面向区块链溯源的链下扩展存储方案
时间:2023-01-16 15:30:09 来源:雅意学习网 本文已影响 人 
张 斌,李大鹏,蒋 锐,王小明
(南京邮电大学通信与信息工程学院,江苏 南京 210003)
供应链是通过上游和下游进行联系,把商品从生产端流向消费者的一个网状结构[1],它将供应流程中各环节企业进行串联,提高了企业间的协同效率,让企业的经济效益实现最大化[2]。供应链的高效运作是经济发展的重要保障,但在传统的供应链管理模式溯源中,由于供应链环节参与者较多、管理结构复杂等原因导致其面临着以下瓶颈:如信息不能够得到有效的共享、数据追踪比较复杂且信息不具有完全可信性等[3]。这些问题会造成消费者对其购买商品产生信任危机,同时市场秩序也会由于不良商家的不诚信行为产生不稳定因素[4]。
区块链是一种新兴技术,它具有去中心化、不可篡改、匿名性和数据可追溯的特点,这些特点使得它在解决传统溯源系统中带有天然的信任优势[5]。该技术可以在不完全可信的环境中实现可信的数据管理,同时也能够记录2个主体之间的交易,而无需中介机构的干预[6]。随着区块链技术的发展,人们普遍认为其可以颠覆性地改变社会现有的信任问题[7]。
为了从区块链技术中受益,各个行业都在积极地对其进行研究[8]。Rewatkar等人[9]把区块链技术与电子投票系统进行结合,保证了选民身份和选票的安全,有助于建立对选举制度的信任。Subramanian等人[10]将物联网技术与区块链技术相结合,构建了二手电动车供应链交易平台,从而各参与方可以产生信任、透明、不可变的记录。陈飞等人[11]利用区块链技术对食品的信息进行溯源,解决了供应链中各企业之间的信任问题。张朝栋等人[12]结合区块链和侧链技术实现了供应链溯源,保证了溯源数据的不可篡改性同时也提高了系统的吞吐量。Chen等人[13]将区块链技术与人员信息管理相结合,为提高区块链系统的存储能力,提出把明文数据根据数据的重要程度进行分割,重要数据直接上链,不重要的数据存储在数据库中并对其进行哈希运算得到哈希值,哈希值存储在链上。
在上文所提利用区块链技术解决对应领域问题中,都是直接把溯源数据的部分或全部存储在区块链上,由于区块链技术的特点使得它在面对溯源这种存在大量数据的场景时存储能力会成为系统的主要瓶颈。由此本文提出一种链下扩展存储方案,该方案通过结合中心化存储和区块链技术各自的优势,把明文数据存储在中心化数据库中,明文数据的哈希值和对哈希值进行签名的签名值存储在区块链上。最后采用以太坊区块链对上述方案进行实现并测试,测试结果表明,本文所提方案能够提升溯源系统整体的响应速度且减少溯源数据占用区块链中的内存。
1.1 区块链技术
区块链技术最早可以追溯到2008年11月1日,中本聪在“密码朋克”表发了一篇题为《比特币:一种点对点式的电子现金系统》的论文。虽然不同版本的区块链其所针对解决问题的场景有所不同,但它们的系统基础架构基本一致,其结构如图1所示,主要包含应用层、合约层、激励层、共识层、网络层和数据层[14]。
数据层是用来保存区块链数据的,每个区块都由区块头和区块体2个部分组成[15]。网络层主要包含P2P网络架构、传播机制和验证机制,保证了区块链上各个节点数据的同步,是矿工挖矿成功后把区块同步出去的基础[16]。共识层的主要功能是实现区块链网络中所有交易的确认,不同的共识算法其所面对的使用场景不同[17]。激励层的主要功能是对发行机制和分配机制的实现,以此保证数字货币的不断发行和对挖矿用户的奖励[18]。合约层主要运行智能合约,是实现复杂业务的基础,它为区块链技术与实际场景结合提供了可能[19]。应用层主要对区块链的应用场景和案例进行实现。区块链通过这些技术的结合,解决了一直存在的信任构建问题[20]。
1.2 智能合约
“智能合约”(Smart Contract)这个术语至少可以追溯到1995年,它是被尼克·萨博(Nick Szabo)首次提出的。智能合约将一组数字承诺定义为:一条在程序运行中实施并存储在区块链上的协议[21],它可以通过提供自动交易来促进安全可靠的业务活动,而无需外部银行、法院或公证人等外部金融系统的监督[22]。Solidity是实现智能合约的一种编程语言,它可以部署在EVM虚拟机上运行[23]。这种形式的出现简化了一些重复性的确认工作。
1.3 哈希函数
哈希函数又称消息摘要算法,其无需借助任何密钥就可以将任意长度的二进制值映射成一个固定长度的哈希值[24]。它具有单向不可逆的特性,即对于任意值不管进行多少次哈希运算都会得到相同的结果,但是不能通过哈希结果反推原始数据的值。如果输入值产生微小的变化,其得到的结果也是截然不同的,因此可以利用此特性保证数据的完整性和防伪造性[25]。虽然哈希算法有出现哈希碰撞的可能,但概率是极低的,利用哈希碰撞去修改原始数据得到相同的哈希值,几乎是不可能的。
1.4 SM2国密算法
SM2国密算法是由我国国家密码管理局于2010年发布的一种非对称加密算法,加密和解密使用的不是同一个密钥。相较于RSA加密算法来说,SM2加密算法具有存储空间小、密钥生成速度快、加密解密时间短的特点,它不仅保证了消息的完整性,还可验证消息来源的合法性[26]。本方案中,主要采用该加密算法对数据上传者的身份进行确认,保证信息上传者身份是可靠的。
在当前的区块链溯源系统中,主要是结合区块链技术和智能合约对溯源数据直接进行链上存储,这会因为溯源数据量较大,产生大量内存被浪费问题。也有部分系统采用链上存储哈希值的方式对溯源数据进行保存,但不能保证信息上传者身份的可靠性。因此本文结合SHA-256哈希算法和SM2加密算法,提出一种链下扩展存储方案,其具体设计将在第2章进行详细介绍。
2.1 节点类型
在供应链中主要由原材料生产企业、运输企业、商品生产企业、商品销售企业4类企业构成。一条供应链中所涉及的企业集合为Q={q1,q2,…,qn},其中qi需要上链的信息集合M={M1,M2,…,Mk}进行表示。数据传递顺序是按照Q集合中的顺序进行的,q1是指原材料生产企业,qn表示的是销售企业。如果节点qi在节点qj前面,即i+1=j,则把qi称为qj的上游企业,反之则称qj为qi的下游企业。
2.2 链上数据存储设计
本文提出链上数据存储设计方案是基于以下2点考虑的:1)保证链下数据的不可篡改性。2)确定数据上传者的身份信息。针对第1点,采用SHA-256哈希算法,利用哈希算法的单向性,保证链下数据的不可篡改。如果链上数据有部分被修改,则其得到的哈希结果是不一样的。对于第2点,选择非对称加密的方式,企业方使用SM2加密算法产生的私钥对明文数据产生的哈希值进行签名,保证上传数据者身份是确定的。上链信息包含以下2个部分:哈希值和签名值,其中哈希值如式(1)所示,签名值如式(2)所示。
Hashi=hash(Hashp,Mi)
(1)
Signi=Signature(Hashi,SKi)
(2)
其中hash是通过SHA-256哈希算法对括号内数据进行哈希运算的函数。Hashp表示当前企业的上游企业的哈希值,其值可以直接从区块链上获取。但在使用前需要利用上游企业的签名值对其进行校验,验证通过后才能使用,这保证了上游企业哈希值的可靠性,其校验方法如式(3)所示。如果签名值未通过校验,则拒绝接受上游企业产品。Hashi表示当前企业数据的哈希值。Signature是通过SM2加密算法对括号内的哈希值进行签名的函数,企业利用自身私钥SKi对Hashi进行签名得到当前企业上链签名值Signi。在计算当前企业明文数据的哈希值时会包含其上游企业的哈希值,选择这种存储方式是因为当消费者在进行商品验证时,在获取链下明文数据后,只需要读取最后一个企业的链上哈希值与签名值即可完成验证,而不必将所有企业的链上数据都进行获取。通过这种存储设计可以提高溯源系统的验证效率。
res=verifySign(Signi-1,Hashp,PKi-1)
(3)
其中verifySign是对当前签名进行校验的函数。Signi-1为企业qi-1的签名值,Hashp表示企业qi-1存在链上的哈希值,PKi-1表示企业qi-1的公钥,res为true时则表示验证通过。
2.3 链下扩展存储方案
基于2.2节的链上数据存储设计,本文提出链下扩展存储方案。为说明该方案的流程,首先给出其整体结构如图2所示。
图2中上链数据生成模块的实现方法如2.2节所示,它对商品各个环节产生的明文数据进行处理并把明文数据产生的哈希值和签名值结果通过部署智能合约的方式存储在区块链中。在企业集合Q中,各企业数据存储流程如图3所示。
1)企业需要把公钥通过智能合约上传到链上,利用区块链的不可篡改性保证下游企业得到的上游企业公钥是完全可信的。
2)企业qi从区块链上获取上游企业qi-1的Hashi-1、Signi-1和PKi-1,并对其进行签名校验。
3)如果签名验证成功则企业qi把自身数据按照式(1)和式(2)对其明文数据Mi进行处理,生成数据Hashi和Signi,并把其上传到链上。
4)企业qi将该企业链上数据存储的位置addressi、明文数据Mi和上游企业数据在其对应数据库表的存储位置pid保存在数据库中。id是由数据库按照自增原则自动生成的。
由于q1企业没有上游企业,因此它没有pid字段也不必对链上的数据进行获取。qn企业增加了一个productNum字段,该字段可找到qn企业的数据并且可以通过pid的值向上追踪获得商品从原材料到销售的全部数据,用于对商品的数据进行溯源。
2.4 溯源数据验证
基于区块链的溯源系统主要是保证商品数据的真实性并对错误数据进行溯源,找到问题企业。本文提出的链下扩展存储方案溯源数据验证流程如图4所示。
消费者把商品编号productNum输入到服务器端后,服务器端首先从数据库中得到qn企业链上信息存储的位置和该商品从q1到qn企业的所有信息。商品信息按照式(1)所示方式进行哈希运算生成哈希值Hashd,然后通过链上信息存储位置addressn获得Hashn、Signn和PKn,并对其按照式(3)进行校验。如果res校验结果为true则将Hashd和Hashn进行对比,相同则返回true代表商品数据未发生改变,不同则返回false代表商品信息有误发生改变。如果res校验结果为false则直接返回,代表商品信息有误发生改变。
2.5 问题企业定位
如果消费者验证商品信息后发现商品信息存在部分被篡改的情况,则溯源系统会把数据库中关于该商品的所有信息按照算法1对问题企业进行定位。由于当前企业链上存储的哈希值与其上游企业的哈希值有关,因此验证过程中需要从第1个企业开始进行验证。其中getPK表示从链上获取企业qi的公钥,getHash表示从链上获取企业qi的哈希值,getSign表示从链上获取企业qi的签名值。
算法1 问题企业定位。
输入:链下各企业数据集合Mi和addressi,公钥存储合约地址addressp。
输出:数据错误企业集合E。
Begin
E;
Hashb1=getHash(address1)
if(hash(M1) !=Hashb1){
E.add(q1);
}
Hashbpre=Hashb1//保存上游企业链上哈希
for(i=2; i<=n-1; i++){
Hashbi=getHash(addressi)
Hashdi=hash(Hashbpre,Mi)
if(Hashbi!=Hashdi){
E.add(qi)
}
Hashbpre=Hashbi
}
PK=getPK(addressp,qn)
Hashbn=getHash(addressn)
Signn=getSign(addressn)
res=verifySign(Signn,Hashbn,PKn)
if(res==false||hash(Hashbpre,Mn) !=Hashbn){
return E.add(qn)
}
return E;
End
q1没有上游企业,所以单独对其数据进行校验。除qn企业外其他企业的链上签名值已经在数据进行传递的过程中完成了校验,如果其签名值有误,则不会再有后续流程,因而在进行问题企业定位时直接将链下数据的哈希值与链上存储的哈希值进行对比即可。对于qn企业没有下游企业,其签名值未经过校验,需要单独对其执行一次签名值校验过程。下游不能保证上游企业链下数据的可靠性,所以在下游企业进行哈希运算时代入的上游企业哈希值是在上轮校验时从链上得到的,每轮校验结束时需要对其进行更新。通过验证n次即可发现数据发生变更的企业集合E。
3.1 系统架构设计
系统技术架构如图5所示。
溯源系统使用B/S架构,在服务器端选择Java语言进行实现,采用Spring+SpringMVC+MyBatis的开源框架对用户端发送的信息进行分层处理,减少系统整体的耦合性。Web3j是Java应用与区块链网络进行数据交互的一个轻量级Java开发库,实现了JSON RPC接口的协议封装。对于用户展示层采用BootStrap+jQuery+JSP完成与用户交互界面的搭建,方便企业对溯源数据进行上传和查询。本次实验选用Ganache作为以太坊网络,它是基于本地内存的以太坊测试网络,主要用于开发和测试,实现了真实以太坊网络的完整功能。
3.2 数据库表与智能合约设计
企业产生数据的明文存储在数据库中。结合供应链管理系统的场景,本次设计包含以下5类表:原材料生产企业信息表、运输企业信息表、商品生产企业信息表、商品销售信息表和企业登录信息表。
原材料生产企业信息表如表1所示,原材料信息合约地址是原材料数据哈希值与签名值在区块链中的存储位置,可以通过加载该合约地址获取到链上存储的哈希值与签名值。

表1 原材料生产企业信息表
运输企业信息表如表2所示,pid字段用来对上游企业信息进行定位。为了对比上链数据中只包含文本数据和哈希值与签名值2种方案占用内存的大小,在运输和销售阶段不再添加该环节产生的图片信息。

表2 运输企业信息表
商品生产企业信息表如表3所示。

表3 商品生产企业信息表
销售企业信息表如表4所示,其中product_num字段表示商品编号,用于追踪校验。
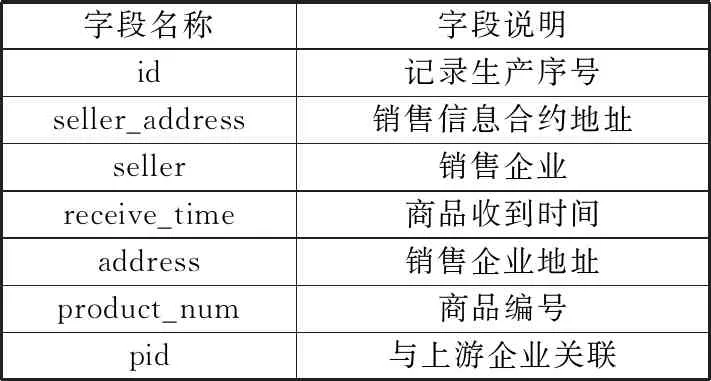
表4 商品销售企业信息表
企业登录信息表如表5所示。其中用户以太坊地址用于企业账户与链上数据交互。duty字段为自定义的字段,该字段不同值代表了不同的用户身份,其中1表示原材料生产企业,2表示运输企业,3表示商品生产企业,4表示商品销售企业。

表5 企业登录信息表
在区块链溯源系统中,智能合约是用户对数据上链的一种规范约束,它使用编程语言Solidity在Remix开发平台上进行开发[27]。在智能合约的设计上,本次设计总共分为2个合约:企业公钥保存合约和信息存储合约。
企业公钥保存合约是由平台监管方进行部署的,也只有平台监管方才能够对企业公钥进行上传。其变量和函数如表6所示。

表6 企业公钥保存合约中的变量与函数
平台监管方通过setEnterprisePK对企业进行注册并上传企业公钥,在企业上传数据时需要通过ifLegitimate函数先对其账户地址进行校验,如果该企业公钥没有在企业公钥保存合约中存储则拒绝其上传企业数据请求。下游企业通过getPK函数对上游企业的公钥进行获取。
信息存储合约是由企业在上传信息时进行部署的。其变量和函数如表7所示。
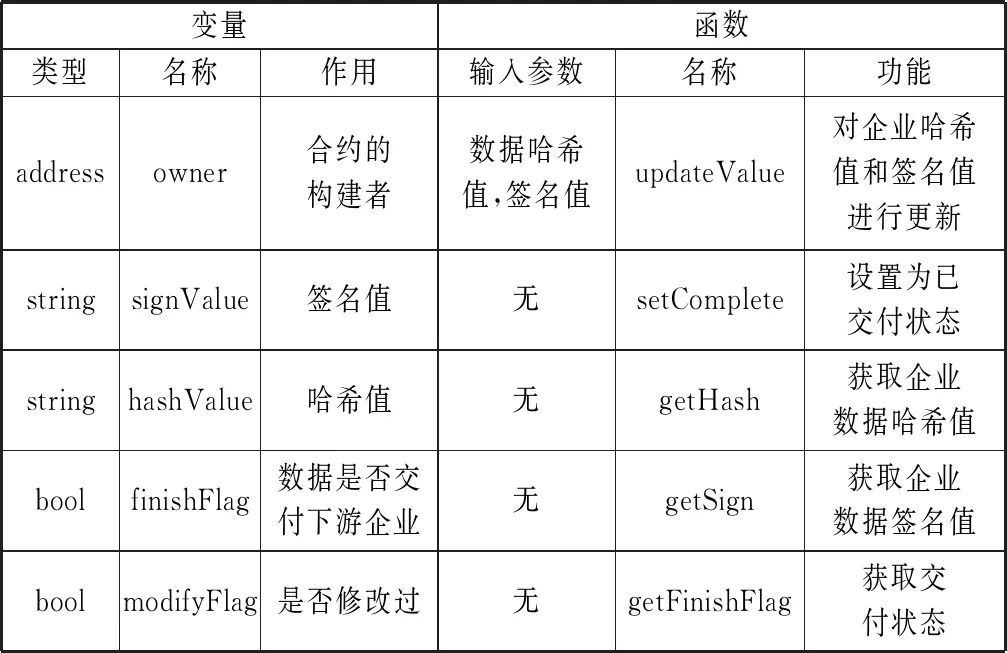
表7 信息存储合约中的变量与函数
合约中的哈希值和签名值是在部署合约时通过构造函数传入的。为保证同一信息只能够使用一次,合约中设置一个标志finishFlag。下游企业在对当前企业数据验证时,finishFlag必须是false,当把物品交由下游企业后当前企业需对该标志状态进行更改,任何人都不能再对哈希值与签名值进行更改,避免同一标签再次复活。在还没有对物品交付前,防止企业因为疏忽输错数据,允许企业通过updateValue函数对其链上值进行修改,但只允许修改1次,修改完成后需要把标志modifyFlag设置为true。
3.3 系统实现
溯源系统需要对企业注册、商品信息上传和溯源查询等功能进行实现。其中企业注册页面如图6所示。
当用户注册完成,并认证通过后服务器会把SM2加密算法生成的私钥通过邮件的方式通知企业进行保存,公钥则上传到链上用于下游企业对上游企业的加密数据进行验证。企业在上传生产信息时需要将私钥同时进行上传,保证上传者身份是可靠的。
商品生产企业创建商品信息页面如图7所示。
其上传信息与表3中需要上传的一致,上游企业相关联的id是通过上传上游企业合约地址进行获取的,企业私钥用于对当前企业产生数据进行签名,对于表3中在该页面没有上传的值可以直接从登录用户中进行获取。另外3类企业上传信息页面与本页面类似,只是上传的数据不同,不再进行展示。
当消费者拿到商品后,可以通过商品的编号在溯源查询页面进行查询。为验证本方案的可行性,简化了溯源流程,对每一类企业只包含了一个节点。查询结果如图8所示。
在页面的最下方展示了溯源数据的验证结果。如果数据正确则展示溯源数据未被更改,如果错误会展示溯源数据被更改和数据有问题的企业的集合。
本系统实现是在Windows环境下进行的,固态硬盘容量是512 GB,内存大小为16 GB,处理器使用的是AMD R7 4800H。系统软件开发环境版本如表8所示。

表8 系统软件开发环境版本
首先对溯源数据全部上链数据和本文所提方案在内存占用上进行对比。通过记录10次二者存储上链数据大小后取平均值,其对比结果如表9所示。

表9 上链数据占用内存大小对比
本文所提出的方案只需要每个企业把所产生数据的哈希值和签名值存储到区块链中即可,SHA-256加密后的大小为32 B,SM2签名要经过ASN.1编码,其长度在70~72 B变化,因此上链数据占用内存的大小在102~104 B之间。溯源数据全部上链时,由于在设计运输信息和销售信息中未涉及图片的存储以用来对溯源数据只包含文本数据形成对照,在这2个环节链上存储数据的大小略小于本文方案,但在原材料信息和生产信息中其内存占用大小明显大于本文所提方案。
最后对溯源数据全部上链和本文所提方案2种方式的数据上传响应时间和溯源信息校验时间2方面进行对比,其结果分别如图9和表10所示。

表10 溯源信息校验时间对比
在各企业对商品各阶段信息进行上传时分别在合约部署前和部署后对系统时间进行读取,然后把其相减即可得到合约部署响应时间。由图9中可以看出,在上链数据值有文字信息时二者响应时间几乎相同,但如果企业需要保存图片信息时,二者响应时间差别较大。因此本方案在一定程度上可以提高系统对溯源数据保存的响应速度。
当输入商品编号后,在商品溯源信息开始校验前与校验完成后分别对系统当前时间进行读取,然后相减得到溯源信息验证时间。溯源数据全部上链时不会存在溯源数据发生篡改,因此不存在问题企业定位环节。本方案在溯源信息没有被篡改的条件下验证时间远小于溯源数据全部上链的时间,即使是溯源信息出现错误,对问题企业定位所花费的时间也较短。
本文针对溯源数据全部上链会产生占用内存较大增加溯源系统的维护成本和降低系统的响应速度的问题,提出一种链下扩展存储方案。该方案通过SHA-256哈希算法和SM2加密算法,在保证数据的可靠性、可溯源性和数据不可被篡改的条件下减少了链上数据的存储大小,提高了区块链的扩展性。最后通过以太坊区块链对所提方案进行实现,经过性能评估,表明该方案在上链数据存储内存的占用远小于数据全部上链,而在进行合约部署时的响应时间和溯源信息校验时间上有一定的提高。在后续工作中,可以考虑对区块链共识算法进行优化,以进一步提升区块链与供应链溯源结合的实用性和可靠性。
猜你喜欢 公钥哈希校验 复杂多耦合仿真模型校验工具研究计算机仿真(2022年6期)2022-07-20使用Excel朗读功能校验工作表中的数据中学生学习报(2022年15期)2022-04-17基于特征选择的局部敏感哈希位选择算法大数据(2021年6期)2021-11-22电能表在线不停电校验技术机电工程技术(2021年3期)2021-09-10哈希值处理 功能全面更易用电脑爱好者(2021年8期)2021-04-21文件哈希值处理一条龙电脑爱好者(2020年20期)2020-10-22神奇的公钥密码知识就是力量(2018年10期)2018-10-18精通文件校验的“门道”电脑知识与技术·经验技巧(2017年9期)2018-02-24国密SM2密码算法的C语言实现中国新通信(2017年18期)2017-10-22基于身份的聚合签名体制研究成长·读写月刊(2017年4期)2017-05-16








