基于阅读理解框架的中文事件论元抽取
时间:2023-06-05 10:55:30 来源:雅意学习网 本文已影响 人 
陈 敏,吴 凡,李培峰,王中卿,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
作为信息抽取(Information Extraction)中的重要子任务,事件(Event)抽取是指从描述事件信息的文本中识别并抽取出包含的事件信息,并以结构化的形式呈现出来。事件抽取任务一般分为两个步骤,触发词(Trigger)抽取和论元(Argument)抽取。触发词抽取是根据上下文识别出触发词并判断其事件类型(Event Type);
论元抽取是根据事件类型,抽取出参与事件的论元,并分配论元角色(Argument Role)。在ACE2005数据集中,定义了33种事件子类型(8种事件大类)和35种论元角色。例1给出了数据集中包含1个触发词和3个论元角色的事件句。触发词抽取部分需要识别出触发词E1,其对应的事件类型为宣判(Sentence)。论元抽取部分需要识别出参与宣判的论元并分配对应的角色。该事件的论元包括A1、A2和A3,分别对应角色法官(Adjudicator)、被告(Defendant)和判决结果(Sentence)。
当前中文事件抽取研究更多的是解决触发词抽取问题[1-4],而针对中文论元抽取的工作相对较少。
例1: 法官(A1)随即判(E1)被告(A2)7年预防性监禁(A3)。
Zeng等[5]利用CNN和Bi-LSTM捕获句子和词汇信息,然后把论元抽取视为实体提及的多分类任务。贺等[6]利用条件随机场(CRF)和多任务学习的框架,把论元抽取视为序列标注任务。尽管这种多分类或序列标注的方式被认为是事件抽取的一个很好的解决办法,但是这样的做法仍然存在问题,论元角色标签本身的语义信息和论元存在着重要关系,现有的研究工作并不能利用论元角色标签本身的先验信息。如例1中,判决结果(Sentence)这类论元角色出现频率较低,而这个类别在多分类或序列标注训练中,仅被视为交叉熵中的一个独热向量,这种不清楚抽取什么往往导致劣质的性能。
本文工作主要研究中文事件抽取中的论元抽取。针对论元抽取存在的上述问题,提出了基于BERT阅读理解框架的论元抽取方法,将论元抽取视为完型填空式的机器阅读理解(Machine Reading Comprehension)任务。该方法的总体流程如图1所示。如想要抽取的角色为判决结果(Sentence),通过回答问题“触发词是判,宣判的判决结果是什么?”来预测该角色对应的论元“7年预防性监禁”,从而实现对该论元的识别和角色分配。这样的方式可以编码论元角色的先验信息,能够有效抽取出论元角色类别较少的论元。
总的来说,本文的方法利用已知的事件模式信息,将不同事件类型下的论元特征表述为自然语言问题,论元通过在事件句的上下文中回答这些问题来完成抽取。该方法通过BERT预训练模型学习问题和句子的初始隐向量表示,利用双向GRU更好地学习句子的上下文特征,然后对每个字进行二分类确定论元的跨度,采用合理的规则优化论元跨度,最终利用已知的实体提及完成论元角色识别和分配。在ACE2005中文语料上的实验证明,本文提出的基于阅读理解框架的论元抽取方法,优于传统的多分类或序列标注的方法,验证了阅读理解方法对论元抽取任务的有效性。
本文组织结构如下: 第1部分介绍了论元抽取的相关工作;
第2部分详细描述了本文提出的模型;
第3部分介绍实验部分并进行了具体分析;
第四部分是总结和展望。
事件抽取一直以来都是自然语言处理研究者们关注的重点领域。大多数工作把事件抽取看成两个阶段的问题,包括事件触发词抽取和论元抽取。触发词抽取工作近年来已经取得了很大的发展,论元抽取成为了事件抽取发展的瓶颈。目前论元抽取相关研究大部分是面向英文文本,中文论元抽取的发展较为缓慢。
在英文上,传统的基于特征表示的方法依靠人工设计的特征和模式。Liao等[7]提出跨文档的方法来利用全局信息和其他事件信息。Hong等[8]充分利用了事件句中实体类型的一致性特征,提出一种跨实体推理方法来提高事件抽取性能。Li等[9]提出了一种基于结构预测的联合框架,合并全局特征,显式地捕获多个触发词和论元的依赖关系。随着神经网络的流行,研究者们开始利用预训练好的词向量作为初始化表示[10-11],进而建模单词的语义信息和语法信息。Chen等[12]对普通卷积神经网络做出改进,提出一种动态多池化卷积神经网络模型(DMCNN),把事件抽取看做两个阶段的多分类任务,先执行触发词分类,再执行论元分类,很好地解决了一个句子中包含多个事件的问题,但没有利用好触发词和论元之间的语义。Nguyen等[13]通过循环神经网络(RNN)学习句子表示,联合预测触发词和论元,增加了离散特征。为了捕获触发词和论元之间的依赖关系,引入记忆向量和记忆矩阵来存储在标记过程中的预测信息。Liu等[14]提出了一种新颖的联合事件抽取框架(JMEE),通过引入句法短弧来增强信息流动,以解决句子编码的长距离依赖问题,利用基于注意力的图卷积网络来建模图信息,从而联合抽取多个事件触发词和论元。Wang等[15]在DMCNN的基础上,提出了一种分层模块化的论元抽取模型,该模型采用灵活的模块网络(Modular Networks),利用了论元角色相关的层次概念作为有效的归纳偏置,不同论元角色共享相同的高层次的单元模块,有助于更好地抽取出特定的事件论元。
随着深度学习的进一步发展,一些先进的技术也被用于英文事件抽取,包括零样本学习[16]、远程监督[17]、BERT预训练模型[18]等。
相对于英文论元抽取,中文论元抽取工作发展较缓,中文需要分词、缺少时态等自身特点给该任务带来一定的挑战。尽管如此,近年来也取得了一些进展。传统方法更多地在挖掘语义和语法特征,很大程度上依赖于手工制作的特征和模式。Li等[19]引入形态结构来表示隐含在触发词内部的组合语义,提出了一个结合了中文词语的形态结构和义原去推测未知触发词的方法,明显提升了事件抽取的召回率。Chen等[20]利用局部和全局特征共同抽取触发词和论元。Zhu等[21]利用事件之间的关系来学习实体扮演特定角色的概率,提出了基于马尔可夫逻辑网络的事件论元推理方法。贺等[6]将事件抽取看作序列标注任务,并考虑到数据稀疏问题,对不同事件子类进行互增强,提出基于CRF的多任务学习事件抽取联合模型。神经网络发展起来后,Zeng等[5]提出了一种基于LSTM和CNN的卷积双向LSTM神经网络模型,利用Bi-LSTM和CNN分别编码句子级别信息和局部词汇特征。
随着预训练语言模型的发展,深度学习提高了许多自然语言处理的性能。很多自然语言理解任务可以转换为机器阅读理解任务[22],如文本分类、关系抽取、事件抽取、情感分析、文本蕴含、语言推理、语义角色标注等。机器阅读理解任务是从给定问题的段落中提取答案,将NLP任务转为阅读理解任务成为了新的趋势。Gardner等[23]提出了使用问答作为特定任务的格式的三种动机,即满足人类信息需求,探查系统对某些上下文的理解以及将学习到的参数从一项任务转移到另一项任务。Li等[24]将实体关系抽取视为一种多轮问答任务,为每种实体和关系生成不同的问答模板,这些实体和关系可以通过回答这些模板化的问题来进行抽取。Li等[25]提出使用机器阅读理解框架代替序列标注模型,统一处理嵌套与非嵌套命名实体识别问题,在这种情况下,文本中实体的提取被形式化为回答问题,如“文本中提到了哪个人?”
受Li等[25]工作的启发,本文提出了基于阅读理解框架的论元抽取方法。在标准的机器阅读理解设置中,给定一个问题Q={Q1,Q2,…,QNq},(Nq表示问题Q中的字数),上下文S={S1,S2,…,SNc},(Nc表示句子S中的字数),模型从给出问题的段落中提取答案跨度。该任务可以形式化为两个多分类任务,即预测给定问题的答案跨度的开始位置和结束位置。本文的方法也基于这种设置,该方法的流程和模型如图1和图2所示。
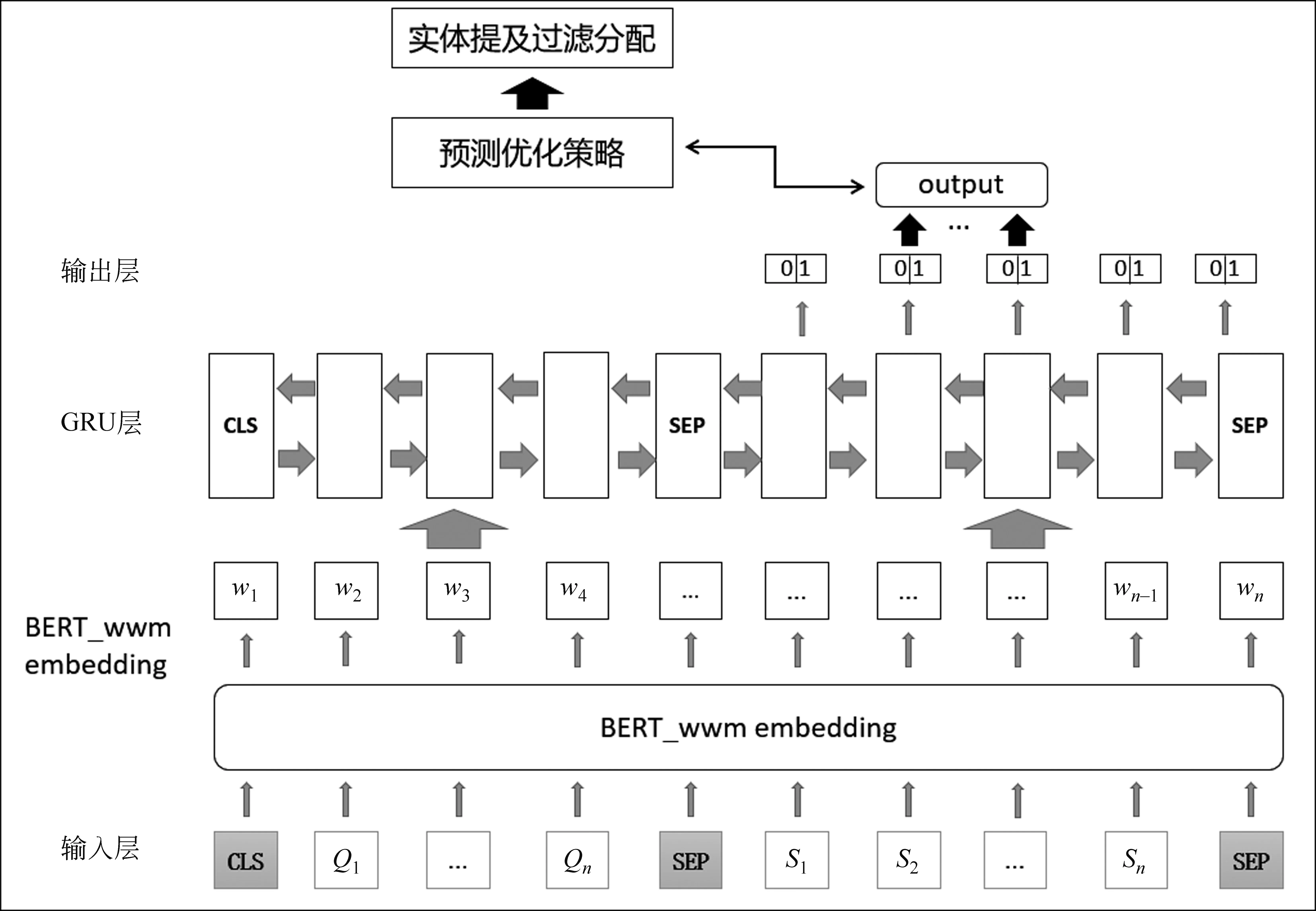
图2 基于阅读理解框架的论元抽取模型
论元抽取包含四个部分: ①输入层,②编码层,③跨度预测层,④论元分配层。结合模型图来看,其中,输入层按照机器阅读理解的设置, 利用本文采用的语料中的事件模式信息生成具有论元表征的问题和原句子作为初始输入表示;
编码层通过BERT预训练模型编码字级别特征,利用双向GRU学习序列特征;
跨度预测层根据编码层的输出, 对每个字进行二分类来确定答案的跨度;
论元分配层利用实体提及过滤抽取结果,最后给实体提及分配论元角色。
2.1 模型输入层
BERT模型的输入序列为句子对所对应的embedding。句子对包含问题和事件句,并由特殊分隔符“[SEP]”分隔。问题由具有论元表征的论元角色标签构成,事件句是触发词抽取结果中包含事件的文本。同BERT的其他下游任务一样,所有的输入序列的第一个token必须为特殊分类嵌入符“[CLS]”,同时输入序列为字向量、位置向量和句子向量之和。模型的具体输入形式如式(1)所示。
[CLS]...Question...[SEP]...Sentence...[SEP]
(1)
其中,问题表示的语义信息是很重要的,因为该方法中问题编码了关于论元角色标签的先验知识,并对最终结果有重大影响。本文利用事件模式信息,统计触发词对应事件类型存在的论元角色(这种对应是已知且确定的),试验了不同问题构成的效果。以3种事件类型为例,事件模式信息如表1所示,不同的问题模板如表2所示。

表1 事件模式表
表1中,Time-*表示与时间相关的论元角色,包括Time-Within、Time-Ending、Time-Starting等。表2以受伤事件类型对应的施事者(Agent)角色为例,模板1(伪问题)以论元角色为问题,问题设置为“施事者”;
模板2(触发词+伪问题)的加入触发词信息,句子中的触发词可以表示触发词信息和触发词位置特征,这也是模型可以学习到的重要特征,问题设置为“触发词是[Trigger]的施事者”(其中[Trigger]表示该事件类型对应的触发词);
模板3(触发词+自然问题)利用ACE2005中文语料库中的注释信息,根据事件类型和论元角色生成了更自然的问题,施事者(Agent)这一角色在受伤类型下扮演的是该事件下造成伤害的人,问题设置为“触发词是[Trigger],造成伤害的人是谁?”。本文的实验验证了模板3的问题设置最合理。

表2 不同的问题模板(以Injure事件为例)
2.2 模型编码层
编码层的主体包括BERT和GRU两部分。
BERT在自然语言处理领域具有里程碑的意义。BERT本质上是通过在大量语料的基础上利用自监督学习的方法为每个字或词学习一个好的特征表示。它使用Transformer捕捉语句中的双向关系,使用掩码语言模型(Masked Language Model,MLM)和下一句预测的多任务训练目标。MLM是指在训练时在输入语料上随机遮蔽(mask)掉一些单词,然后通过上下文预测该单词,这样的预训练方式能更好地表示语义特征。在谷歌发布的BERT版本中,中文是以字为粒度进行切分,没有考虑到传统NLP中的中文分词。本文采用哈尔滨工业大学发布的改进版本[26](BERT-wwm)进行编码,将全词mask的方法应用在中文中,即对同属于一个词的汉字mask而不是对单个字的mask。同BERT-base一样,该模型采用12个Transformer Encoder堆叠而成的结构,每一层使用12个独立的注意力机制,包含768个隐层向量。注意力层增加多头注意力机制(Multi-Head Attention),扩展了模型专注于不同位置的能力。多头注意力模块的计算如式(2)~式(4)所示。
多头注意力机制用来学习每个字与其他字的依赖关系和上下文语义,然后通过前馈神经网络对Attention计算后的输入进行变换,最终得到序列的全局信息。对于给定的输入序列X={x1,x2,…,xn},编码层BERT部分的输出是最后一层Transformer的隐层向量,表示为W={w1,w2,…,wn}。为了更好的地学习句子上下文的序列特征,将BERT部分的输出再经过一个双向GRU模型,它可以继承BERT的优点,同时捕获序列语义信息,获取序列的长距离依赖。双向GRU分别从正反两个方向对BERT的输出进行编码,各自得到一个隐层输出,前向GRU层表示如式(5)所示。
(5)
后向GRU层表示如式(6)所示。
(6)

2.3 跨度预测层
跨度预测层接收编码层的隐层向量矩阵,答案跨度的预测主要包括开始位置和结束位置的确定,如果答案为空,把BERT输入层的第一个token“[CLS]”作为正确答案。模型在微调期间需要学习的参数就是每个token作为答案开始位置(start span)和答案结束位置(end span)的向量,隐层向量经过softmax归一化后进行多个二分类,来获得每一个token分别作为开始位置和结束位置的概率,采用概率最高的区间作为预测结果。具体的计算如如式(7)~式(10)所示。
其中,E(E∈n×d,),n为序列的长度,d为编码层的输出维度)是编码层输出的隐层向量矩阵;
T(T∈d×2)即为需要学习的新参数;
P(P∈d×2)为输出概率;
I(I∈[0,n-1])为输出索引。
实验中采用二类交叉熵作为损失函数,在训练过程中,使用Adam优化器优化模型参数,通过最小化交叉熵损失完成训练调优,二类交叉熵具体计算如式(11)、式(12)所示。
其中,N表示序列的长度;
yi表示样本i预测为正的概率;
Lstart和Lend分别为开始位置和结束位置的损失。
2.4 论元分配层
此外,该部分增加了优化策略,用以解决实体不完全匹配的问题。根据标准结果,匹配特定长度的相同开头或结尾的最长实体作为优化后的抽取结果。例如,在标准结果中的实体提及为“26岁”“人”,预测结果分别为“26岁的时候”“全家人”。这样的抽取结果也可以判定为正确的抽取。经过预测优化策略后,再根据实体分配不同的论元角色,最终提高论元抽取的性能。
3.1 实验数据与评价方法
本文实验基于ACE2005中文语料库,包含新闻专线、广播、微博等数据。每条数据包含触发词、实体、论元角色标签等标注信息。本文采用文献[6,21]相同的数据划分方法,从语料库中随机抽取567篇文档作为训练集,66 篇文档作为测试集,并保留训练集中的 33 篇文档作为开发集。评判的标准同前人工作一样,一个论元被正确识别当且仅当该论元在文本的位置和类型与标准标注文档中的候选论元的位置和类型完全匹配。采用精确率(P),召回率(R)、F1值作为本文的评价指标,具体计算如式(13)~式(15)所示。
其中,TP为担任角色的实体被正确识别出的个数,FP为角色为None的实体被错误识别的个数,FN为担任角色的实体被错误识别的个数。
3.2 实验参数设置
本文采用哈工大版本的BERT预训练模型(BERT-wwm),其参数字向量维度为768,Transformer层数为12,实验的相关参数设置如表3所示。

表3 实验参数设置表
3.3 实验结果与分析
本文工作是针对论元抽取任务,触发词抽取不是重点工作。论元抽取的工作是基于触发词抽取的结果来做,本文的触发词抽取模型利用BERT微调[4]的结果,其事件类型分类的精确率(P)为73.9%,召回率(R)为63.8%,F1值为68.5%。
本文主要进行了两组实验对比,一是将本文提出的方法与基准系统进行对比实验,二是设置不同问题策略的对比实验。
3.3.1 与基准系统的对比
本文将提出的基于阅读理解框架的方法与现有的论元抽取方法进行了对比。结果如表4所示。

表4 论元抽取实验结果 (单位: %)
•Rich-C[20]: Chen提出的基于特征的模型,该模型针对中文的特殊性开发了一些手工特征,以共同提取事件触发词和论元角色。
•JRNN[13]: Nguyen提出的一种基于神经网络的模型。它利用双向RNN和手动设计的特征来实现论元抽取。
•C-BiLSTM[5]: Zeng提出的一种结合LSTM和CNN的卷积双向LSTM神经网络来捕获句级和词汇信息,把论元抽取看成多分类任务的方法。
•MTL-CRF[6]: 贺提出的基于CRF的方法,设计了一个有效挖掘不同事件之间论元相互关系的多任务学习的序列标注模型,联合标注触发词和论元,降低了管道模型带来的级联错误,并没有利用复杂的神经网络,其精确率有明显的提升,但召回率较低。
•DMBERT[27]: Wang提出的有效利用预先训练语言模型的方法并使用动态多池化方法来聚合特征。它不同于DMCNN的是利用BERT提取字级别信息和句子信息,获得了较大的性能提升。本文复现了该模型,作为BERT基准。为了公平比较,触发词抽取部分沿用本文的触发词基准结果。
•MRC-EAE: 即本文提出的基于BERT并结合双向GRU的阅读理解模型,本文把传统的论元抽取任务建模成SQUAD风格的机器阅读理解任务,使用了BERT编码问题和句子信息,利用了论元角色的先验信息,同时使用GRU学习句子序列特征。
从表4中的实验结果可以看出,本文提出的基于阅读理解框架并结合双向GRU的方法优于其他方法。对比多任务学习的序列标注方法MTL-CRF和基于BERT的动态多池化模型DMBERT,本文提出的方法在召回率和F1值上有明显提升,召回率分别提升了8.2%和4.5%,F1值分别提升了1.3%和1.6%。传统的MTL-CRF方法联合抽取触发词和论元,虽然可以降低级联错误,但是这种联合训练的序列标注增加了很多标签,致使类别稀疏,导致召回率较低。同样,在多分类任务DMBERT中,论元角色较少的类别很难被识别出。而本文提出的方法利用BERT和双向GRU编码,BERT的多头注意力机制和两句输入能充分获取输入文本的语义信息,将问题和句子之间的语义关系充分捕捉,并在句子中获取最终的答案位置。这种阅读理解的方法能够通过问题编码了论元角色的先验信息,这是以往工作中没有利用的重要特征。由于引入了论元角色的先验信息,可以有效地识别出角色较少但是标签有语义区分的类别,如交通工具(Vehicle)、原告(Plaintiff)、卖方(Seller)等。表5给出了5个低频论元在DMBERT和本文方法的结果对比,从结果可以看出,本文提出的方法在这几种少类别的角色标签上有明显的性能提升,更加验证了该方法的有效性。

表5 低频论元角色对比结果 (单位: %)
3.3.2 阅读理解方式不同策略的对比
为了验证编码不同论元角色标签的先验信息对模型的影响,本文设置了不同问题模板并进行了消融实验,问题模板设置在第2节给出。实验对比结果如表6所示。

表6 不同的策略对比结果 (单位: %)
模板1的问题设置仅代表论元角色的 语 义,在多事件类型的句子中,模型不能正确抽取对应事件类型的论元;
模板2的问题设置方式加入了触发词,可以表示句中需要抽取论元具体的触发词语义和触发词的位置信息,但对于论元的描述不够具体;
模板3生成了更自然的问题,这种提问策略在加入触发词信息的同时融合事件类型信息和论元角色先验信息。
从表中实验结果可以发现,性能最好的问题模板3相比模板1和模板2在F1值上分别提升了3.2和1.7。当模板3的问题设置去掉触发词时,性能下降了2.2,这说明触发词信息的加入可以有效地判断答案的位置和与触发词关系更紧密的论元。此外,在模板3的基础上,对抽取的结果进行优化,在F1值上能提升0.7;
同时利用双向GRU的双向学习序列信息的能力,更好学习输入中问题与句子上下文的关系,在结果优化的基础上F1值提升了0.3。
3.3.3 错误分析
对实验结果进一步分析发现,本文提出的方法仍存在不足之处。一方面,本文利用的事件模式信息,存在某些事件句缺失论元角色的情况,即有的问题的答案为空,这种情况下模型往往会被错误预测。如“法官随即判被告7年预防性监禁”这一句中并不包含时间相关论元,但是实体提及“7年”会被模型误认为是时间的角色。另一方面,如果一个事件句中某个事件类型存在多个相同的论元角色,受限于本文阅读理解模型的设置,只能识别出其中的一个作为正确答案。如“而就在吕传升接受记者访问的时候,突然接到了吕秀莲打来的电话,要吕传升暂时封口。”,句中包含两个会面对象(Entity)——“吕传升”和“记者”,模型往往只能学习到“吕传升”这个论元而忽略“记者”。
本文采用的基于阅读理解模型的论元抽取方法,把该任务形式化为回答不同的问题来实现不同论元角色的识别和分配,通过优化问题的质量来提升问题回答的性能。通过反复实验证明,这种完型填空式的抽取方式比基准模型有了明显的性能提升,也能适用于事件抽取任务。然而,本文的工作是基于句子级别的论元抽取,缺失了段落信息的句子往往丢失了很多重要的上下文信息。在下一步的研究工作中,还可以考虑基于篇章层面的阅读理解方式来提升论元抽取的效果。
猜你喜欢 编码模板模型 铝模板在高层建筑施工中的应用建材发展导向(2022年23期)2022-12-22高层建筑中铝模板系统组成与应用建材发展导向(2022年20期)2022-11-03铝模板在高层建筑施工中的应用建材发展导向(2022年12期)2022-08-19适用于BDS-3 PPP的随机模型导航定位学报(2022年4期)2022-08-15生活中的编码小学生学习指导(中年级)(2021年12期)2021-12-30重要模型『一线三等角』中学生数理化·七年级数学人教版(2020年10期)2020-11-26Inventors and Inventions考试与评价·高二版(2020年2期)2020-09-10《全元诗》未编码疑难字考辨十五则汉字汉语研究(2020年2期)2020-08-13子带编码在图像压缩编码中的应用电子制作(2019年22期)2020-01-14Genome and healthcare疯狂英语·新读写(2018年3期)2018-11-29






