基于门控循环单元网络的农产品价格预测模型构建
时间:2023-06-17 13:05:03 来源:雅意学习网 本文已影响 人 
王桂红, 潘 栋, 刘向锋
(沈阳农业大学 信息与电气工程学院, 沈阳 110866)
随着我国农业现代化的发展和信息技术的进步,利用农产品市场交易过程中积累的历史数据信息进行短期价格预测对指导农业生产、消费具有重要意义。例如利用价格预测可以避免农产品价格的剧烈波动导致市场供需失衡的问题[1]。传统的预测模型有基于回归分析法建立的回归模型和基于时间序列法构建的ARIMA模型[2],这类模型通常适用于平稳的线性序列数据,在处理复杂的非线性时序数据时,预测值与真实值会有较大偏差。而神经网络具有良好的并行处理、自组织以及自调整性,其中门控循环单元网络GRU(gate recurrent unit,GRU)引入了更新门和重置门的概念,这改变了循环神经网络中隐藏状态的计算方式[3],因此基于GRU构建的模型可以捕捉时间序列中时间步较大的依赖关系[4],更适合处理海量数据和非线性问题[5]。实验部分首先构建数据集,再利用Dropout方法抑制过拟合模型,通过对比实验调节训练轮次、网络层数、神经元个数等超参数。根据消融实验选择合适的损失函数与优化器,最终建立预测准确率较高与效率最佳的预测模型。
1.1 规范名称数据
原始的农产品信息通常是不规范的。本研究以大蒜为例,名称包括紫皮大蒜、白皮大蒜、山东大蒜等,对于价格没有显著差别的同种产品,细分名称类别对预测精度没有提升,因而将名称统称为大蒜,批量修改数据表中名称列的内容:Update vegetable set name=“大蒜”。
1.2 规范价格数据
以大蒜的某条价格记录为例,其字段为“3.3元/公斤”。因为价格预测需保留数字部分,剔除价格单位,所以从字段左侧起,剔除每一个非数字的字符,“元/公斤”包含4个字符,需要执行4次mysql的更新语句:
Update vegetable set vegetable.price=left(vegetable.price, char_length(vegetable.price)-1)where right(vegetable.price,1)not in(′0′,′1′,′2′,′3′,′4′,′5′,′6′,′7′,′8′,′9′)。
1.3 规范地区信息
使用正则表达式解析农产品产地信息中的字段,例如将“湖北省武汉市江岸区”划分为省市区3级,第1级为湖北(省|自治区|直辖市),第2级为武汉(市|区|县|自治州),第3级为江岸(区|乡|镇)。正则表达式如下:
(?〈Province〉[^省]+省|.+自治区)(?〈City〉[^自治州]+自治州|[^市]+市|[^盟]+盟|[^地区]+地区|.+区划)(?〈County〉[^市]+市|[^县]+县|[^旗]+旗|.+区)?(?〈Town〉[^区]+区|.+镇)?(?〈Village〉.*)。
1.4 农产品时序数据预处理
时间序列数据最关键的特征是序列性,价格数据随着时间序列而变化。为保证数据的时序一致性,首先将数据表中的价格按时间先后进行升序排列,在处理缺失数据时,若缺失时间点较少,则使用该点附近的平均值作为该点的数据填充[6];若缺失时间点较为密集并且跨度较大,填充失去意义,则将缺失时间点剔除不作处理,对于重复数据则取均值进行去重。
通过对原始数据进行线性变换,将价格特征数据缩放到[0,1][7-8],消除数据的量纲与大小带来的影响。本研究使用的数据归一化方法是最大最小标准化,公式如下:
(1)
式中:x′代表处理完成的数据;x为当前时刻该特征的真实值;xmax和xmin表示的是原始数据集在该时间区间内的最大值和最小值[9]。在处理完成之后再对数据进行反归一化处理,将数据映射到原有数量级上,从而更直观地反映数据变化情况。
2.1 基于GRU构建价格预测模型
2.1.1 构建数据集
经过归一化的数据需要划分为训练集和验证集,为避免出现使用未来数据预测历史数据的情况,本研究采用时间序列交叉验证法代替随机样本法来划分训练集与验证集,也称为滚动交叉验证[10]。
首先定义变量Training set=dataset[:′2018′].iloc[:, 1∶2].values,把训练集通过日期索引获取初始日期到2018年之间的大蒜价格数据,再根据下标来获取第一列的数据作为训练集Training set,将2019年1月、2月的数据作为验证集Test set,训练集与验证集占比分别为70%和30%,它们均以Price这一列作为特征值[11]。
以60个时间步为一个样本,定义一个输出为大蒜的预测价格,通过for循环用归一化以后的数据来构建序列数据集,参数为时间步和样本数量[12],第一个参数为i-60,选取第一个维度的大蒜价格作为训练集的特征向量,再用数据集末尾最后的一个样本作为验证集的特征向量。
2.1.2 构建初始模型
GRU的网络容量一般与网络中可训练参数成正比,即神经元数量和网络层数越多,网络的拟合能力越强,但是存在着训练速度慢和过拟合的问题[13]。实验初始模型构建如下:
通过Sequential()创建GRU序列模型model_gru:model_gru = Sequential()。
将模型增加GRU层, input_shape是序列长度,特征为1,验证设定激活函数为Tanh。加入全连接层:
model_gru.add(GRU(48,return_sequences=True,input_shape=(x_train.shape[1],1), activation=′Tanh′))。
再调用compile编译模型, 优化器Optimizer使用随机梯度下降法SGD,设置学习率learning_rate为0.01,损失率decay为1e-7,冲量momentum为0.9,损失函数采用均方误差MSE:
model_gru.compile(optimizer=SGD(learning_rate=0.01, decay=1e-7, momentum=0.9), loss=′mse′)
预测的是一个值,输出层数为1: model_gru.add(Dense(1))。
将验证集Training set作为参数,最终通过预测函数得出预测值GRU_predict。
2.1.3 模型优化方法
Dropout方法修改了训练中的学习过程, 通过禁止特征检测器之间的相互作用,减轻了模型对于局部特征的依赖程度,同时也提高了模型的泛化能力,提升网络的性能,避免了过拟合的情况[14]。
将GRU网络加上Dropout层,固定输入输出神经元不变,通过model_gru.add(Dropout(0.2))来随机删除运行时批次中的20%隐藏神经元,减少隐藏层节点间的相互作用。
2.2 GRU模型参数确定
2.2.1 对比实验
在分析数据量的大小与特征的基础上,确定批次大小batch_size为32,将训练轮次、网络层数等超参进行组合,设计对比实验,具体参数设置见表1。

表1 参数名称与参数值表
使用fit函数训练模型,在GRU层与全连接层均为1,神经元为48的情况下,不同训练轮次的运行结果如图2所示。

(a) 50训练轮次损失(b) 100训练轮次损失(c) 200训练轮次损失(d)最优训练轮次损失

(a) 16个神经元训练结果(b) 32个神经元训练结果(c) 48个神经元训练结果
损失Loss为模型误差,实验误差率均以百分比衡量再化简符号,例如9.95%的误差定义为0.099 5。由图1(a)、图1(b)和图1(c)可知,当Epoch为50时,误差为0.099 5,当Epoch为100时,误差为0.083 6,当Epoch为200时,误差为0.086 4。因此确定最佳训练轮次为100,将模型按最佳轮次进行迭代,如图1(d)所示,最终误差降到0.036 5。固定网络层数,组合不同神经元个数的多次实验,当网络层数均为1时,实验结果见表2。
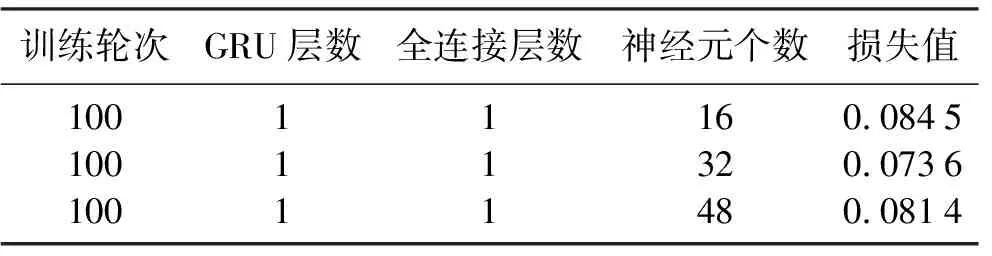
表2 神经元个数与损失值关系
由表2可知,在保持训练轮次和模型层数不变的情况下,当神经元个数为16时,误差为0.084 5;当神经元个数为32时,误差为0.073 6;当神经元个数为48时,误差为0.081 4,即最佳神经元个数为32。不同神经元个数运行的预测结果如图3所示。
运行结果展示了真实价格与预测价格的走势和对比情况,蓝色折线为真实值,橙色折线为预测值。其中图2(a)展示的是16个神经元的训练结果,预测曲线较为平稳,在价格峰值和谷值时,预测值与实际值差距较大,图2(b)为32个神经元的训练结果,预测值能准确地描述出价格波动的情况,比图2(c)的48个神经元的预测结果更贴近真实值曲线。将GRU层数、全连接层数与神经元个数进行组合实验,结果表明神经元个数为32时模型精度最高。通过多次组合实验,得出最佳超参数组合为:训练轮次100、GRU与全连接均为3层、神经元个数为32。
2.2.2 消融实验
初始模型的优化器使用的是SGD,即无动量的随机梯度下降,指定了学习率和衰减值,SGD的高方差振荡使网络难以稳定收敛。Adam在SGD的基础上增加一阶动量和二阶动量[15],在迭代的过程中学习率可随梯度的变化而动态调整。通过优化相关方向的训练和弱化无关方向的振荡,将更新向量的分量添加到当前更新向量,达到加速训练的效果。因此,将优化器更换为Adam来研究动量对于网络的影响。
初始模型使用的激活函数为Tanh,在训练时出现端值并趋于饱和时会导致训练速度减慢,将激活函数更换为非饱和激活函数Relu来研究减轻梯度消失对模型的影响。
使用已确定的超参数再对优化器和激活函数进行组合,设计消融实验,各参考设置见表3。

表3 优化器与激活函数组合表
通过更换优化器和激活函数完成消融实验,实验误差率如图3所示。实验组的误差率分别为:0.058 3,0.047 6,0.055 3,0.043 5,其中实验4组的误差率最小为0.043 5。
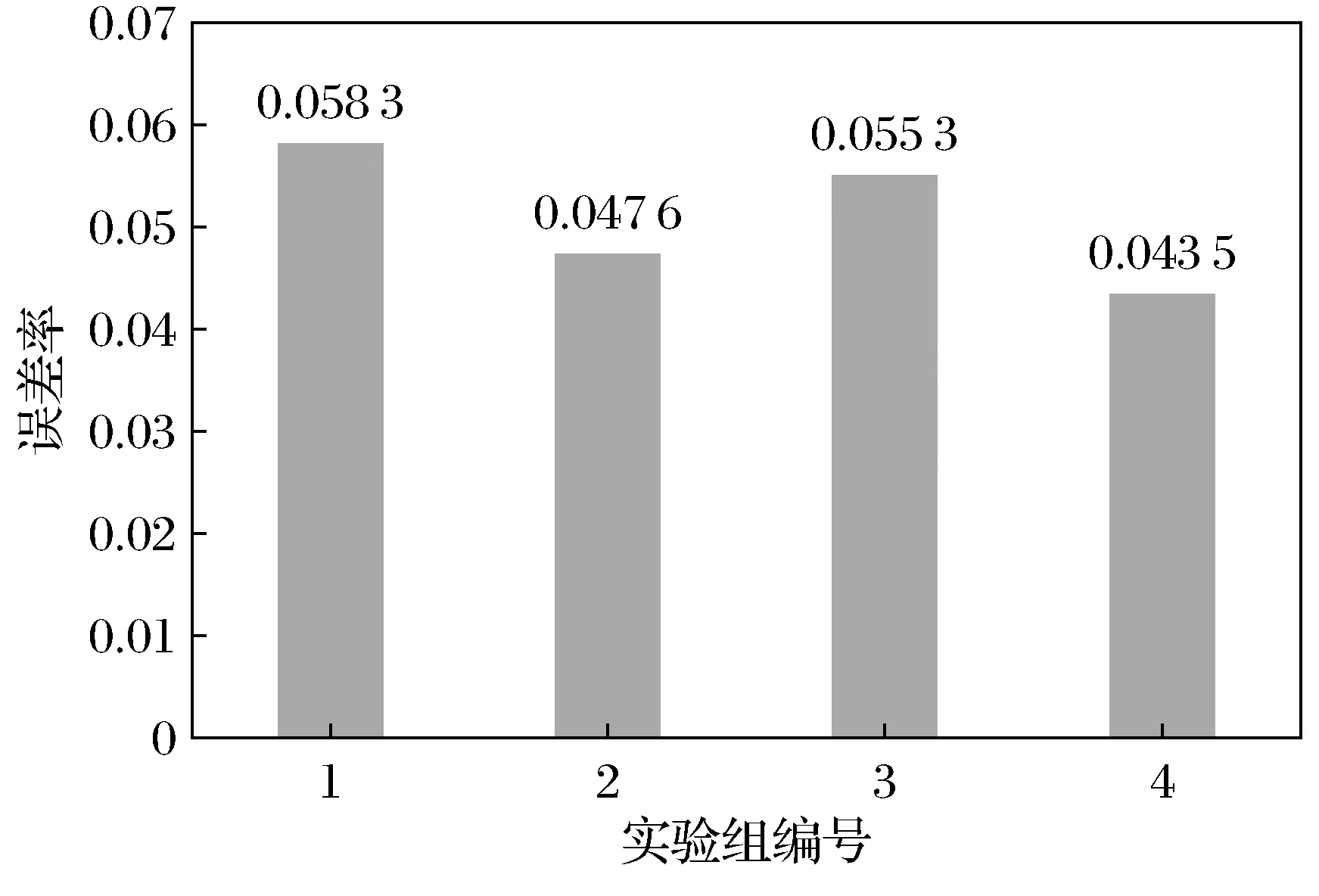
图3 实验误差率
图4显示了实验的运行耗时,4组实验运行时间分别为:14.8,12.5,13.6,10.8 min。其中第4组运行时间最短,为10.8 min。模型预测数据的准确程度如图5所示。

图4 实验运行时间

(a) 实验1组(b) 实验2组(c) 实验3组(d) 实验4组
从图5可以看出,预测价格和真实值大多集中在3元到4.5元之间。图5(a)的实验1组中预测曲线整体符合真实价格走势情况,但当价格剧烈波动产生极大值与极小值时,预测曲线表现得不够明显;图5(b)的实验2组与1组的前期预测曲线较为接近,但2组的预测值偏高,后期预测值更接近真实值;图5(c)的实验3组整体预测值偏低,偏离实际值的峰值曲线较多,比较符合价格下跌的曲线;图5(d)的实验4组不论是价格上升还是下降,预测曲线都较好地描述了价格波动的特征。实验表明实验4组的预测效果最好,即在增加动量和使用非饱和激活函数并且减轻梯度消失的情况下,模型的准确度较高。因此,模型的优化器应选择Adam,激活函数选择Relu。
通过对比实验与消融实验对初始模型进行调节优化,最终预测模型的结构与相关参数如下:神经网络使用GRU、训练轮次为100次、GRU层数和全连接层数均为3层、神经元个数为32个,优化器使用Adam,激活函数选取Relu。最优超参的GRU模型预测准确率较高并且运行耗时短。本研究搭建的最佳预测模型的普适性强,将大蒜的价格时序数据替换为其他农产品的价格时序数据,亦可做出相应的短期价格预测。
猜你喜欢 个数大蒜神经元 种植大蒜要注意啥今日农业(2021年19期)2021-11-27怎样数出小正方体的个数小学生学习指导(低年级)(2021年9期)2021-10-14等腰三角形个数探索中学生数理化·七年级数学人教版(2019年10期)2019-11-25怎样数出小木块的个数小学生学习指导(低年级)(2019年9期)2019-09-25大蒜养生法金桥(2018年1期)2018-09-28怎样数出小正方体的个数小学生学习指导(低年级)(2018年9期)2018-09-26种大蒜小学生作文(中高年级适用)(2018年6期)2018-07-09跃动的神经元——波兰Brain Embassy联合办公现代装饰(2018年5期)2018-05-26防病抑咳话大蒜海峡姐妹(2018年5期)2018-05-14ERK1/2介导姜黄素抑制STS诱导神经元毒性损伤的作用中国生化药物杂志(2015年4期)2015-07-07






