实验采用的心脏图像数据为2017年自动心脏诊断挑战赛(Automated Cardiac Diagnosis Challenge,ACDC)数据[18].心脏磁共振电影成像是量化心脏功能和心脏运动状态的重要成像手段之一,其时空分辨率足够高,能够在一次心动周期内连续采集心脏某个层面的多个相位影像,做到运动状态下的成像追踪.该数据包含150例不同患者的心脏Cine MR影像,100例为训练图像,50例为测试图像.5个病理组分别为:扩张型心肌病(Dilated Cardiomyopathy,DCM)、肥厚型心肌病(Hypertrophic Cardiomyopathy,HCM)、心肌梗塞(Myocardial Infarction,MINF)、右 心 异 常(Right Ventricle Abnormal,RVA)、以及正常心脏(Normal Case,NOR).100例训练数据提供了每张图像ED和ES时期的对应帧时相,以及专家手动分割的标签信息,将该100例训练数据用于网络的训练和测试.
2.2 评价指标
评价指标采用配准任务中常用的Dice系数(Dice Coefficient,Dice)和 豪 斯 多 夫 距 离(Hausdorff Distance,HD)作为衡量指标.Dice系数描述的是两张图像之间的重合程度,其值在0到1之间,计算方式为:

其中,EDlabel为舒张末期的标签图像,ESwarped为形变标签图像,Dice的值越高,表明形变图像与固定图像的重合度越高,配准效果越好.而豪斯多夫距离常用以描述两个点集之间的相似程度,在心脏运动估计任务中用以衡量预测值与真实值之间的表面距离,估计配准前后图像之间的差异,其计算方式为:

hd(EDlabel,ESwarped)表示从收缩期的标签图像到形变标签图像的单向豪斯多夫距离,T为收缩期标签图像中的点集,P为形变标签图像中的点集,||T-P||是点T到点P的欧式距离.
2.3 训练与测试
为了以分割标签量化心脏运动估计的结果,按照8∶2的比例将ACDC的训练数据集部分均匀划分为心脏运动估计任务的训练集和测试集.由于主要关注左心区域,首先将所有图像定位到左心室的中心,以此中心将图像裁剪为80×80×16大小以包含到整个左心区域,以减少周围其他区域带来的干扰.网络图像对由ED和ES对应的两帧及两帧之间的图像构成,训练时将图像对拼接后输入,学习率设置为1×10-4,正则化参数λ设置为1.0,epoch设置为100,训练过程使用Adam优化器[19],每次输入图像一对,STN通过训练产生的形变场将运动图像扭曲与固定图像作相似度比较.训练完成后对20名其他患者的数据进行测试,挑选出测试数据中心脏ED图像和ES图像分别作为固定图像F和运动图像M,同时获取其LV及LVM对应的标签,将训练得到的形变场作用于心脏ES图像的标签ESlabel,根据其形变后的图像ESwarped与ED图像的标签EDlabel分别计算LV及LVM对应的Dice系数,度量其相似性.使用固定图像F和运动图像M计算配准前的豪斯多夫距离,形变图像M·Φ与固定图像F计算配准后的豪斯多夫距离,比较配准前后的差异.为评估所采用方法的有效性,进行五折交叉验证实验,训练数据和测试数据按均等比例随机抽取.
2.4 实验环境
使用Pytorch框架构建模型,操作系统为Windows 10,所有实验均在一张Nvidia GTX 2080Ti的GPU上实现,显存为11 G.
在ACDC数据集的LV和LVM上测试,将本文提出的方法与VoxelMorph的不同版本Vm1、Vm2以及三层Unet模型Unet3,进行实验比较.表1展示了不同配准方法的Dice结果,可见所设计模型在LV上配准精度约为87.4%,较Vm1模型提高1.4%,较Vm2模型提高1.1%,较三层Unet模型提高0.7%;
在LVM上的配准精度约为73.6%,较Vm1模型提高2%,1.7%,比三层Unet低0.1%;
在整个左心区域的平均配准精度为80.5%,较Vm1模型提高了1.7%,1.4%,较三层Unet提高0.3%.图4的箱型图以一种相对稳定的方式描述数据的离散分布情况,使实验数据更加直观.

图4 不同配准方法Dice结果箱型图Fig.4 The Dice results box plot of different registration methods
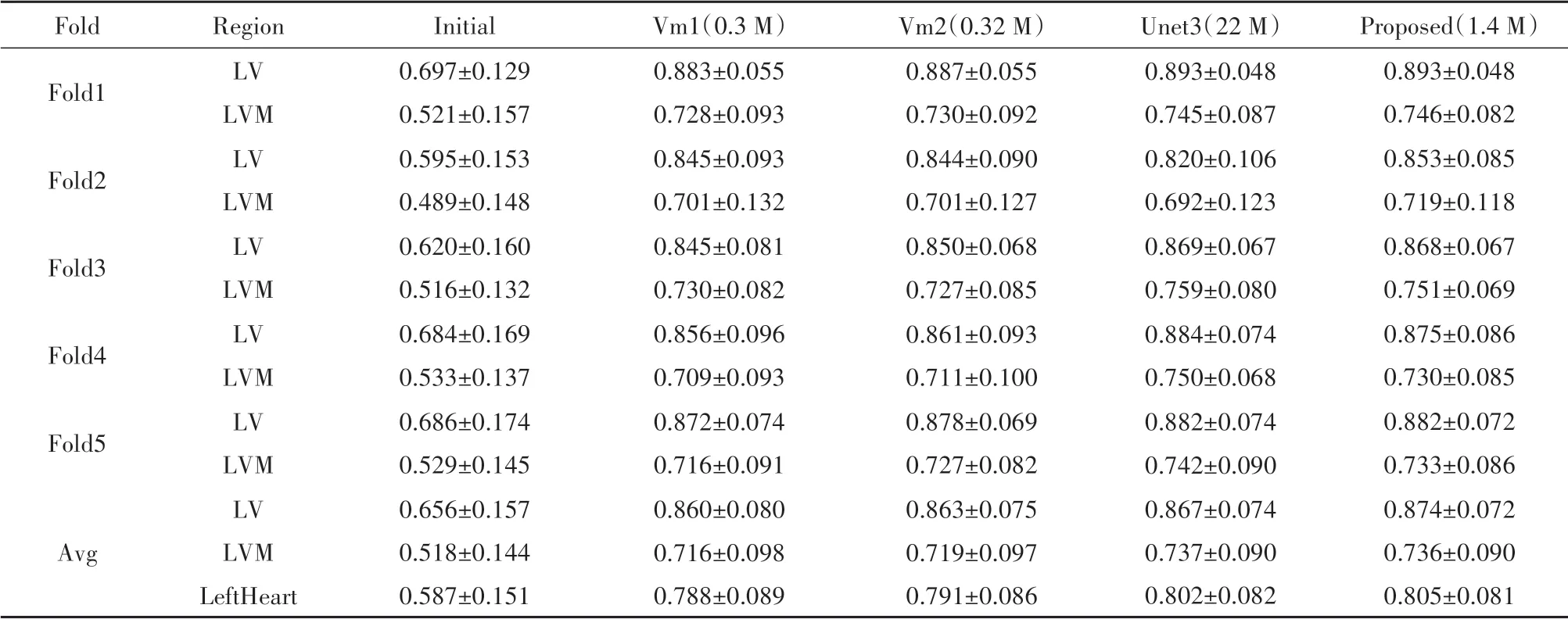
表1 不同配准方法在ACDC数据集上的左心室与左心肌的Dice配准结果Tab.1 Test Diceresultsof left ventricleand left myocardiumof different registration methodson ACDCdataset
通过表1中的结果可以发现,心脏运动估计网络在Dice上为最优,在网络参数量相比Vm1,Vm2模型仅有小幅提升,远小于Unet3模型,其开销更小更加轻便,在心脏运动图像配准任务上具有较优的性能.表2为不同配准方法下的豪斯多夫距离测试结果,本文提出的心脏运动估计网络在整个左心区域以6.011±1.924的最小豪斯多夫距离取得最优效果,即配准后的心脏图像差异更小.

表2 五折交叉验证方法下的豪斯多夫距离Tab.2 Hausdorff Distance under the five-fold cross validation method /mm
图5展示了不同病例在各方法下的形变图像于左心室和左心室心肌外壁的轮廓匹配结果,每列分别对应不同方法下产生的图像轮廓.观察发现各方法下的配准结果差异较明显,所提出的方法相较于其他方法在LV和LVM上与固定图像的差异更小,图中绿色轮廓为金标准,红色轮廓为各方法下得到的轮廓,黄色箭头指向变化明显的区域.
为主观性评价实验结果,图6展示了不同方法下心脏运动估计的可视化结果,其中(a)为扩张型心肌病DCM;
(b)为肥厚型心肌病HCM;
(c)为心肌梗塞MINF;
(d)为右心异常RVA.每一类图像中的第1列为对应的M和F,第1行显示产生的形变场,形变场以RGB图像表示,对应着xyz方向的偏移量.第2行显示形变图像,第3行显示变形网格.红色方框标记形变图像外观差异较大的区域,可以发现在4类病例中,本文提出的方法产生的形变场更加丰富细腻,形变图像最接近固定图像,能够捕获更精确的细节,特别是在HCM和MINF两类病例上,所提方法在运动特征估计方面有更优的结果,详细地保留了病理特征,在评估心脏状态时至关重要.
由图5和图6,可以发现所提出的方法在保持图像差异性更小的同时,达到了更高的配准精度,能够更好地完成心脏运动估计.但仍然存在图像锯齿感较明显的问题,这是由于图像的分辨率低、纹理信息较粗糙造成的,未来工作将致力于通过多级预测不同分辨率下的形变场,进一步提高配准效果.

图5 左心部位的轮廓匹配结果Fig.5 Theedge matchingresultsof left cardiac part

图6 不同的心脏病例在不同方法下的配准可视化结果Fig.6 Visualization resultsof registration under different methodsfor different cardiac disease cases
为验证所提出方法的有效性,比较不同模型的配准性能,探讨采样方式、通道数对配准性能的影响,对所设计的模型在相同的实验环境下进行了一系列消融实验.表3总结了所有的实验结果,并给出了各种方法在GPU上配准一对图像所需的时间,表中结果均为五折交叉验证实验下的最终统计结果.
表3中Pro代表本文提出的方法,Proa为通道数减半的模型,Prob为通道数缩小四倍的模型,对应的Pro-s,Proa-s,Prob-s采用跨步卷积代替池化层提取特征.所提方法配准每对图像在6.693±0.391 ms内,以0.805±0.081的Dice和6.011±1.924的HD获得最佳的配准结果.以上实验结果表明,心脏运动估计网络在保持较低的运动估计误差的同时,实现了更高的配准精度.
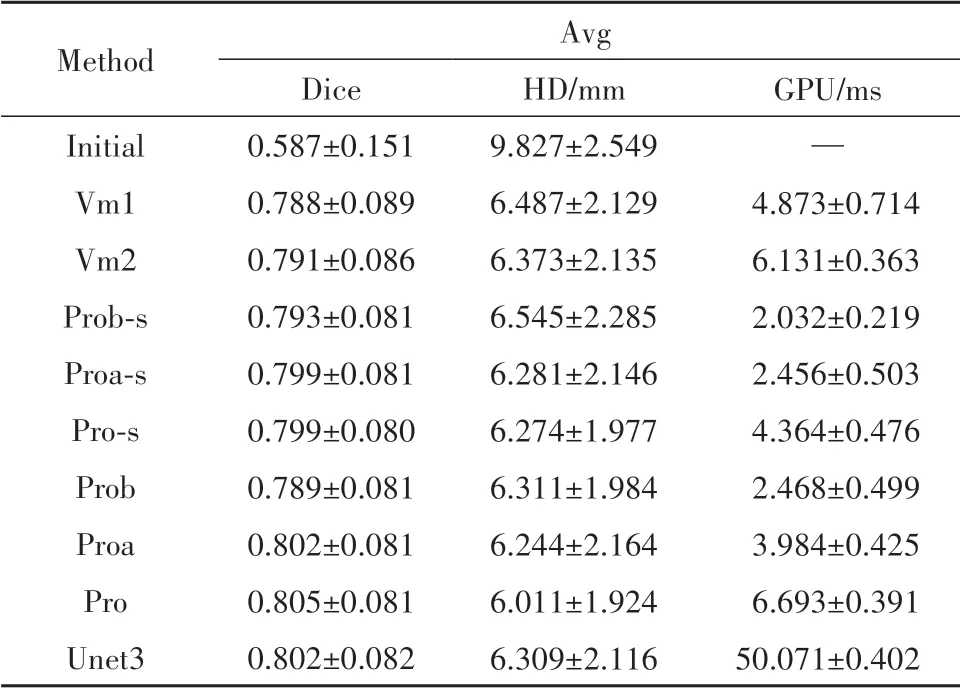
表3 各方法在ACDC数据集上的实验结果Tab.3 Experimental results of different methods on the ACDCdataset
通过将心脏运动估计问题转化为数据驱动下的学习任务,提出了一种端到端的基于无监督学习的三维心脏运动估计网络,实现了心脏运动估计.通过平衡图像相似性和形变场平滑度进行训练,且不需要任何标签作为监督信息.在ACDC数据集上的结果表明所提出的方法相较于现有的无监督学习方法如VoxelMorph,运动估计误差更小,配准精度更高,可在开销较小的情况下快速准确地进行心脏运动估计.
猜你喜欢 标签卷积心脏 基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02卷积神经网络的分析与设计电子制作(2019年13期)2020-01-14心脏青年歌声(2019年5期)2019-12-10从滤波器理解卷积电子制作(2019年11期)2019-07-04无惧标签 Alfa Romeo Giulia 200HP车迷(2018年11期)2018-08-30不害怕撕掉标签的人,都活出了真正的漂亮海峡姐妹(2018年3期)2018-05-09基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20让衣柜摆脱“杂乱无章”的标签Coco薇(2015年11期)2015-11-09科学家的标签少儿科学周刊·少年版(2015年2期)2015-07-07有八颗心脏的巴洛龙小学生·多元智能大王(2015年7期)2015-07-03








