基于Hellinger,距离与词向量的终身机器学习主题模型
时间:2023-06-10 17:15:20 来源:雅意学习网 本文已影响 人 
雷恒林,古兰拜尔·吐尔洪,买日旦·吾守尔,曾 琪
(新疆大学信息科学与工程学院,乌鲁木齐 830046)
在信息技术高速发展的时代,往往需要从海量的信息中获取到高价值的核心内容,以对后续工作进行决策支撑,主题模型由此被提出并得到广泛应用。主题模型是指利用计算机技术对文本信息进行挖掘,可在大量互联网数据中自动发现文本中的语义主题。主题模型是自然语言处理的一个重要方向,其以非监督的学习方式对文集中的隐含语义结构进行聚类。常见的主题挖掘模型有概率隐性语义分析(Probabilistic Latent Semantic Analysis,PLSA)模型[1]、隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型[2]、非负矩阵分解(Non-negative Matrix Factorization,NMF)模型[3]等。
传统的机器学习主题挖掘模型是孤立类型的学习模型,其通过在特定的语料下进行模型训练,使模型达到最好的效果。这种学习方式存在的一大问题就是无法对训练过程中的知识进行有效保存,当模型面对一个新的数据集时,只能重新学习,以往学习过的知识无法得到充分的利用。目前,终身机器学习得到了研究者越来越多的重视,其克服了传统机器学习的孤立性问题。终身机器学习的概念最早由THRUN 等[4]于1995 年提出。根据文献[5]中的阐述,终身机器学习是一个持续学习的过程,在任何一个时间点,模型已经学习了N个学习任务,当新到来一个任务时,可以利用之前学习到的任务中的知识,帮助新来任务的学习。终身机器学习是对人类学习方式的一种模仿,通过将有效知识保存在知识库中,新任务可以从知识库中获取到对当前任务有用的知识,从而达到提高当前学习效果的目的[6],而且终身机器学习无监督模型在学习过程中无需标签,大幅减轻了人工成本。
经典终身主题模型(Lifelong Topic Model,LTM)可从其他领域中学习知识,帮助当前领域的学习,但在领域选择时,该方法没有根据影响权重进行一定的偏向性学习,并且模型通过给词语编号的方式来表示词语,没有充分利用词语的上下文信息,对词语之间在整个语料库中的全局联系缺乏考虑。本文提出基于Hellinger 距离与词向量的终身主题模型(Hellinger Distance and Word Vector based Lifelong Topic Model,HW-LTM)。针对LTM 模型在主题选择时缺乏针对性的问题,使用Hellinger 距离进行主题分布之间距离的计算,加快运行速度。同时,利用Word2vec 主题模型获得词向量,计算余弦相似度得到词语之间相似度,通过神经网络充分利用词语的全局语义,进一步提升主题挖掘效果。
近年来,终身机器学习在自然语言处理领域展现出了优异性能,终身机器学习方法也逐渐应用于主题挖掘任务中。最初提出的经典终身机器学习主题模型是LTM[7],为了解决上文提出的问题,研究者在LTM 的基础上进行了一系列的改进,提出了新的终身机器学习主题挖掘模型,主要分为基于概率LDA 的主题模型、基于矩阵分解的模型和基于神经网络的模型。
基于概率LDA 的主题模型的特点是使用概率方法进行抽样,如通过广义波利亚瓮(Generalized Polya Urn,GPU)等抽样模型来获取并利用先验知识。文献[8]将终身机器学习主题模型应用于主题挖掘与评分预测中。文献[9]提出了能够自动生成强关联词对和不可关联词对的主题模型(topic modeling with Automatically generated Must-links and Cannot-links,AMC)模型,在LTM 已引入mustlink 的基础上,增加了对cannot link 的考虑,提升了模型在小样本数据集上的效果,但该模型存在的一个问题是不能通过迭代来提高模型性能。文献[10]将终身机器学习模型应用于越南语的文本分类,取得了较好的效果。文献[11]将基于Word2vec 的词嵌入应用到模型中,提出了潜在嵌入结构终身机器学习模型(Latent-embedding-structured Lifelong Learning Topic Model,LLT),该模型存在的缺点是实现较为复杂,且没有使用外部语料集进行增强。文献[12]提出一种基于终身机器学习的连续学习方法,该方法从多领域语料库中的过去结果中学习,以帮助识别当前领域中的主题通用词。本文的改进模型也是属于基于概率的主题模型。
文献[13]将非负矩阵分解加入到终身机器学习中,使模型具备了终身学习的能力。文献[14]为了克服域内语料库数据的多样性问题,提出了基于非负矩阵分解的终身协作模型(Lifelong Collaborative Model,LCM),用来准确学习主题和特定领域的单词词嵌入信息,同时利用知识图谱来积累主题模型发现的全局上下文信息和先前领域的上下文词嵌入所反映的局部上下文信息。
神经网络也被应用于终身机器学习主题挖掘领域。在文献[15]中,神经网络类模型被用于知识的提取和利用,其中有监督负载平衡自组织增量神经网络(Load-Balancing Self-Organizing Incremental Neural Network,LB-SOINN)被用来选择当前任务中最重要的训练样本。变分表示学习(Variational Representation Learning,VRL)不仅从当前训练任务中提取知识,而且还为LB-SOINN 提供适当的隐藏表示作为输入。文献[16]将神经网络应用到终身机器学习中,提出了终身神经主题模型(Lifelong Neural Topic Model,LNTM),用以克服稀疏性数据带来的问题。然而,神经网络类方法普遍存在的一个缺点是模型可解释性低。
终身机器学习架构如图1 所示,主要包含任务管理器、基于知识的学习器、知识库(Knowledge Base,KB)等部分,并通过这些核心部分实现知识的迁移和整合。任务管理器对不断到来的任务进行调度,用知识库中的数据来增强学习器对当前任务的学习,实现迁移学习。学习完成后会输出结果,其中的有效信息会被保存在KB 中,知识库中的知识会随着学习进行更新,实现对知识的整合。

图1 终身机器学习架构Fig.1 Lifelong machine learning framework
基于概率和采样器类的终身机器学习主题挖掘方法通常将GPU 模型引入到LDA,通过对当前词语采样来获取先验知识,其先通过频繁项挖掘生成先验知识集,再使用吉布斯采样为词指定一个主题。然后利用点间互信息(Pointwise Mutual Information,PMI)计算两个词语在当前领域下的关系,并通过式(1)更新两个词语的关联度矩阵。同时,利用PMI对吉布斯采样过程中的错误知识进行识别和处理。

在实际计算中,P(w)按词语w在所在领域D的document 中出现的次数来计算,而P(w1,w2)则表示w1和w2在D中同时出现的次数。
PMI 值若为正数,说明两个词语正相关,值越大越有可能属于一个主题,若为负数说明两个词语负相关。LTM 本身还对LDA 中的简单波利亚瓮(Simple Polya Urn,SPU)进行了改进,得到了GPU,每次从瓮中抽取出一个词语w,放回时除了词语w本身,还有一定数量和w相关的词语也会被放入瓮中,以此提高w以及和它相近词语在主题(瓮)中的比例,具体计算如式(2)所示,其中μ用来控制PMI 的影响程度,矩阵表示的是每个和w相关的词语w"被加入GPU 瓮中的个数。

3.1 Hellinger 距离
Hellinger 距离最早由Ernst Hellinger 在1909 年提出。在统计学中,Hellinger 距离被用于计算两个分布的相似性,利用该特性,Hellinger 距离已经被应用于入侵检测[17]、不平衡数据分类[18-19]以及主题模型的相似度衡量中[20]。如在文献[21]中,Hellinger距离被用于相似度的衡量。相比其他距离计算方法,Hellinger 距离具有以下优势:相较于KL 散度,其定义了概率分布的真实度量;
相比Wasserstein 距离,其计算更加简单;
其还具有可以利用的几何特性。因为主题本质上是词语的概率分布,所以实验中使用概率分布之间的相似性进行相似主题的判断。相比LTM 模型中使用的JS 散度,Hellinger 距离在能取得相近效果的基础上,减少了计算时间,不用在计算JS 散度时计算两次KL 散度。
对于概率分布P={pi},Q={qi},从欧几里得范数来看,两者之间的Hellinger 距离计算如式(3)所示:

LTM 模型存在的一个问题是,其在执行新的学习任务时,默认所有的领域都和当前领域相关且有用,会从所有领域中获取知识,这种缺乏足够针对性的方式会导致计算量的增大。当有的领域和当前领域相关度不大时,还可能会从中学习到不合适的知识,影响知识提取的效果。实际应该选择和当前领域相似度较大的领域并从中获取需要的信息。得到领域主题之后,可以通过领域之间主题的相似度,推断出领域之间的相似度,帮助后续最近领域的选择。领域之间的距离计算如式(4)所示,其中D1和D2分别代表两个不同的领域,t1和t2则代表两个领域下的主题。

3.2 Word2vec 词向量
词向量技术由MIKOLOV 等[22]提出,是一种较新的词语表示技术。关于使用词向量对概率类主题模型进行改进,文献[23-24]利用外部数据库词向量来对LDA 模型进行改进;
文献[25]对词向量在概率类主题模型上的应用进行了总结;
文献[26]在生成的Word2Vec 词向量基础上,将其和单词贡献度进行融合,最终提高了文本分类的准确度。可以看出,利用外部词向量方法改进主题模型具有有效性。通过对全部领域语料的训练,Word2vec 模型能够更全面地表示词语之间的联系,这对于原模型中基于单一领域的概率分布词语表示方法是一个很好的补充。实验中使用的是Gensim 框架中基于Skip-Gram 算法进行训练的Word2vec 模型。Word2vec 模型可以非常方便地训练文本然后生成词向量,并控制词向量生成的维度。
Word2vec 模型可以通过计算词语的词向量得到两个词语之间的相似度,其计算如式(5)所示,其中va、vb是wa和wb分别对应的词向量。相比于曼哈顿距离,使用余弦相似度来计算词向量之间的相似性,可以更多地从方向的角度对向量相似性进行衡量。这里的计算对象是词语的词向量,而在上文Hellinger 距离的计算公式中,被计算的对象是主题下词语的概率分布。在获得所有相关度较大的领域中的主题后,还需要找到符合条件的主题,对有用的知识进行保留。词向量下主题之间的距离计算如式(6)所示。其中tn和tm指两个主题,N和M分别代表各自主题下词语的个数,vi和vj分别代表词语对应的词向量。

3.3 HW-LTM 模型框架与步骤
改进后的模型框架如图2 所示。从改进后的模型来看,主要是增加了Word2vec 词向量生成模块,然后用Hellinger 距离和词向量的余弦距离对主题间的距离进行了计算。

图2 改进模型框架Fig.2 Framework of the improved model
HW-LTM 模型主要包含以下步骤:
步骤1对外部语料进行分词和去除停用词等预处理操作。
步骤2通过Gensim 中的Word2vec 模型获得外部语料集中的词语(总个数为n)的Word2vec 词向量,在保证效果和计算速度的前提下,维度设置为200 维,并生成相应的词语词向量矩阵Mn×200,再在M的基础上按照式(5)进行计算,得到词语相互之间的相似度矩阵Sn×n,并将矩阵S保存为文件。
步骤3从知识库中获得上轮学习的各个领域下的主题概率分布。
步骤4在步骤3 的基础上,通过式(3)中Hellinger 距离计算主题之间距离来间接反映主题之间的相似度。
步骤5当前主题的主题词之间的向量距离可通过读取矩阵S得到,然后通过式(6)以全排列的方式计算词语之间的余弦相似度,最终可以得到主题之间的相似度。
步骤6判断步骤4 和步骤5 的结果是否符合相应的阈值,进而获得满足条件的和当前领域相近的主题。将该主题加入到簇中,然后从该簇中进行频繁项挖掘,得到当前领域下更优的主题。
步骤7重复步骤3~步骤6,直到模型达到指定迭代次数使得迭代训练挖掘后的效果更好。
4.1 数据预处理
对于网上爬取的数据,一种商品的评论被看作是一个领域,因为一条评论可能包含多条句子,首先需要根据句号、感叹号等符号标志进行分句,每个分好的句子就是一个document。对于分好的句子,需要根据停用词表去除停用词,同时对于在整个领域中出现次数小于3 次的词语也需要去除。
4.2 数据集
目前,终身机器学习主题挖掘方法在英文数据集上的研究较多,但在中文数据集上的研究极少,本文主要探究其在中文数据集上的实际效果,因此使用中文京东商品评论数据集。该数据集为从网页上爬取的中文京东商品评论信息,包含39 个商品类别,其中商品类别又被称为领域(domain),每个商品类别包含1 500 条该商品的评论,其中有33 个类别是电子类商品评论,另外6 个类别是服装类的商品评论。
4.3 Baseline 模型
实验中使用的对比模型包括经典的概率类主题模型LDA,以及终身主题模型LTM 和AMC。
LDA 模型:非常经典的一个主题挖掘模型,背景基础为数学概率模型,利用先验分布对数据进行似然估计并最终得到后验分布,为孤立学习方式的无监督模型。
LTM 模型:终身机器学习主题挖掘模型,在LDA 模型的基础上进行改进,吉布斯采样知识的方法由SPU 改进为GPU。其将终身机器学习相关理论知识应用在主题挖掘模型上,根据词对的关联性强弱,提出了must-link 的概念,将must-link 词汇作为知识供模型学习。
AMC 模型:LTM 的改进模型,在LTM 模型must-link 的基础上增加了cannot-link 来表示词语之间的关系,增强了对于关联度不大的知识的识别以及对小样本数据的处理能力。
相关实验参数设置:LTM、AMC 模型的参数设置和原论文一致。对于HW-LTM 模型,其相关的系数根据实际情况进行了调整,其中GPU 的控制系数μ设置为0.6,式(4)中Hellinger 主题距离的阈值θ1设置为0.8,式(6)中主题词向量距离阈值θ2设置为100,生成的主题数和每个主题下的词语数量K都设置为15。
实验的工作平台安装了java 1.8 和python3.7.6运行环境。CPU AMD R7 4800H@2.9 GHz,8 核心16 线程,16 GB 运行内存。
4.4 时间复杂度和空间复杂度分析
从时间复杂度的角度对HW-LTM 模型进行分析。对于主题之间相似度的衡量,原模型LTM 使用的是JS 散度,其计算如式(7)所示,其中P、Q为两个分布。该计算方法的缺点是需要计算两次KL散度,但相比JS 散度在时间复杂度上下降了一半。从模型增加的时间来看,HW-LTM 因为需要计算词向量之间的距离,会有一些时间开销,同时还会存在两个词语之间的重复计算问题。实际实验中发现S矩阵的生成开销相对模型整体时间开销可忽略不计。为解决重复计算带来的开销问题,本文采用预加载的方法,在HW-LTM 模型开始运行时便把已经提前计算好的矩阵S加载到内存中,在寻找两个词语相似度值时达到O(1)的时间复杂度,以此减少重复计算的时间。

改进前后的模型在空间复杂度上的区别主要在于本实验所用的有大约5 000 词的京东商品评论数据集,空间代价是在预加载时需要大约95 MB 的内存空间。
4 轮迭代运行完成后各模型所花费的时间如表1 所示。LDA 和AMC 模型由于没有迭代学习过程,在运行速度上排名靠前;
HW-LTM 相比基于Hellinger 距离的终身主题模型(Hellinger Distance based Lifelong Topic Model,HD-LTM)多了外部词向量的加载以及词向量余弦相似度的计算过程,速度相对稍慢,但相比原模型LTM,HW-LTM 在缩短运行时间上仍旧取得了较大的进步,耗时缩短了43.75%。

表1 不同模型在京东商品评论数据集上运行时间的对比Table 1 Comparison of running time of different models on JD commodity review dataset
4.5 模型对比评估
本文采用主题关联度topic coherence 评估方法进行评估。经过相关测试,这是一种较为优越的评估方法,和人类专家实际判断结果更加接近,且能够得到比困惑度更好的实际效果,其计算如式(8)所示:

对于主题uk中的词语,topT 指主题uk下词语个数。式(8)中分子代表在所有的document 中两个词语和共同出现的次数,分子上加一是为了进行平滑。类似的,分母表示在所有文本中词语出现的次数。对所有的主题都进行上述操作并累加求和,得到该领域下最终的topic coherence 值。topic coherence 的值越大,表示主题中词语的关联度越大,主题模型的挖掘效果越好。挖掘出的主题如表2 所示,其中共有15 个主题,每个主题下有15 个词。从中可以看出主题下的词语存在一定的关联性,如Topic4 主要是物流方面的词语,Topic10 则体现的是对衣服款式的总体满意态度。

表2 HW-LTM 模型主题挖掘结果Table 2 Topic mining results of HW-LTM model
HW-LTM 模型(同时使用了Hellinger 距离和词向量进行改进)和LDA、LTM、AMC、HD-LTM(只用Hellinger 距离进行改进)模型在京东商品评论数据集上的topic coherence 对比如图3 所示。
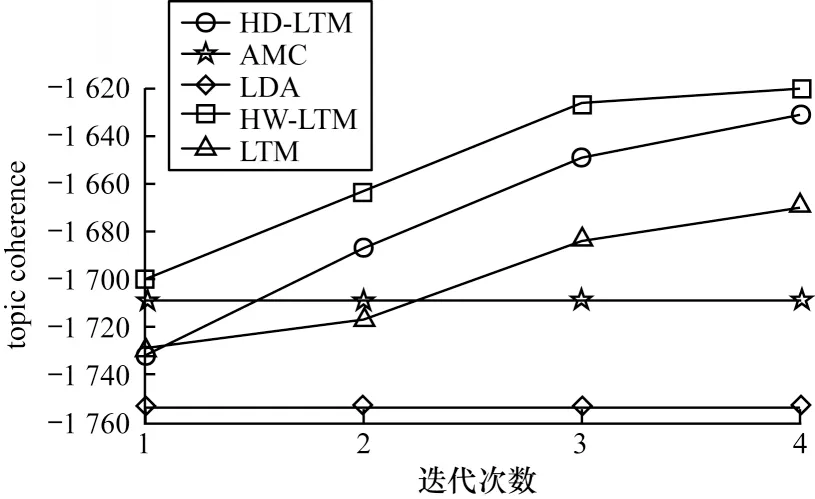
图3 京东商品评论数据集实验结果Fig.3 Experimental results of JD commodity review dataset
由图3 可以看出:LDA 模型和AMC 模型没有迭代操作,因此其评估结果为一个固定值;
LTM 模型和HW-LTM 模型有迭代学习功能,其挖掘效果随着迭代轮数增加逐渐提升;
LTM 模型在第一轮迭代不如AMC,但随着时间的推移,不断迭代提升,后面几轮效果超过了AMC 模型;
HW-LTM 模型由于在主题选择时使用了外部词向量来帮助获取有效知识,加快了收敛速度,相比LTM 模型每轮学习平均提升了48 个百分点,相比AMC 模型同样也有较大提升。
为探究终身机器学习方法在不同领域知识之间相互学习的能力,做进一步的实验。图4是对数据集中服装领域商品生成的主题进行评估后的结果,图5则是对电子产品领域生成的主题进行评估后的结果。

图4 服装领域实验结果Fig.4 Experimental results in the field of clothing

图5 电子商品领域实验结果Fig.5 Experimental results in the field of electronic commodities
通过对比图4 和图5 可以发现:尽管服装领域的类别较少,但通过对其他领域有用知识的学习,同样使得该部分主题挖掘效果得到提升;
而电子类商品拥有33 个类别,其相互之间能学习到的知识更加充分,因而整体效果要好于服装领域的情况。由此可见,相关领域类别的评论数量对终身机器学习的实际效果有影响。
综合来看,AMC 模型在小样本上具有优势,但在本实验的中文大样本评论数据中并不具有绝对性优势。从5 种模型的对比中可以看出,经过Hellinger 距离和Word2vec 方法改进的HW-LTM 模型,效果已经超过了最初的LTM 模型,也超过了经典的LDA 方法。
本文针对终身机器学习主题挖掘模型LTM,从主题之间相似度和词向量相似度两个方面进行优化,提出HW-LTM 模型实现更准确的知识提取。通过在京东商品评论数据集上进行实验,验证该模型在中文上的有效性。实验结果表明,领域选择以及词向量的相似度计算能有效提高模型的主题挖掘效果。但目前词向量在模型中的应用还较为局限,下一步将探索更高效的词向量表示方法,如BERT、GloVe 等语言模型,同时对词向量在当前模型中的应用范围进行扩展。
猜你喜欢 向量机器词语 容易混淆的词语国际医药卫生导报(2022年18期)2022-09-29机器狗环球时报(2022-07-13)2022-07-13向量的分解新高考·高一数学(2022年3期)2022-04-28机器狗环球时报(2022-03-14)2022-03-14聚焦“向量与三角”创新题中学生数理化(高中版.高考数学)(2021年1期)2021-03-19找词语小天使·一年级语数英综合(2020年4期)2020-12-16未来机器城电影(2018年8期)2018-09-21向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23一枚词语一门静传奇故事(破茧成蝶)(2015年7期)2015-02-28








