结合RoBERTa和BiSRU-AT的微博用户情感分类研究袁晓容1,,张丹2
时间:2023-05-29 08:45:08 来源:雅意学习网 本文已影响 人 
(1.湖南都市职业学院, 计算机科学系, 湖南, 长沙 410137;
2.湖南信息学院, 通识学院, 湖南, 长沙 410151)
随着微博、贴吧等社交平台的快速发展,越来越多的用户在网络上发表带有情感倾向的评论。情感分类是指自动提取出用户对某事物的褒贬意见,属于文本分类问题[1]。
将离散的词转化为机器能够处理的数字是深度学习方法应用于情感分类任务的关键前提。传统的词向量模型如Word2Vec[2]和Glove[3]利用预训练技术将文本映射到高维向量,但训练过程缺乏词的位置信息和未能结合词的上下文语境,存在无法表示多义词的问题。通过对预训练技术的深入研究,动态词向量学习模型如ELMO[4]和基于Transformer的BERT[5]模型等被相继提出。RoBERTa[6]预训练模型作为BERT的改进版本,提出了动态掩码预训练,在多个自然语言处理任务上取得了最佳效果。
传统的机器学习方法有支持向量机、最大熵和k近邻算法等,但机器学习方法需要进行复杂的人工准备,无法保证选取特征的全面性和准确性。随着深度学习方法的发展,基础的深度模型如卷积神经网络(CNN)、长短期记忆网络(LSTM)等被广泛应用于文本分类任务。文献[7]针对安全事件实体识别任务,提出了RoBERTa-BiLSTM模型,采用中文预训练模型进行动态词向量学习,BiLSTM进行二次上下文信息抽取,取得了不错的效果,但BiLSTM参数较多,训练速度较慢,并且模型无法识别对分类结果较为重要的特征。文献[8]提出了ALBERT-CRNN模型,用于对弹幕文本进行情感分析,CRNN考虑到文本中的上下文信息和局部特征,但其中最大池化技术存在部分语义损失问题,未能充分考虑到全部词对分类结果的影响力。注意力机制[9]最早在机器翻译领域被提出,后续研究致力于将注意力机制与基础深度模型进行有机结合。文献[10]提出了基于ERNIE2.0-BiLSTM-Attention的隐式情感分析模型,Attention模块能够赋予模型聚焦关键词的能力,有助于提升模型分类性能。
针对目前研究仍然存在的问题,本文提出结合RoBERTa和BiSRU-AT的微博用户情感分类模型,主要贡献和创新点如下:
1) 采用RoBERTa预训练模型通过参考词的上下文语境,学习到动态词向量表示,解决静态词向量无法表示多义词问题,提升词的表征能力。
2) 为解决BiLSTM模型训练速度慢问题,采用双向简单循环单元(bidirectional simple recurrent unit, BiSRU)提取微博文本上下文信息特征,降低模型训练花费时长。
3) 引入软注意力机制计算每个词对分类结果的重要程度,对情感分析结果影响越大的词得分越高,赋予模型聚焦重要词的能力。
1.1 模型结构
情感分类模型结构如图1所示,主要由数据预处理、RoBERTa模型、BiSRU二次语义提取层和软注意力机制、分类层构成。数据预处理负责除去微博用户情感数据集中的无语义字符;
RoBERTa模型通过参考语句上下文含义,得到词的动态语义表示;
BiSRU二次语义提取层负责学习词的上下文特征;软注意力机制负责计算不同词对分类结果的影响大小,从而得到相对应的权重;
最后通过分类层得到情感分类概率分布。
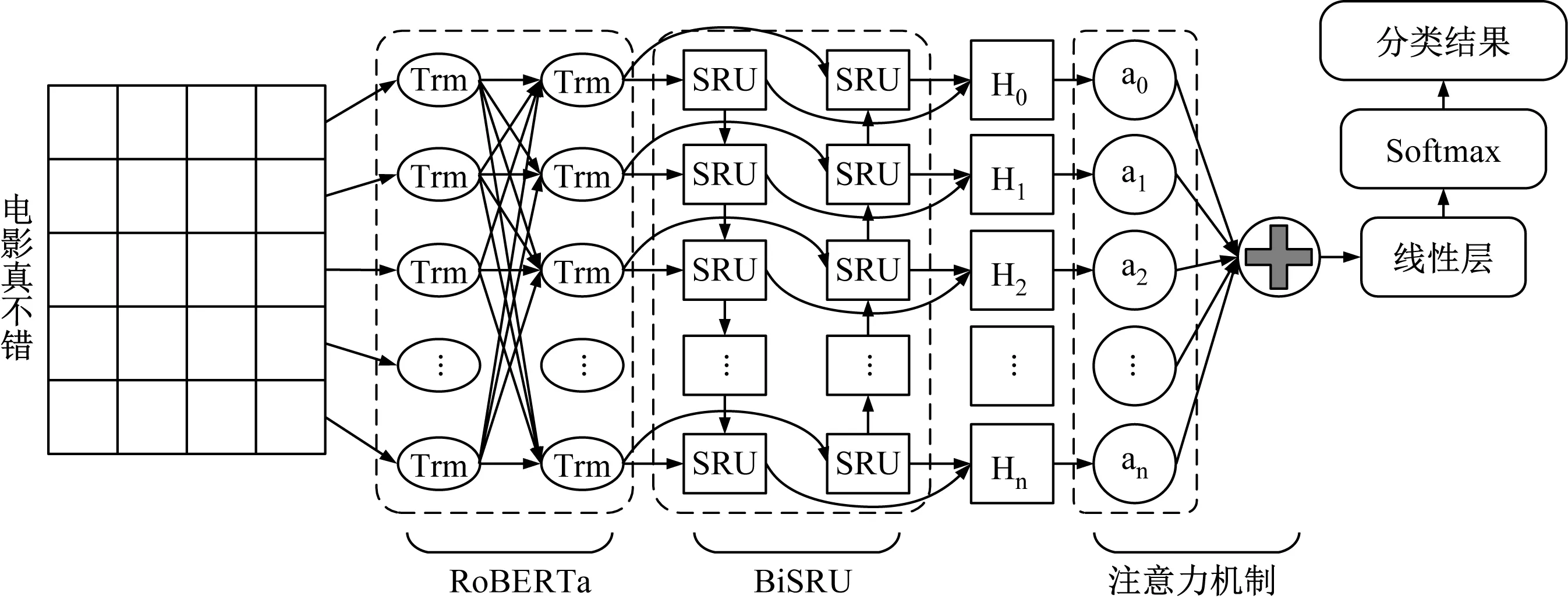
图1 模型整体结构
1.2 数据预处理
微博用户情感数据集存在较多无语义的特殊字符和表情符号,需要采用特定的正则表示式对数据进行清洗,去除特殊字符和符号,保留具有语义的字。利用RoBERTa模型自带的分词器对句子进行字级别的分词,并根据词汇表将字转化为相应序号。同时,根据最大序列长度对句子进行补0或者截断操作,并保留句子前后位置,用于存放句首标志[CLS]和分句标志[SEP]。以上操作得到词的静态语义表示,作为RoBERTa模型的输出之一。
1.3 RoBERTa预训练模型
RoBERTa模型基于具有强大特征抽取能力的Transformer编码器,其核心部分自注意力机制可对任意长度之间的词进行关系建模,捕捉到句子内部的语法结构和词与词之间的依赖关系。RoBERTa模型结构如图2所示。

图2 RoBERTa模型结构
其中,e=(e1,e2,…,en)为RoBERTa模型的输入,t=(t1,t2,…,tn)为训练得到的词的动态语义表示,e由字符向量、位置向量和分句向量构成,字符向量为静态字符表示。由于Transformer无法得到词的位置信息,因此加入位置信息表示词所在句子中相对位置。本文为微博用户情感分类,因此属于单句分类任务,因此仅使用一个分句向量。
1.4 BiSRU和软注意力机制
简单循环单元(SRU)作为LSTM的一种轻量级变体,摆脱了对上一个时间步状态输出的依赖,在保持高效建模能力的条件下,具有高速并行能力,缩短了模型训练时间。SRU模型结构如图3所示,计算过程见式(1)~式(4)。

图3 SRU结构
ft=σ(Wfxt+vf⊙ct-1+bf)
(1)
rt=σ(Wrxt+vr⊙ct-1+br)
(2)
ct=ft⊙ct-1+(1-ft)⊙(Wxt)
(3)
ht=rt⊙ct+(1-rt)⊙xt
(4)
其中,Wf、Wr、W、vf、vr、bf和br为可学习参数,ft、ct、rt和ht分别代表遗忘门、t时刻隐状态、重置门和t时刻状态输出,⊙表示元素乘法。由式(4)可知,模型计算摆脱了对上一个时间步ht-1的依赖,加强了并行计算能力。
句子语义不仅与上文信息相关,也跟下文信息联系密切,因此搭建双向SRU进一步提取句子语义信息。BiSRU由正向和反向SRU构成,将正反向SRU每个时间步的输出合并得到BiSRU输出,计算过程如式(5)。Tt为RoBERTa模型输出的行向量。
Ht=BiSRU(Tt)
(5)
将BiSRU的输出Ht送入软注意力层,利用zt计算句子每个词的输出隐状态权重大小at,最后将每个时间步输出Ht与对应权重系数at相乘求和之后得到注意力特征表示A。计算过程如式(6)~式(8)。
zt=tanh(wzHt+bz)
(6)
(7)
(8)
其中,tanh()函数为zt加入非线性因素,exp()为指数运算。
经软注意力机制计算后,将注意力特征A映射到实例空间S,通过Softmax函数得到情感分类概率分布P,由top()函数获取行最大值对应的标签为分类结果R。计算过程如式(9)、式(10)。
P=Softmax(WA+b)
(9)
R=top(P)
(10)
2.1 数据集与评价标准
实验数据集采用新浪微博用户评论文本数据集,共119 988条标注数据,正向评论59 993条,负向评论59 995条,并按照98∶1∶1划分训练集、测试集和验证集。
为验证本文模型在微博用户情感分类研究的有效性,采用准确率、精确率、召回率和F1分数作为评价标准。其计算过程如式(11)~式(14)。
(11)
(12)
(13)
(14)
2.2 实验环境与模型参数
实验环境为Linux操作系统,采用版本为1.7的Py-Torch深度学习框架进行模型搭建以及训练。经多次实验寻优得到最优参数如下:BiSRU隐藏层大小为256,层数为1;
随机失活概率大小为0.3;
软注意力机制维度为512;
最大序列长度为200;
批处理大小为64,初始学习率为1e-5;
引入RAdam优化器,作为Adam的优秀变体,其能够自动调整学习率大小;
训练轮次为6次,损失函数为交叉熵函数。
2.3 实验分析
所有模型实验评估指标结果如表1所示,模型训练时间对比如图4所示。由表1可知,与近期表现较好的模型RoBERTa-BiLSTM、ERNIE2.0-BiLSTM-Att和ALBERT-CRNN相比,本文提出的RoBERTa-BiSRU-AT模型取得了最高的F1分数,证明了RoBERTa结合BiSRU-AT的有效性。
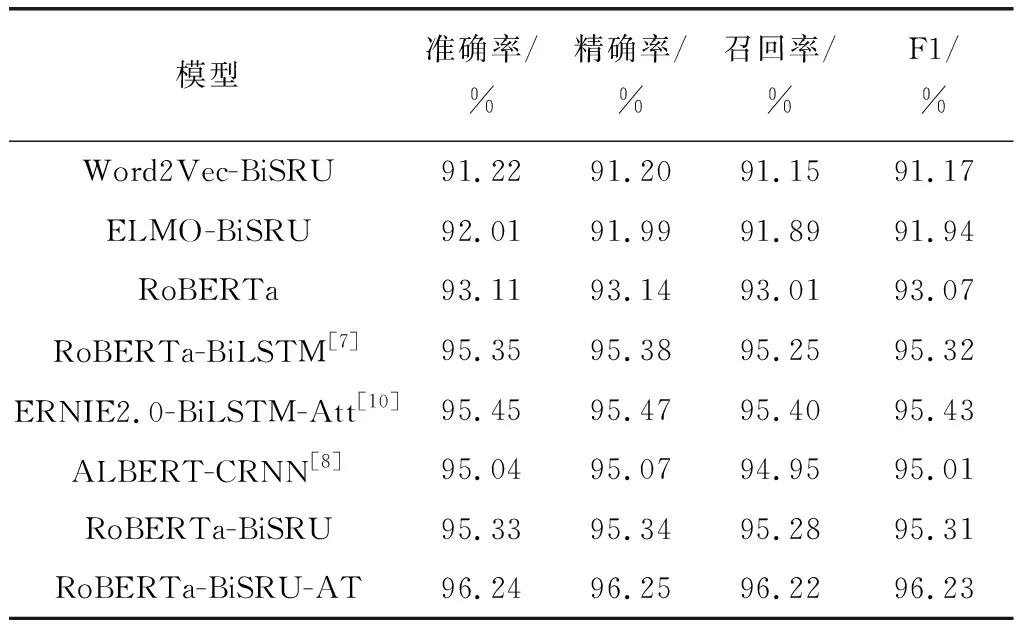
表1 模型评估指标对比

图4 模型训练时间对比
与模型Word2Vec-BiSRU、ELMO-BiSRU比较,RoBERTa-BiSRU模型F1分数分别提升了5.06个百分点和4.29个百分点,说明了预训练模型RoBERTa通过参考上下文的具体语境,能够学习到质量更好的词向量表示,结合下游任务进行微调,有助于提升微博评论情感分析的准确率。其中RoBERTa模型的重要模块Transformer,相对于基于双向LSTM的ELMO模型,特征提取能力更强。与Word2Vec和ELMO相比,RoBERTa应用效果更佳。
与RoBERTa模型作比较,RoBERTa-BiSRU模型F1分数提高了3.16个百分点,仅使用RoBERTa最后一层输出的CLS向量进行分类,效果不如加入二次语义提取模型BiSRU,BiSRU能够学习到微博评论文本的序列信息,提升模型的分类性能。
模型RoBERTa-BiSRU与RoBERTa-BiLSTM的F1分数仅相差0.01个百分点,性能表现相近,但BiSRU模型较BiLSTM参数量大幅度减少,从而训练速度较快,训练难度降低。
针对微博用户评论文本情感分类问题,本文提出了结合RoBERTa和BiSRU-AT微博用户情感分类模型。利用RoBERTa预训练模型得到动态词向量表示,解决了传统词向量无法区分同一个词在不同的上下文语境中有不同含义的问题。使用BiSRU-AT模型进行二次语义特征抽取,充分学习到文本中的上下文全局特征,软注意力机制可以注意到对分类结果较为关键的词,并且BiSRU训练效率优于BiLSTM。在真实新浪微博用户评论数据集进行实验,证明了RoBERTa-BiSRU-AT模型的有效性,RoBERTa在应用效果上优于其他词向量模型。由于RoBERTa模型参数量仍然较大,在未来工作中将考虑对其进行压缩,在最小化精度损失的条件下提升模型训练效率。
猜你喜欢 语义向量注意力 真实场景水下语义分割方法及数据集北京航空航天大学学报(2022年8期)2022-08-31向量的分解新高考·高一数学(2022年3期)2022-04-28让注意力“飞”回来小雪花·成长指南(2022年1期)2022-04-09聚焦“向量与三角”创新题中学生数理化(高中版.高考数学)(2021年1期)2021-03-19如何培养一年级学生的注意力甘肃教育(2020年22期)2020-04-13A Beautiful Way Of Looking At Things第二课堂(课外活动版)(2016年2期)2016-10-21向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14“吃+NP”的语义生成机制研究长江学术(2016年4期)2016-03-11向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23情感形容词‘うっとうしい’、‘わずらわしい’、‘めんどうくさい’的语义分析人间(2015年21期)2015-03-11







