基于影像组学的乳腺钼靶图像分类模型研究
时间:2023-01-16 22:20:06 来源:雅意学习网 本文已影响 人 
李 慧,焦 雄
(太原理工大学 生物医学工程学院,山西 晋中 030600)
随着不良生活习惯的普通化及环境恶化,全球癌症发病率逐年增加,经世界卫生组织(WHO)统计,在2020年全球最新癌症负担数据中,最明显的变化为乳腺癌新发病例的快速增长,全球乳腺癌新发病例高达226万例,已超过肺癌的220万例成为全球最常见的癌症[1]。乳腺癌的早发现、早诊断、早治疗可以明显改善疾病预后。
乳腺病变有肿块和钙化两种,目前常见的研究均是对于肿块病变良恶性的区分,而对于钙化病变良恶性区分较为少见,由于钙化区域通常具有不均匀的结构、不典型的动力学行为和边界模糊,且多数钙化为良性,这就使得对其判断更具有挑战性。通常早期乳腺癌影像没有肿块只有钙化簇,这些钙化点则是诊断乳腺癌的关键。然而钙化灶在术中通常难以定位,导致对其进行活检诊断或切除都具有一定盲目性。
对于乳腺癌的早期检查,乳腺钼靶X线可观察到小于0.1 mm的微小钙化点,可准确发现乳腺病变及其中肿块和钙化的形状、大小、密度等性质,尤其对于以微小钙化簇为唯一表现的早期乳腺癌具有一定的诊断意义[2]。因此乳腺钼靶X线是目前世界公认的临床上用于早期乳腺癌常规检查最可靠有效的方式。同时国内外大多数学者认可乳腺钼靶检查对降低40岁以上女性乳腺癌死亡率起到非常大的作用[3],尽管其存在有一定辐射且不易鉴别良恶性的问题。本研究中利用钙化区域的钼靶图像分析钙化点良恶性的方法不仅解决了活检无法准确定位钙化灶的难题,而且也免去了活检对患者带来的伤害,帮助医师使用非侵入手段更好地判别钙化区域的良恶性。同时对于早期乳腺癌的鉴别排查起到很大帮助,减少了医师由于大量阅片产生误诊漏诊的可能性。
目前将人工智能用于乳腺癌分类的研究较为常见。研究表明使用传统影像组学方法提取的定量特征经过分析在病灶良恶性分类、评估预后上均可对医师诊断提供帮助,在临床应用上有很大帮助[4]。常见的还有深度学习方法的应用,但神经网络所提取出的特征不具有可解释性,深层网络是“黑匣子”型,即使现在研究人员也不能完全了解深层网络的“内部”[5-6]。且由于实际问题中在样本集并不够大的情况下,传统机器学习算法通常优于深度网络,故本文使用影像组学中的传统方法提取可解释性的定量病灶区域特征。本研究以乳腺钼靶的钙化图像为研究对象提出了一种基于机器学习的传统乳腺肿瘤分类模型。结合了两个视图(CC和MLO)的图像特征,使用影像组学的研究方法构建基于机器学习的模型进行训练实现了乳腺钙化的良恶性分类。
本研究使用的是从公开数据库TCIA(the cancer imaging archive)中获取的CBIS-DDSM数据集[7],CBIS-DDSM是用于乳腺X线筛查的数字数据库(DDSM)的更新和标准化版本,图片格式为Dicom.本研究使用CBIS-DDSM数据集中所有钙化病例共753例(良性414例,恶性339例)的感兴趣区域(ROI)图像。本研究中感兴趣区域即是钙化病灶区域,它是由2-3名专业医师对钙化病灶区域进行选取后将围绕病灶的最小矩形边界短边扩展为与长边一样进而进行裁剪,裁剪后图像即为ROI图像。本文使用的ROI图像是CBIS-DDSM数据集中已经过整理的完整病灶区域图像。由于每例患者均分别进行常规轴位(CC),外侧斜位(MLO)的摄影,除单侧乳房全切外,均做双侧对比摄影,因此每例患者均包含1-4张影像数据。经统计,共有1 872张良/恶性钙化病例ROI图像(良性钙化图像1 199张,恶性钙化图像673张),如表1所示。

表1 实验数据集Table 1 Experimental data set
2.1 特征提取
影像组学的核心在于高通量提取用来描述ROI区域的高维定量影像特征[8]。在对特征提取前,本研究首先对乳腺钼靶钙化数据集图像进行了Dicom格式到png格式的转换,然后进行了RGB到灰度图像的格式转换。最后通过计算提取了4类影像组学特征,分别为形状、灰度、纹理、变换特征。各类特征及维数如表2所示。

表2 特征维度Table 2 Characteristic dimension
2.1.1形状特征
形状特征是医学影像上最直观的视觉特征,其使用形态学运算对感兴趣区域的形状、大小进行描述。本研究共提取形状特征20个,分别为周长、面积、欧拉数、方向度、矩形度、凸区域面积、填充区域面积、实心度、等价直径、离心率、主轴长、次轴长、细长度以及7个Hu不变矩。
2.1.2灰度特征
灰度特征是通过对病灶区域灰度直方图进行分析,得到有关描述ROI区域像素灰度值分布的一阶统计特征。本研究围绕ROI灰度图像共提取灰度特征14个,分别为最大值、最小值、像素范围、均值、中值、标准差、方差、均方根值、均匀性、能量、熵、偏度、锐利度、平均梯度。
2.1.3纹理特征
纹理特征可以反映图像像素灰度级的空间分布属性,体现了物体表面组织结构排列规则及其与周围环境联系的信息[9],是分类任务中的重要特征。相关学者[10-11]总结了TUCERYAN和JAIN的分类方法后,将纹理特征提取的分析方法分为4类,分别是统计分析方法、模型方法、信号处理方法和结构分析方法。本研究所提取的纹理特征有122个。其中统计型纹理特征中提取了灰度共生矩阵(GLCM)特征70个,是从0°、45°、90°、135°等4个角度分别计算了对比度、相关、能量、逆差矩、熵、惯性矩共24个,然后计算了4个角度下的对比度均值、对比度标准差、对比度方差、相关均值、相关标准差、相关方差、能量均值、能量标准差、能量方差、逆差矩均值、逆差矩标准差、逆差矩方差、熵均值、熵标准差、熵方差、惯性矩均值、惯性矩标准差、惯性矩方差,共18个。又设置了4个偏移距离[0,1],[-1,1],[-1,0],[-1,-1],计算了4个距离下的反差、自相关、能量和同质性4个特征,共16个。还计算了4个距离这4个特征的均值、标准差、方差,共12个,总计GLCM方法下共提取70个特征。灰度差分统计(GLDS)特征4个,分别是均值(MEAN)、对比度(CON)、角度方向二阶矩(ASM)、熵(ENT)。GGCM特征15个T1-T15,分别为小梯度优势、大梯度优势、灰度分布不均匀性、梯度分布不均匀性、能量、灰度平均、梯度平均、灰度均方差、梯度均方差、相关、灰度熵、梯度熵、混合熵、惯性、逆差矩。Tamura纹理特征6个,分别为粗糙度(coarseness,Fcrs),方向度(directionality,Fdir),对比度(contrast,Fcon),线性度(line-likeness,Flin),规整度(regularity,Freg), 粗略度(roughness,Frgh).模型型纹理特征中提取了马尔可夫随机场(GMRF)特征26个,分别是4个二阶特征,10个四阶特征,12个五阶特征,分形盒维数特征1个。信号处理型纹理特征则为下节中提取的变换特征。
2.1.4变换特征

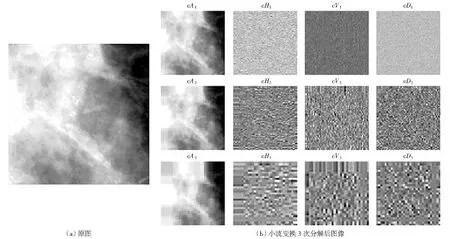
图中A表示低频子带,H表示水平高频子带,V表示垂直高频子带,D表示对角高频子带图1 某位患者钙化灶原图及小波变换后图像Fig.1 Original ROI image and wavelet transformed image of a patient
本研究对图像进行变换处理后再对变换后图像提取形状、灰度、纹理特征作为变换特征,共提取特征数3 200个。其中Gabor变换特征3 040个,小波变换特征160个。
2.2 特征降维
本研究通过计算共提取特征3 356个,为便于对特征数据进行综合分析比较消除量纲数值间差异,在进行特征降维前首先对特征数据进行了标准化处理。经过变换的特征数据均值为0,标准差为1,符合标准正态分布。标准化处理公式如下:
式中:μ为特征数据均值,σ为特征数据标准差。
本研究选择使用Lasso的方法进行特征降维处理。Lasso算法是一种稀疏估计,它本质上是在传统最小二乘估计的方法上添加了惩罚函数,使一些回归系数变为0,限制各系数绝对值之和,从而达到特征选择和降低模型复杂度,防止过拟合的目的[13]。
在建模过程中关键是找出最佳的正则项系数α,Lasso对α的变动非常敏感,每个α的取值都会对应不同特征向量前的权重参数w.通常会使用sklearn库中的LassoCV建立模型,此过程中使用了交叉验证帮助模型自动选择最佳的正则化参数α.正则项又通常被称为惩罚项所以正则项参数α又被记作惩罚项系数λ,由于惩罚项系数关系到Lasso算法的复杂度,所以随着λ的增加,模型惩罚严格度随之增加,最终筛选出的变量逐渐减少到一个稳定值。
本研究特征筛选过程中,Lasso算法正则项参数α范围设定为(10-3,10),取之间相同间隔的50个数,十折交叉验证迭代100 000次,最终最优参数α=0.016 768 329 368 110 076.最后从3 356个特征中筛选出43个特征,其中包含了2个形状特征,3个纹理特征,38个变换特征。
Lasso筛选出的43个特征的特征权重如图2所示。误差棒图如图3(a)所示,每个特征系数随λ的变化如图3(b)所示。

图2 特征权重图Fig.2 Weights of features

图3 与Lasso相关的两个图Fig.3 Two graphs associated with Lasso
3.1 分类模型构建
本研究中,分类模型构建的步骤为首先对乳腺钙化数据集中ROI图像进行特征提取,将提取后的特征数据进行标准化处理,然后使用Lasso的方法进行特征筛选,筛选后特征输入选定分类器中进行网格搜索寻找最优参数,再将最优参数输入所选定的分类器中,将训练集按7∶3分为训练集和验证集,交叉验证评估模型稳定性,最终将使用最优参数的模型保存后,输入未公开的标准化后测试集特征数据测试模型。模型构建流程如图4所示。本研究中分类器选择有4种,分别是支持向量机(SVM)、随机森林(RF)、梯度提升树(GDBT)、自适应增强(AdaBoost),下面对这4种分类器进行简单介绍。

图4 分类模型构建流程Fig.4 Classification model construction flow chart
3.2 Lasso-SVM
支持向量机(support vector machines,SVM)是一种适用于样本二分类的广义分类器,采用监督学习的方式,它的学习思想在于寻找一个使训练数据两类样本分割间隔最大化的超平面[14-16]。
支持向量机两个重要的参数分别是C和γ,惩罚因子C的作用主要是平衡模型的复杂度和误分类率。当惩罚因子越高,损失函数也会越大,模型越不能容忍出现误差,使得模型更复杂,也更易过拟合。γ则是在支持向量机选择RBF为核函数时该核函数所带的一个参数,它决定了单个样本对分类超平面的影响范围,γ越大则σ越小,σ小则高斯分布又高又窄,单个样本对整个分类超平面的影响范围小,支持的向量少,模型更复杂,更易过拟合。故C和γ要取适当的值,以保证模型泛化能力。
本研究中Lasso-SVM模型进行特征筛选后,该模型使用高斯径向基(RBF)核函数的支持向量机(SVM)分类器,在参数网格搜索中,参数C选取范围为(2-1,23)之间相同间隔的10个数,参数γ选取范围为(2-4,2)之间相同间隔的50个数,其余参数使用默认值。最终经过网格搜索最优参数为C=0.925 874 712 287 290 3,γ=0.062 5.输入分类模型后验证集ACC为0.792,AUC为0.746.经过测试,测试集ACC为0.690,AUC为0.655.
3.3 Lasso-RF
随机森林(random forest,RF)是一种利用多棵决策树进行分类的分类器,它的输出类别由所有树对样本进行训练并预测后的多数预测类别所决定。
在本研究中Lasso-RF模型进行特征筛选后,该模型的随机森林(RF)分类器使用“gini”作为分割特征的测量方法 ,参数网格搜索中森林中树的数量(n_estimators)设定范围为(50,1200)之间相同间隔的24个数,树的最大深度(max_depth)设定范围为(5,50)之间相同间隔的15个数,其余参数选择默认值。最终网格搜索后最优参数n_estimators为550,max_depth为27.输入分类模型后验证集ACC为0.974,AUC为0.684.经过测试,测试集ACC为0.699,AUC为0.673.
3.4 Lasso-AdaBoost
自适应增强(AdaBoost)是一种迭代算法,该算法是FREUND和SCHAPIRE于1995年对Boosting算法的改进得到的[17]。这个算法的思想是在训练样本的过程中不断迭代,通过调整被错误分类的样本权值以及分类器的权值来对模型进行改进,训练不同的弱分类器并最终以加权表决的方式构成强分类器。
在本研究中Lasso-AdaBoost模型进行特征筛选后,该模型的自适应增强(AdaBoost)分类器所选择的基分类器为决策树分类器。决策树基分类器选择了“gini”作为分割特征的测量方法,基分类器只对树的最大深度(max_depth)进行了调参,范围为(1,30)相同间隔取30个数,基分类器其余参数使用默认值。自适应增强分类器即为在该基分类器的基础上进行boosting.最优参数网格搜索中,基分类器提升(循环)次数(n_estimators)设定范围为(50,1 000)相同间隔取20个数,学习率(learning_rate)设定范围为(0.01,1)相同间隔取100个数,最终经过网格搜索最优参数max_depth为4,n_estimators为1 000,learning_rate为0.616 122 448 979 591 8.
3.5 Lasso-GBDT
梯度提升树(gradient boosting decision tree,GBDT)是一种将基分类器CART决策树迭代的算法[18]。它的学习算法为前向分步算法,它从弱学习器出发,训练一系列基分类器,利用加法将基分类器组合起来构成一个强分类器。
在本研究中Lasso-GBDT模型进行特征筛选后,该模型的梯度提升树(GDBT)分类器参数网格搜索中,参数树的最大深度(max_depth)设定范围为(1,10)按相同间隔取10个数,学习率(learning_rate)设定范围为(0.01,1)按相同间隔选取50个数,其余参数使用默认值,最终经过网格搜索最优参数max_depth为9,learning_rate为0.050 408 163 265 306 12.输入分类模型后验证集ACC为0.774,AUC为0.722.经过测试,测试集ACC为0.708,AUC为0.678.
3.6 使用SMOTE解决样本不平衡问题
本研究使用1 546张(良性1 002张,恶性544张)乳腺钼靶钙化图像作为训练集,326张(良性197张,恶性129张)乳腺钼靶钙化图像作为测试集。由于当正负样本不平衡时通常选用欠采样或过采样来均衡样本数据。欠采样为压缩样本数据多的一类,过采样为补全样本数据少的一类。为提升模型性能,这里使用了SMOTE(synthetic minority oversampling technique)算法将训练集数据过采样合成为良性数据∶恶性数据=1∶1的均衡样本。SMOTE算法是CHAWLA et al[19]于2002年所提出的用于数据过采样的算法。SMOTE过采样算法优于随机过采样,因为随机过采样容易造成模型过拟合,随机过采样本质上仅仅只是复制已有的少数类样本数据来增加少数类样本,这使得模型泛化能力不足[20]。而SMOTE算法采用了KNN算法的思想,通过分析类别少的样本来合成新的少数类样本,从而达到填充少数类样本使正负样本数据平衡的目的。SMOTE算法的流程如下。
输入:不平衡样本数据
1) 设定每个少数类样本为A
2) 按照采样倍率从每个A的最近邻中随机选择m个少数类样本设为A′
3) 在AA′之间连线上随机合成新的少数类样本B,合成公式为B=A+rand(0,1)*(A′-A)
输出:平衡数据
故本研究又使用SMOTE算法分别构造了SMOTE-Lasso-SVM、SMOTE-Lasso-RF、SMOTE-Lasso-AdaBoost、SMOTE-Lasso-GBDT 4种模型。在使用SMOTE算法对训练集数据过采样时,使用Lasso算法所提取的特征维数变为74维。其中包含3个形状特征,3个灰度特征,3个纹理特征,以及65个变换特征。
3.7 模型结果比较
本研究中使用准确率(accuracy,ACC)和受试者工作特征曲线(receiver operating characteristic curve,ROC)下面积AUC对所建立的8种模型分类结果进行评估。ACC是指测试集中分类正确样本数占总样本数的比例,是一种对模型分类能力最直观的评价。受试者工作特征曲线(ROC)是帮助划分正常值与异常值之间界限的一种重要手段。ROC曲线是由混淆矩阵计算得出,它的横轴为假阳性率(FPR),即阴性样本被误分类为阳性样本的概率;
纵轴为真阳性率(TPR),即阳性样本被正确分类的概率[21]。将不同阈值下TPR、FPR组合起来就构成了评估模型分类效果的ROC曲线。AUC是受试者工作特征曲线(ROC)下面积,是衡量学习器优劣的一种性能指标,当ROC曲线不能明显显示出哪个模型效果更好时,AUC越大则分类器效果越好[22],通常情况下AUC为0.5表示模型无诊断价值、AUC为0.7~0.9表示模型准确率高、AUC约为1则为最理想的指标。
经过验证预测8种模型结果如表3所示。

表3 8种模型分类结果比较Table 3 Comparison of the classification results from 8 models
由表3可以看出,每种分类器在使用和未使用SMOTE算法下,使用SMOTE算法均衡训练集后的模型验证集和测试集的分类准确率ACC和AUC均有所提升。经过初步比较,在使用SMOTE算法的模型中,4种分类器中表现更优的为随机森林(RF)分类器,故选择SMOTE-Lasso-RF模型作为最终分类模型。
本研究中SMOTE-Lasso-RF模型构建首先使用SMOTE将训练集数据均衡化为正负样本1∶1,然后使用Lasso算法从图像中提取出的3 356维特征中选出74维作为模型输入,再使用网格搜索选择RF分类器最优参数代入分类器并用十折交叉验证检测分类器稳定性,最后做混淆矩阵与ROC曲线,计算模型ACC、AUC、敏感性(sensitivity)、特异性(specificity)、阴性预测率(NPV)、阳性预测率(PPV)用来评估模型。其中网格搜索后RF分类器的最优参数max_depth为46,n_estimators为300.最终结果ACC为0.742,AUC为0.737,敏感性为0.713,特异性为0.761,NPV为0.802,PPV为0.661.SMOTE-Lasso-RF模型验证集和测试集ROC曲线,如图5所示。

图5 SMOTE-Lasso-RF模型ROC曲线Fig.5 ROC curves of SMOTE-Lasso-RF model
综上所述,本文最终选择的SMOTE-Lasso-RF模型优于本文所提出的其他分类模型,能更好对乳腺钼靶钙化病灶进行良恶性诊断,有利于辅助放射科医师进行诊断并提高效率,向未来影像组学在临床上的应用更进一步。
在临床上,肿块型乳腺癌相比非肿块型乳腺癌更易诊断,非肿块型乳腺癌容易漏诊,同时由于乳腺癌钙化具有更高发生率,所以对钙化病灶的诊断在乳腺癌的早期诊断中具有重要意义[23]。当前仅通过医学影像对乳腺癌进行诊断的研究仍是一个重要的研究方向,图像采集所用仪器和各种因素影响下,对于乳腺癌的定量分析目前仍无统一的定论,找到能够实现非侵入手段诊断疾病良恶性的定量影像生物标记是如今影像组学领域学者们奋斗的目标。本研究中通过对乳腺钼靶图像中钙化灶ROI图像使用影像组学方法进行定量特征提取,然后根据是否使用SMOTE算法来扩增训练集数据将训练集分为两类数据。然后使用Lasso算法分别对两类数据所提取出的标准化后特征进行特征选择,并尝试分别与SVM、RF、AdaBoost、GBDT四种机器学习分类器组合构建分类模型,并对模型进行评估。通过对ACC、AUC比较选择了SMOTE-Lasso-RF作为乳腺钼靶图像钙化灶的良恶性预测模型,该模型的AUC达到0.737,ACC达到0.742.
本研究是针对乳腺癌早期钙化病灶进行诊断,而目前对于乳腺癌的诊断通常为对于肿块的研究。在图像的区别上微小钙化灶更难以捕捉并且由于恶性钙化灶的体积更小,形态各异使得对于钙化灶的良恶性判断具有一定难度。本研究中提出了一种结合数据平衡扩增算法的模型,使用了SMOTE数据重采样算法解决了目前常见的影像数据集中存在数据不平衡的问题。此前孙利雷等[24]使用CBIS-DDSM数据集使用DP-CNN网络区分肿块良恶性,最终的测试结果AUC为0.712 9,在本研究中通过多模型对比区分钙化区域良恶性,最终得到的模型AUC为0.737,具有较高可靠性。
本研究解决了现实生活中常存在的影像数据样本不均衡的问题并为影像组学进一步应用于临床起到了一定的参考作用,在提高工作效率的同时降低错诊漏诊。本研究的局限性在于研究样本量不够大及精确率不够高。未来需要在控制模型训练时间的前提下进一步提升样本量和分类准确度。
猜你喜欢 分类器灰度乳腺癌 绝经了,是否就离乳腺癌越来越远呢?中老年保健(2022年6期)2022-08-19采用改进导重法的拓扑结构灰度单元过滤技术北京航空航天大学学报(2022年6期)2022-07-02学贯中西(6):阐述ML分类器的工作流程电子产品世界(2022年4期)2022-04-21中医治疗乳腺癌的研究进展现代临床医学(2022年1期)2022-02-12天津港智慧工作平台灰度发布系统和流程设计集装箱化(2021年1期)2021-04-12基于朴素Bayes组合的简易集成分类器①计算机系统应用(2021年2期)2021-02-23Bp-MRI灰度直方图在鉴别移行带前列腺癌与良性前列腺增生中的应用价值天津医科大学学报(2021年1期)2021-01-26Arduino小车巡线程序的灰度阈值优化方案中国信息技术教育(2020年2期)2020-02-02基于动态分类器集成系统的卷烟感官质量预测方法计算机应用与软件(2020年1期)2020-01-14一种自适应子融合集成多分类器方法计算机测量与控制(2019年4期)2019-05-08






