基于深度学习的医疗文本分类模型
时间:2023-06-25 20:55:03 来源:雅意学习网 本文已影响 人 
彭清泉,王丹
(1.华中科技大学同济医学院附属同济医院肾内科,湖北武汉 430030;
2.华中科技大学同济医学院附属同济医院综合医疗科,湖北武汉 430030)
医疗文本数据蕴含着丰富的医学知识,利用深度学习技术对医疗文本进行分析研究,从而生成有效的医疗信息,为临床决策提供数据支持,提高整体医疗质量[1-2]。
静态词向量模型Word2vec[3]和Glove,预训练过程缺乏词的位置信息,导致无法表示多义词。动态词向量模型ELMO[4]和BERT[5],预训练过程中结合词的具体上下文语境进行学习,提升了词向量表征能力。ChineseBERT[6]模型将汉字特有的字形和拼音信息融入预训练过程,使模型更加综合地建立汉字、字形、读音与上下文之间的联系。
医疗文本分类方法主要有机器学习方法和深度学习方法,文献[7]利用LDA 模型进行特征提取来构建低维度向量,但需要复杂的人为特征构建工程,不能确保获取特征的全面性和准确性。在深度学习领域,文献[8]提出了LS-GRU 医疗文本分类模型,解决了GRU模块特征提取能力不足的问题,采用Word2vec模型将医疗文本向量化,得到的静态词向量语义表征能力较弱。文献[9]针对评论文本情感极性判断问题,提出了BERT-BiLSTM 情感分类模型,BiLSTM 模块受限于循环依赖机制,导致训练效率较低。以上模型均赋予每个词相同权重得分,无法聚焦于对分类结果影响较大的关键词。
针对医疗文本分类研究仍然存在的问题,提出了ChineseBERT-BiSRU-AT 医疗文本分类模型,主要贡献和创新点如下:
1)针对传统向量模型无法表示多义词问题,采用ChineseBERT 将医疗文本向量化,得到词的动态向量表征。
2)为提升模型整体训练效率,采用简单循环单元[10]提取文本序列信息。
3)软注意力机制计算每个词对分类结果的影响大小,赋予模型识别关键特征的能力。
1.1 模型整体结构
基于ChineseBERT-BiSRU-AT 的医疗文本分类模型整体结构如图1 所示。主要由医疗文本预处理、ChineseBERT 预训练模型、双向简单循环单元语义提取层、软注意力机制和分类层组成。文本预处理将医疗文本处理成能够输入模型的数据格式;
ChineseBERT 模型负责学习词的动态语义表示;
双向简单循环单元学习句子序列高维语义特征,软注意力机制计算每个词的权重大小,分类层得到医疗文本分类结果。

图1 模型整体结构
1.2 医疗文本预处理
首先对医疗文本数据集进行数据清洗,通过编写正则表达式删除部分特殊字符,并去除部分不合规样本。使用ChineseBERT 分词器对医疗文本进行字符级别分词操作,按照词汇表序号将字符替换成序号表示;
根据序列最大长度对文本进行首部截断或后补0,首尾位置分别加入句首标志[CLS]和分句标志[SEP],得到文本的静态语义向量表示。
1.3 ChineseBERT预训练模型
模型ChineseBERT 针对汉字特性,将字形与拼音信息融入到预训练过程,增强对中文语料的建模能力。特征抽取模块为Transformer 编码器,自注意力机制捕捉词与词之间的依赖关系,提取句法结构信息[11]。字形嵌入由多个不同字体图像向量化后融合而成,拼音嵌入则由对应的罗马化拼音字符序列经过CNN 模块训练得到。模型整体框架如图2 所示。

图2 ChineseBERT模型结构
其中,融合嵌入由字嵌入、字形嵌入与拼音嵌入经过一个全连接层融合得到,相关过程如图3 所示;
e={e1,e2,…,en}为输入向量,由融合嵌入和位置嵌入相加组成,位置嵌入PE计算过程如式(1)、(2)所示。经Transformer 编码器动态训练后得到的词动态语义表示T={T1,T2,…,Tn},Ti表示第i个词的语义向量表示,作为BiSRU 层的输入向量。

图3 融合向量组成
1.4 双向简单循环单元BiSRU
简单循环单元(Simple Recurrent Unit,SRU)摆脱了对上一个时间状态输出的依赖,提高并行计算能力,加快序列处理速度,较LSTM 模型[12]运算速度更快,参数更少。单个SRU计算公式如式(3)-(6)所示。
其中,⊙表示矩阵对应元素的乘法运算;
Wt、Wr、W、bf、br、vf和vr均为模型中的可学习参数;
rt和ft分别代表重置门和遗忘门,用于控制信息流入下一步的程度并缓解梯度消失与爆炸问题[13]。由式(6)可知,计算时间步状态ht不再依赖上一个时间步输出ht-1,提高模型并行处理速度。为增强SRU 对文本语义的建模能力,将前向SRU 和后向SRU 合并为BiSRU 模块,得到t时间步BiSRU 输出状态Ht。
1.5 软注意力机制层
软注意力机制计算每个词的权重大小,赋予对分类结果影响大的焦点词更高权重,有助于提升模型分类性能[14]。将BiSRU 层获取的文本高维序列特征H输入到软注意力机制层,计算每个时间步输出Ht的权重at,加权求和后得到注意力特征A,计算过程如式(7)-(9)所示。
其中,tanh(·)为非线性函数,exp(·)为指数函数。
将软注意力特征A映射到实例分类空间,由Softmax()函数计算得到文本属于某个类别的概率大小,Top(·) 取行最大值对应的标签作为分类结果Result,计算过程如式(10)、(11)所示。
2.1 数据集与评价标准
实验数据集为患者呼吸科影像,经数据清洗后得到合格样本856 例;
采用文本描述、诊断字段分别作为样本内容和标签。数据集包含肺气肿408 例和肺炎448 例,按照8∶1∶1 将数据集划分为训练集、测试集和验证集。
为验证模型在医疗文本分类任务上的有效性,采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数作为评价指标。计算过程如式(12)-(15)所示。
2.2 实验环境与模型参数设置
采用Pytorch1.7.1 深度学习框架和python3.6.0 及其他第三方库进行模型训练,采用Linux 操作系统,GTX3080 显卡,显存24 GB。模型参数设置如下:BiSRU 隐藏层大小128,层数2;
随机失活概率大小为0.5,L2 正则化系数为0.1;
训练轮次为5 次,损失函数为多交叉熵损失函数;
软注意力机制维度256;
序列最大长度为100;
批处理大小为64,初始学习率为1×10-5;
引入RAdam[15]优化器,自动调整学习率大小,避免频繁手动调整。
2.3 实验对比设计
为验证模型有效性,采用近期表现优秀的深度学习模型进行对比。为降低实验随机误差,固定随机数种子,并取10 次实验结果的平均值作为最终结果,选取对比模型如下:
1)LS-GRU[8]:文献[8]提出的LS-GRU模型,LSTMGRU 模块提取序列特征。
2)BERT-BiLSTM[9]:文献[9]提出的BERT-BiLSTM模型,BERT 模型得到结合具体上下文语境的词向量表示,BiLSTM 抽取文本全局序列信息。
2.4 结果分析
模型实验结果如表1所示,ChineseBERT-BiLSTM和ChineseBERT-BiSRU 模型训练时间如图4 所示。由表1 可得,该文提出的ChineseBERT-BiSRU-AT 模型F1 得分最高,优于近期表现较好的LS-GRU 和BERT-BiLSTM 模型,证明了ChineseBERT 与BiSRUAT 结合的有效性。

图4 模型训练时间
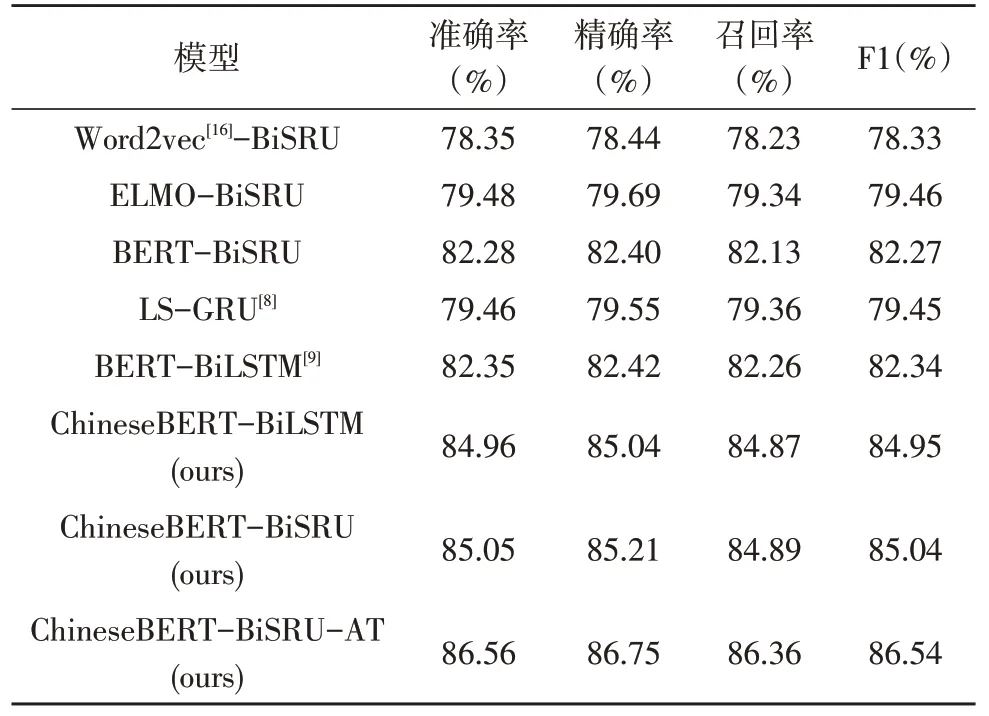
表1 性能指标对比
与模型Word2vec-BiSRU、ELMO-BiSRU 和BERT-BiSRU 相对比,ChineseBERT-BiSRU 模型的F1分数分别提升了6.71%、5.58%和2.77%,说明了ChineseBERT 将汉字字形和拼音信息融入中文语料预训练过程,通过参考词的上下文联系,学习到语义表征能力更强的动态词向量,应用效果优于其他词向量模型。静态词向量模型Word2vec 训练过程缺乏词的位置信息,无法表示多义词,F1 分数较低,而ELMO 和BERT 模型能够结合词的上下文语境进行动态编码,效果优于Word2vec。BERT 采用了特征提取能力更强的Transformer 编码器,ELMO 则使用了双向LSTM,因此模型BERT-BiSRU 的F1 分数高于ELMO-BiSRU。
设置实验ChineseBERT-BiSRU 与ChineseBE RT-BiSRU-AT 进行对比,结果表明软注意力机制计算每个词的权重大小,聚焦于对分类结果影响较大的关键特征,能够有效提升模型分类性能。
由图4 可得,ChineseBERT-BiSRU 模型轮次训练时间均低于ChineseBERT-BiLSTM,BiSRU 模块训练效率优于BiLSTM,降低模型训练复杂度,但仍保持着高效的序列建模能力。
综上所述,该文提出的ChineseBERT-BiSRUAT 模型能够有效地提升医疗文本分类性能。
针对医疗文本分类问题,提出了基于Chinese BERT-BiSRU-AT 的医疗文本分类模型。通过ChineseBERT 模型学习到结合具体上下文语境的动态词向量表征,解决了传统词向量无法表示多义词问题,应用效果优于实验对比的其他词向量模型。采用BiSRU 模块进行序列特征提取,训练效率优于BiLSTM。软注意力机制能够识别出关键词,赋予较高权重。利用医疗影像报告数据集进行实验,结果表明ChineseBERT-BiSRU-AT 模型在医疗文本分类任务上的有效性。在未来的研究中,将考虑进一步提升模型训练速度,并将该模型迁移到其他文本分类领域。
猜你喜欢注意力语义向量向量的分解新高考·高一数学(2022年3期)2022-04-28让注意力“飞”回来小雪花·成长指南(2022年1期)2022-04-09聚焦“向量与三角”创新题中学生数理化(高中版.高考数学)(2021年1期)2021-03-19语言与语义开放教育研究(2020年2期)2020-03-31“扬眼”APP:让注意力“变现”传媒评论(2017年3期)2017-06-13A Beautiful Way Of Looking At Things第二课堂(课外活动版)(2016年2期)2016-10-21“上”与“下”语义的不对称性及其认知阐释现代语文(2016年21期)2016-05-25向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23认知范畴模糊与语义模糊大连民族大学学报(2015年2期)2015-02-27








