一种带隐变量贝叶斯网的事件诱因估计方法
时间:2022-12-02 14:15:03 来源:雅意学习网 本文已影响 人 
何 勇,吴鑫然,岳 昆
(云南大学 信息学院,昆明 650500)
E-mail:xrwu@mail.ynu.edu.cn
互联网、搜索引擎和新闻平台的持续发展使得网络舆情事件极易爆发[1],从北京申奥成功、环球金融危机、波及全球的COVID-19到中国抗疫的成功,这些事件受到了广大网民的关注评论与转发,其产生的影响有利有弊.例如,真假信息的混杂、舆论走向的引导、舆论秩序的监控等.事件诱因研究可为上述问题提供有效解决方案,也在精准决策支持及用户行为定向等方面发挥着重要作用.
新闻事件数据中可直接观测的时间、地点、类型和规模等显性特征蕴含了诱导事件发生的因素.表1给出了3种不同类型的事件特征数据,数据格式为“季节、类型、规模、级别”.近年来,通过分析事件特征数据,进而估计事件诱因,已经成为国内外研究的热点.然而,从事件特征数据中提取事件诱因,仍存在以下挑战.
首先,新闻事件显性特征之间的依赖关系描述困难.从实际情况看,显性特征之间、显性特征与事件诱因之间存在依赖关系,这种依赖关系可归纳为:特征A与特征B之间可能存在着依赖关系,如果A与B之间存在由A指向B的依赖关系,那么对A的了解会影响关于B的信度,反之亦成立.例如,某个事件发生的诱因可能由时间及类型共同决定,事件发生的级别可能与时间及诱因有关.因此,如何描述此类依赖关系是估计事件诱因的关键.

表1 事件特征数据Table 1 Feature data w.r.t. events
矩阵分解模型[2-4]和主题模型[5-7],是新闻事件特征数据分析的经典方法.矩阵分解模型在预测和推荐方面有着良好表现,但可解释性较差,且无法直观刻画事件特征数据中潜在的隐含知识.主题模型克服了矩阵分解模型不能直观刻画潜在知识的问题,但无法表达事件特征间的依赖关系.对此,研究描述各显性特征和事件诱因之间依赖关系的知识模型构建,以及基于知识模型估计事件诱因的方法,是本文研究的基本思想和主要出发点.
贝叶斯网[8](Bayesian Networks,BN)作为一种重要的概率图模型,被广泛应用于不确定性知识表示和概率推理等领域.鉴于BN对变量间的依赖关系同时具备定性和定量两方面的表达能力,以及概率推理方面具有的显著优势,本文将BN作为基本知识框架,并构建能描述事件特征与事件诱因之间依赖关系的事件诱因模型.
其次,事件诱因无法直接获取与观测.相对于事件发生的时间、地点、类型和规模等可直接观测的显性特征,诱导事件发生的诱因不可直接观测.因此,如何描述和刻画事件诱因,是进行事件诱因估计的前提和基础.隐变量可用来描述不能直接观测取值的变量,因此,我们在BN中引入隐变量来描述事件诱因.含隐变量的BN,简称为隐变量模型[8](Latent Variable Model,LVM),不仅可以简化模型结构、使显变量之间的依赖关系更加清晰,还有利于发现和表达数据中存在的隐含信息.以COVID-19事件为例,该事件包括季节、类型、规模和级别4个显性特征,通过引入领域知识得到如图1(a)所示的包含部分依赖关系的BN,引入事件诱因这一隐变量得到如图1(b)所示的LVM.

图1 关于事件的BN和LVMFig.1 BN and LVM w.r.t. events
从图1可以看出,LVM可以简化复杂的依赖关系,从而降低模型复杂程度,增强模型的可解释性.因此,本文以隐变量来描述事件特征数据中蕴含的事件诱因,构建能够刻画变量间依赖关系的LVM.然而,现有隐变量模型构建方法[9,10]通常从数据或理论方面出发,忽略了对实际情况中相关领域知识的描述,且未考虑显变量和隐变量之间依赖关系强度的定量计算,使得这些方法针对事件诱因估计等具体应用的准确性不高,甚至与实际情形不吻合.对此,Yue等[11]使用LVM表示隐变量和显变量之间的依赖关系,提出了一种用户偏好贝叶斯网构建方法,该方法可以较好地表达评分数据中隐含的用户偏好,这为本文中隐变量模型的构建提供了一种思路.
综上,本文以突发公共事件为背景,关注新闻事件的季节、类型、规模和级别这4个显性特征.分析新闻事件领域知识可知,事件特征数据中蕴含的诱因往往不止一个,因此,本文引入一个多值隐变量,以隐变量不同的取值描述事件诱因的不同组合,并基于LVM给出事件诱因模型(Event Inducement Bayesian Networks,EIBN)的定义,进而利用事件特征数据构建EIBN.
然而,隐变量的引入会导致事件特征数据缺失.期望最大算法[12](Expectation Maximization,EM)是一种可以对缺失数据进行填充并进行参数计算的有效算法,结构期望最大算法[13](Structure Expectation Maximization,SEM)可以学习LVM的结构.因此,本文基于EM算法及SEM算法进行EIBN模型构建.首先,根据事件领域知识给出用于模型学习的结构约束和初始结构.其次,针对小样本情形下BIC评分[14]和AIC评分[15]在模型选择中可能导致的模型拟合问题[16],本文通过对BIC评分与AIC评分取期望值来调节罚项大小,并基于BIC评分和AIC评分提出了BAIC(Bayesian-Akaike Information Criterion)评分方法.最后,使用EM算法计算EIBN模型参数,并结合SEM算法、结构约束和BAIC评分给出EIBN模型构建方法.
此外,诱导事件发生的诱因可能不唯一,影响事件发生的诱因往往不止一个且对显变量的依赖程度不同.因此,根据已构建的EIBN模型,基于变量消元法[17](Variable Elimination,VE)进行概率推理,将事件诱因估计转化为从多个诱因取值中选取最优取值子集的优化问题,并基于优先队列式分支限界思想给出提取诱因最优取值子集的方法.
通过建立在真实数据集上的实验测试了本文所提方法,实验结果验证了本文方法的有效性.
2.1 EIBN模型定义
定义1[8]. BN是一个描述节点及节点间依赖关系的有向无环图(Directed Acyclic Graph,DAG),节点表征随机变量,有向边表征节点间的依赖关系.如果存在X→Y的有向边,则称X是Y的父亲节点,Y是X的孩子节点.BN每个节点都有一张条件概率表(Conditional Probability Table,CPT),用以定量描述节点间依赖关系的程度.
定义2. EIBN是含一个隐变量的BN,用(G,θ)表示:
G=(V,X)为DAG结构,其定性地描述了EIBN各节点间的依赖关系.其中,V={S,T,E,L,I}表示节点集,隐变量节点I={1,2,…,s}表示事件诱因有s个取值,S、T、E、L共4个显变量节点分别对应事件数据中的季节、类型、规模和级别,X为节点间依赖关系的集合.θ表示EIBN中各节点CPT集合.
2.2 基于约束及BAIC的EIBN模型构建
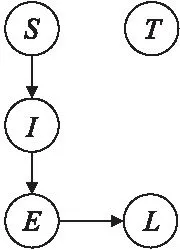
图2 基于约束1的初始结构Fig.2 Initial structure based on constraint 1
2.2.1 约束描述
首先针对SEM算法对初始值的敏感性,根据事件领域知识给出约束1,基于约束1的EIBN初始结构如图2所示.其次,为减少EIBN模型结构学习过程中的候选模型数量,给出用于候选模型剪枝的约束2.
约束1.事件诱因影响事件规模,事件规模决定事件级别,且事件发生季节对事件诱因存在一定影响.因此,模型初始结构的边必须包含
约束2.事件类型T和季节S不依赖其他任何变量,即模型结构的边不存在由其他变量指向T和S的边.因此,EIBN模型中不存在
2.2.2 EIBN模型参数学习
假设当前模型为(Gt,θt,0),其中t表示结构学习次数,完成r-1次参数学习后得到当前模型(Gt,θt,r-1).I=i表示隐变量I的取值为i,s表示诱因取值个数,Dd表示第d个数据样本,|D|=n.第r次迭代由以下E步和M步完成.
E步:基于式(1)和(Gt,θt,r-1)将缺失数据集D修补为带权完整数据集Dt,r-1,并利用式(2)计算第r次迭代的期望对数似然函数Q(θ|θt,r-1).
P(I=i|Dd,θt,r-1)=P(I=i,Dd|θt,r-1)∑si=1P(I=i,Dd|θt,r-1)
(1)
Q(θ|θt,r-1)=∑nd=1∑si=1P(I=i|Dd,θt,r-1)logP(I=i,Dd|θ)
(2)
M步:利用式(3)计算使Q(θ|θt,r-1)最大的θt,r.
θt,r=argsupθQ(θ|θt,r-1)
(3)
上述E步和M步反复迭代至算法收敛,得到EIBN模型参数θt,r.
2.2.3 EIBN模型构建
假设t表示结构学习迭代次数,logP(D|Gt,θt,r)为当前模型(Gt,θt,r)的对数似然函数,d(Gt)表示(Gt,θt,r)的独立参数个数.在模型选择过程中,小规模数据样本情形下BIC评分可能导致模型过拟合而AIC评分欠拟合的问题.对此,本文通过对BIC评分与AIC评分取期望值来调节罚项大小,并基于BIC评分和AIC评分提出了BAIC(Bayesian-Akaike Information Criterion)评分准则,如式(4)所示.BAIC评分能够更有效地衡量EIBN的数据拟合度和模型复杂度,避免模型对数据的过度拟合.
算法1. 基于约束和BAIC评分的EIBN模型构建
输入:D:事件特征数据集r:参数学习最大迭代次数
输出:EIBN模型(G,θ)
步骤:
1.t←0;
newScore←-∞
2.基于约束1生成初始结构G°;
基于θt,0随机生成初始参数θ0,0
3.WHILEtrueDO
4. 对当前模型(Gt,θt,0)进行参数学习得到(Gt,θt,r)
5. 利用(Gt,θt,r)和式(1)得到带权完整数据集Dt,r
6.oldScore←BAIC(Gt,θt,r|D)
7.FOReachG*IN对Gt进行加边、减边及反转边
得到满足约束1和约束2的候选模型集合DO
8.θ*,r+1←计算G*对应参数的最大似然估计
9.tempScore←BAIC(G*,θ*,r+1|D)
10.IFtempScore>newScoreTHEN
11. (G′,θ′)←(G*,θ*,r+1);
newScore←tempScore
12.ENDIF
13.ENDFOR
14.IFnewScore>oldScoreTHEN/*继续迭代*/
15.t←t+1;
(Gt,θt,0)←(G′,θ′)
16.ELSE
17.RETURN(Gt,θt,r) /*迭代结束*/
18.ENDIF
19.ENDWHILE
BAIC(Gt,θt,r|D)=logP(D|Gt,θt,r)-d(Gt)4logn-d(Gt)2
(4)
因此,本节基于EIBN模型参数学习、SEM算法、结构约束和BAIC评分给出EIBN模型构建方法.首先,基于约束1产生EIBN初始结构,并基于初始结构随机生成初始参数.其次,利用EM算法学习模型参数.然后,利用加边、减边及反转边操作生成一系列候选模型,并利用约束1和约束2进行剪枝,仅保留满足约束的候选模型.最后,分别计算不同候选模型参数的最大似然估计,并利用式(4)进行打分,保留BAIC评分最高的候选模型.若最优候选模型的BAIC评分大于当前模型的BAIC评分,则将最优候选模型作为当前模型继续迭代;
否则,结束迭代并返回当前模型作为结果.参数学习和选择最优候选模型的过程反复迭代至算法收敛.上述思想见算法1.

图3 EIBN候选模型结构Fig.3 Candidate structures of EIBN
例如,初始模型(G0,θ0,0)的结构如图2所示,通过t次结构学习得到当前模型(Gt,θt,0)的结构见图3(a).首先进行参数学习得到(Gt,θt,r),并通过加边、减边及反转边生成满足约束的候选模型结构Ga和Gb,见图3(b)和(c).其次,利用式(3)、式(4)计算Ga和Gb对应参数和BAIC评分,并将BAIC评分最高的(Ga,θa,r+1)作为最优候选模型.最后,由于BAIC(Ga,θa,r+1|D)大于BAIC(Gt,θt,r|D),故将(Ga,θa,r+1)作为当前模型继续迭代至算法收敛.
针对事件诱因存在多个取值的问题,本文基于变量消元法和分支限界法给出EIBN的事件诱因估计方法.
首先,令每个事件的诱因取值集合为IV={I1,I2,…,Is},其中s表示诱因取值个数,Ii∈{0,1}表示第i个诱因是否被选中,被选中为1,否则为0.然后,在给定事件数据中显性特征对应的显变量作为证据变量的条件下,基于变量消元法计算事件诱因不同取值的概率,获得诱因概率集IP={P1,P2,…,Ps},其中,Pi表示事件取第i个诱因的概率.本文基于IV与IP提出诱因贡献度(Inducement Contribution Degree,ICD)的概念,用以衡量第i个诱因对事件影响程度,第i个诱因取值的ICD如式(5)所示.
ICDi=PiIi(1≤i≤s)
(5)
其次,令ICD的最大值ICDmax,最小值ICDmin.此时,事件诱因估计问题可转化为:从IV中选取这样的诱因子集,该子集对应的诱因贡献度之和最大且大于αICDmin,同时小于αICDmax,其中=1/(P1+P2).据此,本文基于优先队列式分支限界思想给出EIBN的事件诱因估计方法.
1)约束条件和目标函数
基于事件的诱因取值集合IV与诱因贡献度ICD,约束条件和目标函数分别如式(6)和式(7)所示.
αICDmin<∑si=1ICDi<αICDmax,α=1P1+P2
Ii∈{0,1},1≤i≤s
(6)
max∑si=1ICDi
(7)
其中,满足上述约束条件和目标函数的诱因子集即为事件诱因估计的结果.
2)限界函数
假设已选择了前j个诱因,令当前满足约束条件的前j个诱因组成的诱因子集为IVj,对应诱因贡献度之和为∑ji=1ICDi,则计算节点诱因贡献度上界的限界函数见式(8).
BF(IVj)=∑ji=1ICDi+(s-j)Pmax
(8)
其中,Pmax=argmaxp{Pj,Pj+1,…,Ps}表示剩余诱因对应的最大概率值,s-j表示剩余诱因个数.
事件诱因估计是一个最优子集提取问题,我们以子集树表示解空间树,设bestICD和bestIV表示当前的目标函数最大值和对应诱因子集.从查找效率出发,待处理节点表采用大顶堆H存储.事件诱因估计的具体思想如下:
Ⅰ将根节点加入待处理节点表.
Ⅱ若待处理节点表非空,则选取BF(IVj)最大的节点作为当前节点;
反之,结束算法.
算法2. EIBN的事件诱因估计
输入:(G,θ):EIBN模型
E:事件数据中作为证据变量的显性特征
Q:作为查询变量的事件诱因节点
e:事件数据中显性特征的取值
ρ:消元顺序队列,即所有不在E和Q中的变量
s:诱因取值个数
输出:事件诱因的最优取值子集bestIV
步骤:
1.获得EIBN中所有节点对应概率分布函数集合F
2.基于(G,θ),E=e,Q,ρ,F利用变量消元法进行概率推理得到诱因概率集IP
3.bestICD←0;
bestIV←∅;
H←∅
4.r_node.IV←{};
r_node.BF←0 /*根节点*/
5.addNode(H,r_node);
buildMaxHeap(H)
6.WHILEH!=∅DO
7.c_node←removeMaxNode(H) /*限界函数最大*/
8.j←rnode.IV+1
9.FORtIN{0,1}DO
10.e_node.IV←c_node.IV∪{Ij=t}
11.IFe_node.IV满足式(6)ANDj=sAND∑si=1ICDi>bestICDTHEN
12.bestICD←∑si=1ICDi;
bestIV←e_node.IV
13.ELSEe_node.IV满足式(6)ANDj ANDBF(e_node.IV)>bestICDTHEN 14.r_node.BF←BF(e_node.IV) 15.addNode(H,e_node); 16.ENDIF 17.ENDFOR 18.RETURNbestIV Ⅲ分别检查在当前节点下Ij=0和Ij=1对应扩展节点是否满足式(6),如果满足则执行Ⅳ,否则执行Ⅱ. Ⅳ当扩展节点为叶子节点时,若对应ICD大于bestICD则将该节点作为当前最优解; 上述思想见算法2,并将得到的诱因最优取值子集作为EIBN模型诱因估计的结果. 实验数据集:本文将搜狗新闻(1)https://news.sogou.com/、中国应急网(2)http://www.emerinfo.cn/gjzq/gjdt/index.htm及中国地震网(3)https://www.cea.gov.cn/cea/xwzx/rdbd/cb58908c-1.html爬取的突发事件数据与中文突发事件语料库CEC(4)https://github.com/shijiebei2009/CEC-Corpus汇总后构成突发事件数据集,该数据集包含地震、火灾、恐怖袭击、食物中毒等突发事件,共16124条数据.通过Jieba分词和TextCNN分类模型对数据集处理后,抽取本文所关注的影响事件诱因的4个特征,并分别将每一条事件数据表示为4个基于影响因素的特征,得到16124条特征数据集.将特征数据集随机划分为80%的训练集和20%的测试集,分别用于EIBN模型构建和实验测试. 基于测试集数据,将生物诱因、自然诱因、人为诱因及其组合共7种诱因取值,根据对事件影响程度非升序排序,并取Top-k诱因作为真实诱因.首先,为单个诱因赋影响权值w1、w2、w3,并基于事件类型判断权值大小.其次,去除最小权值对应的诱因,并记其权值为负数.最后,将每种诱因对应的权值求和,并将其作为该种诱因对事件的影响程度. 评测标准:从有效性与效率两个方面对本文所提方法进行测试.有效性测试主要包括诱因估计与初始约束两个方面,其测试指标包括准确率、召回率、F1值,计算分别如式(9)-式(11)所示.我们对每个评测指标均进行5次测试,并将5次的评测指标取平均值作为最终评测指标值. Precision=Num(true)Num(estimation) (9) Recall=Num(true)Num(reality) (10) F1=2×Precision×RecallPrecision+Recall (11) 其中,Num(true)表示已估计出的正确诱因数,Num(estimation)表示估计诱因总数,Num(reality)表示实际诱因总数. 对比方法:基于训练数据构建事件诱因模型EIBN、协同过滤模型CF[2]及主题模型LDA[5],并基于测试集分别测试3种方法诱因估计结果的准确率、召回率和F1值.分别将3种方法发现的Top-k诱因作为估计诱因,将测试集中得到的Top-k诱因作为实际诱因,进而计算3种方法诱因估计的准确率、召回率及F1值.对于CF,构建事件相似矩阵和诱因对事件的影响矩阵,并通过矩阵相乘得到事件-诱因矩阵,按照矩阵元素取值从高到低排序,前Top-5元素对应的诱因取值作为事件估计诱因.对于LDA,首先构建文档-词频概率矩阵,将每类事件视为文档,将事件之间的相似度视为词频概率; 实验环境:Intel(R) Core(TM) i9-10850K CPU @ 3.60 G Hz处理器,128GB内存,Windows 10(64位)操作系统,使用Scala 2.12.6作为编程语言. 参数设置:EM算法迭代次数上限为10次,收敛阈值为0.001; 图4 不同数据规模下的诱因估计结果Fig.4 Inducement estimation on different sized data 为了测试EIBN诱因估计的有效性,本文基于相同规模测试集将其与CF和LDA两种方法的诱因估计作对比.首先,利用训练集分别构建EIBN、CF及LDA模型.然后,基于不同规模的测试集测试3种方法诱因估计的准确率、召回率和F1值,结果如图4所示.可以看出,EIBN模型在任何测试集规模情况下测试指标均优于CF和LDA,且EIBN在不同规模测试集的准确率均高于65%.在不同规模测试集情况下,EIBN诱因估计的准确率比CF和LDA模型分别高6.77%~10.24%和11.66%~14.01%,平均高出8.51%和12.84%,这是因为EIBN模型引入隐变量来描述事件诱因,使其能够较好地表达事件特征间任意依赖关系,说明了本文所提出方法的有效性. 表2 Top-k诱因估计结果Table 2 Top-k inducement estimation(a)准确率 (b)召回率 (c)F1值 接着,分别测试了3种方法Top-k(k=1,2,3,4,5)诱因估计的准确率、召回率及F1值,结果分别如表2(a)、(b)、(c)所示.可以看出,随着Top-k的增加,EIBN、CF和LDA这3种方法诱因估计的准确率、召回率及F1值分别减少、增加和趋于稳定.此外,3种方法Top-1诱因估计的准确均高于62%且EIBN模型在任何Top-k情况下测试指标均高于CF和LDA,不仅说明估计的诱因一定程度上反映了事件实际诱因,还说明本文诱因估计方法的有效性. 为了测试本文初始约束条件的有效性,设置了基于约束1和约束2、基于约束1、基于约束2及无约束4种情形,并在不同规模训练数据集下测试模型构建的BAIC评分值,结果如表3所示.表3展示了随着数据规模的增大,不同约束条件下的BAIC评分.可见,在相同数据规模下,同时基于约束1和约束2的BAIC评分最高,基于约束1的BAIC评分次之,而无任何约束的BAIC评分最低,说明了同时基于约束1和约束2所构建的EIBN模型具有较好的数据拟合性,同时说明了本文初始约束设置的有效性. 表3 不同约束下EIBN模型的BAIC评分(×104)Table 3 BAIC score w.r.t. EIBN under various constraints 为了测试模型构建效率,本文基于不同规模训练数据集,测试了不同约束条件下EIBN模型构建的执行时间,结果如图5所示.可以看出,无论在何种规模的训练集情况下,基于约束1、基于约束2及同时基于约束1和约束2的执行时间均比无约束情况的执行时间短,说明了本文基于初始约束1、2构建EIBN模型的高效性,这是由于约束1和约束2给出了在EIBN模型中必须存在的依赖关系.通过在结构学习过程中利用约束对候选模型结构进行剪枝,减少候选模型数量,从而减少需要计算的参数个数,提升结构学习效率. 接着,本文还基于不同规模训练数据集测试了模型构建时间,并按照是否调用参数学习算法和结构学习算法将构建时间分为模型构建总时间、参数学习时间和结构学习时间,结果如图6所示.可以看出,随着数据规模增大,EIBN各部分学习时间总体呈线性增长,说明了本文模型构建方法对大规模数据集具有良好的可扩展性.此外,可以看出结构学习时间和参数学习时间分别占比58.02%、41.98%.其中,结构学习耗时最长,参数学习次之,这与EIBN模型构建过程包括结构学习和参数学习的事实相符,也说明了本文通过设置初始结构约束来提高模型构建效率的必要性. 图5 不同约束下的EIBN模型构建时间Fig.5 Execution time w.r.t. EIBN construction under various constraints图6 不同数据规模下的EIBN模型构建时间Fig.6 Execution time w.r.t. EIBN construction on different sized data 本文从新闻事件特征数据出发,分析并描述了突发事件数据中蕴含的知识,以多值隐变量描述事件诱因的多个取值,提出事件诱因模型构建方法,并基于概率推理算法及分支限界思想提出一种有效估计事件诱因的方法.在真实数据上的实验验证了本文方法的有效性. 然而,作为基于概率图模型进行事件诱因估计的初步研究,本文所构建的事件诱因模型未考虑数据的动态演化.因此,研究如何基于现实世界中动态变化的事件特征数据对事件诱因模型进行增量学习,是我们未来的主要研究方向.
buildMaxHeap(H)
当扩展节点不是叶子节点时,利用式(8)计算节点上界,若节点上界大于bestICD,则将其加入待处理节点表,否则对该节点进行剪枝.然后,继续执行Ⅱ.4.1 实验设置
然后,将诱因作为主题,并使主题与诱因取值一一对应,进而训练模型得到事件-诱因矩阵,取前Top-5概率对应的主题作为事件估计诱因.
SEM算法迭代次数上限为10次,收敛阈值为0.00001.4.2 EIBN诱因估计的有效性




4.3 初始约束条件对EIBN构建的有效性

4.4 效率测试










