基于重建误差的任务型对话未知意图检测
时间:2023-06-20 21:55:03 来源:雅意学习网 本文已影响 人 
毕然,王轶,周喜
(1.中国科学院新疆理化技术研究所,乌鲁木齐 830011;
2.中国科学院大学,北京 100049;
3.新疆民族语音语言信息处理实验室,乌鲁木齐 830011)
意图识别[1]是任务型对话系统[2]自然语言理解(Natural Language Understanding,NLU)模块[3]中的子任务,旨在识别用户隐藏在对话语句中的真实意图。随着深度学习技术的发展,意图识别研究不断深入并取得诸多成果。然而在真实场景中,用户意图随着时间推移频繁变化,系统无法针对未在训练过程中出现的新意图进行有效检测。
目前,针对未知意图检测任务主要包括基于生成对抗网络(Generative Adversarial Networks,GAN)[4-6]、基于置信度分数[7-8]以及基于异常 检测[9-10]3 类方法。基于生成对抗网络的方法生成大量与已知意图在空间上接近的未知意图,再将两者送入分类器学习,然而无法解释生成样本的合理性,且GAN 在文本离散数据中可能表现不佳。基于置信度分数的方法会输出一个额外的置信度分数衡量测试样本属于已知意图或未知意图的概率,然而该方法需要足够且类别分布均匀的样本训练分类器,在类别分布不平衡时可能失效。基于异常检测的方法先通过改进交叉熵损失[11-12]训练分类器,使模型的类间方差最大化、类内方差最小化,各类别特征的空间分布界限分明,再通过局部异常因子(Local Outlier Factor,LOF)[13]算法将测试样本中的离群点视为未知意图,然而经过交叉熵损失训练得到的特征簇分布相对狭长[14],无法保证特征簇的整体间距、密度和分散情况均匀一致,导致LOF 算法的检测效率受到影响。
本文提出一种基于重建误差的未知意图检测模型LeCosRE,优化特征的空间分布,利用自动编码器无法重建非正类样本的特性检测未知意图。在训练阶段:首先使用融入标签知识的联合损失函数LeCos 训练已知意图分类器,使各类别特征尽可能向自身的类别中心靠拢;
然后利用自动编码器[15-17]充分学习已知意图的相关信息,并将其作为未知意图检测器。在测试阶段,利用自动编码器重建已知意图特征,从而将已知意图与未知意图进行有效区分。
1.1 意图识别
任务型对话系统先判断用户意图,再提取语句中的关键槽值[18],最终将整合的信息传递给对话管理模块,从而完成后续回复。目前,考虑到意图识别和槽值提取任务间存在较大的相关性,许多研究人员将两者作为联合任务进行训练。XU等[19]基于CNN 的方法通过聚合相邻单词的词嵌入从而构建句子嵌入表示。LIU等[20]基于RNN 的方法将单词的词嵌入进行顺序编码以此提取句子嵌入表示。CHEN等[21]将BERT 引入自然语言理解任务,解决了传统模型泛化能力较差的问题。ZHANG等[22]提出意图-槽值联合训练应在语义层面共享参数的思想,并基于BERT 的方法先检测用户的意图,再通过整体的语义信息和意图语义信息预测槽值的位置。
任务型对话在学术界和工业界得到越来越多关注,但也面临一些挑战,例如如何提高数据使用效率以促进资源匮乏环境中的对话建模[23]。当对话系统预设的意图类别不能满足用户在真实场景下的全部需求时,系统虽然可以利用已有的标注数据训练一个具有较强判别能力的分类器,但在出现新意图时无法进行有效回复。
1.2 未知意图检测
传统意图识别任务训练及测试阶段数据标签类别相同,即在测试阶段不会引入一类完全不同于训练阶段意图类别的新意图。目前,关于未知意图检测问题的研究较少,其研究难点是无法在训练阶段获取未知意图的任何信息。LIN等[9]使用增强边缘余弦损失(Large-Margin Cosine Loss,LMCL)训练已知意图分类器,使模型的类间方差最大化,并在测试时使用LOF 算法检测离群点作为未知意图,而其余正常点送入分类器。LOF 算法是一种基于密度的离群点检测算法,通过对每个特征点分配一个依赖于邻域密度的离群因子判断其所属。YAN等[10]假设学习到的特征服从高斯混合分布,提出增强语义的高斯混合损失(Semantic-Enhanced large-margin Gaussian mixture loss,SEG)以提高特征的类内紧凑性,更符合LOF 算法的要求。
图像领域自动编码器(autoencoder)和生成对抗网络的应用为未知意图检测提供了思路。自动编码器是一种无监督的神经网络模型,目的是完成对原始输入的重建,其数据相关性(data-specific)导致无法拓展一种编码器在另一类数据上应用,可以作为检测离群点的工具。AN等[15]利用变分自动编码器的重建概率进行判别,已知样本的重建概率较未知样本更高。SABOKROU等[24]训练一个生成对抗网络,将生成器作为数据重构器,判别器作为未知检测器,将样本依次通过数据重构器、未知检测器和Sigmoid 函数获得概率值进行判断。本文利用自动编码器重建误差的思想代替LOF 算法检测未知意图,解决因特征分布不均匀导致检测效率不高的问题。
2.1 任务定义
使用训练集Dtr=(Xtr,Ytr)训练模型,其中,Xtr是训练集语句,Ytr是训练集的意图标签,标签Ytr∈{y1,y2,…,yk}=Cseen均属于已知意图,k表示已知意图类别数。在测试阶段,测试集Dte=(Xte,Yte)中的意图标签Yte既包含已知意图Cseen,又包含未知意图yk+1=Cunseen。模型针对训练阶段并未出现未知意图这一情况,旨在对测试集中的已知意图语句进行正确分类,并检测出更多的未知意图。
2.2 整体模型
本文提出的LeCosRE 模型整体架构如图1 所示。在训练第一阶段,每个已知意图语句x通过基于自注意力机制的双向LSTM 网络编码为特征zx。同时,用相同方法编码每个已知意图标签Cseen,通过融入标签知识的联合损失函数LeCos 训练已知意图分类器,不断优化网络参数。在训练第二阶段,根据提取的特征zx训练自动编码器作为未知意图检测器,将训练结束时已知意图特征的平均重建损失作为阈值。在测试阶段,测试语句x先通过特征提取得到zx,再通过自动编码器得到重建特征,重建误差大于阈值则判为未知意图,标签记为Cunseen,重建误差小于等于阈值标签记为Cseen并正常分类。

图1 LeCosRE 模型整体架构Fig.1 Overall architecture of LeCosRE model
2.3 特征提取
给定一个具有T个词语组成的语句x={w1,w2,…,wT},wt∈Rdw是第t个词嵌入表示,每个词语被双向LSTM 编码,如式(1)所示:

单词wt的词向量由连接前向推算结果和后向推算结果表示,即,综合所有词向量得到的语句向量表示为H=[h1,h2,…,hT]∈R2dh×T。此外,利用自注意力机制可以更有效地捕捉关键词语,提升整体的语义表示,对H进行以下操作:

其中:a∈RT是自注意力权重向量;
Ws1∈Rda×2dh和Ws2∈R1×da是可训练的参数,da表示自注意力权重向量维度,dh表示隐状态向量维度;
Ws∈Rdz×2dh也是可训练的前馈权重参数,dz表示句向量维度。在训练过程中对H的每个词表示赋予不同权重,zx∈Rdz是x的最终表示。
2.4 已知意图分类器
交叉熵损失在许多问题上被广泛使用,然而经WEN等[14]验证,交叉熵损失训练得到的特征虽在类间可分,但类内距离较大,每类特征的空间分布相对狭长。传统的交叉熵损失如式(3)所示:

其中:pi是特征向量zx属于类别i的概率;
N为训练样本个数;
C为分类类别总数;
fj一般是全连接层的激活值,可以通过网络的权重W及偏移量b计算。若将偏移量设置为0,则fj可以表示为如下形式:
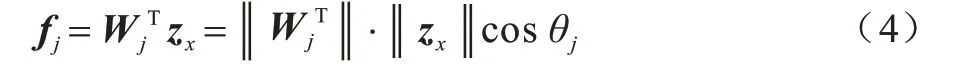
其中:θj是Wj和特征向量zx的角度。
W和zx的范数及两者间的夹角影响分类置信度,对权重归一化处理,并将最后一个全连接层的输入zx的范数固定为s,交叉熵损失如式(5)所示:


全连接层的权重和输出的特征需要进行归一化操作,如式(7)所示:

Llmc无法避免特征分布相对狭长的问题,决策边界占据很大空间,挤压类别特征分布的范围。因此,本文第一个创新点是引入中心损失[14]约束类内距离紧凑,如式(8)所示:

其中:Lcenter要求每个特征与其类别中心距离的平方和尽可能小;
n表示类别标签为yi的特征个数;
zi表示全连接层之前的特征;
cyi表示第yi个类别的特征中心。cyi经过随机初始化后会在训练过程中更新梯度及自身位置,如式(9)所示:

若特征的标签yi和cj的类别相同,则δ(yi=j)=1,cj需要更新;
若yi和cj的类别不同,则δ(yi=j)=0,cj不需要更新。此外,将每个类别的标签yi通过2.3 节特征提取模块得到的特征表示作为类别中心不停迭代以此替代cyi,每个已知意图特征zi学习标签知识,使得同类特征间相似度更大、不同类特征之间相似度更小,融入标签知识的中心损失Lcenter如式(10)所示:

Llmc和Lcenter均通过梯度下降算法不断减小,因此利用结合Llmc和Lcenter的损失函数LLeCos训练已知意图分类器,如式(11)所示:

其中:λ表示超参数。
2.5 未知意图检测器
本文第二个创新点是使用自动编码器检测未知意图,解决LOF 算法对于特征的空间分布要求较高的问题。自动编码器结构如图2 所示。

图2 自动编码器结构Fig.2 Structure of autoencoder
编码器通过非线性仿射映射将输入zx映射到隐藏表示h中。

其中:Wzxh是编码器的权重;
bzxh是编码器的偏移量;
σ是非线性变换函数。
解码器通过与编码器相同的变换将隐藏表示h映射回原始空间输出。

其中:Whzx′是解码器的权重;
bhzx′是解码器的偏移量。
在训练自动编码器的过程中,本文对特征输入zx添加一项微小的高斯随机白噪声η模拟训练集和测试集之间的差异性,增加模型的鲁棒性[24]。训练过程使用均方损失训练使输出zx′与输入zx+η的误差尽可能小,训练结束时样本的平均重建损失作为判断未知意图的阈值。
训练自动编码器全程只有已知意图特征参与,自动编码器充分学习了已知意图的信息,而未知意图的特征只包含极少量已知意图的信息,已知意图和未知意图通过自动编码器得到的重建误差不同。已知意图重建后与原特征点偏移距离较小,而未知意图则与原特征点的偏移距离较大,如图3 所示。

图3 测试样本的重建差异Fig.3 Reconstruction difference of test samples
在测试阶段,将测试样本的特征表示zx输入自动编码器得到重建特征表示。若重建误差大于阈值,则该样本属于未知意图;
若重建误差小于等于阈值,则该样本属于已知意图并正常分类。
3.1 数据集与基线模型选取
在SNIPS[25]和ATIS[26]两个真实的任务型对话数据集上对本文提出模型进行评估。SNIPS 数据集是一个开源的多领域单轮对话数据集,包含7 种类型的用户意图,每个意图的数据量较为平均。ATIS 数据集是航空旅行领域的对话数据集,包含18 种类型的用户意图,且每个意图的数据量极为不平衡。两个数据集的详细信息如表1 所示。

表1 SNIPS 和ATIS 数据集详细信息 Table 1 Details of SNIPS and ATIS dataset
基线模型主要包括:MSP[7]和DOC[8]为每个 样本输出一个置信度分数,分数越小越有可能属于未知意图;
LMCL[9]和SEG[10]尝试优化损失函数并利用LOF 算法判断未知意图。LeCos 可以视为损失函数的有效性验证。
3.2 实验设置与参数说明
参照SEG 的实验设置,对数据集的所有意图类别加权,抽取相应比例的已知意图类别,并把其余意图类别视为未知。随机从每个意图中选取30%的数据作为测试集,剩余70%数据中的已知意图类别数据作为训练集。此外,由于ATIS 数据集中一个意图的样本量占总体的96%,意图分布极不平衡,使用Macro F1 得分作为评价指标。
对于SNIPS 和ATIS 数据集中的样本分别使用300 维的FastText 和Glove 预训练词向量进行嵌入表示。在特征提取模块中,设置双向LSTM 的层数为2,输出维度dz为128,自注意力层中注意力向量的长度T为10。在训练已知意图分类器模块中,选取间隔m为0.35,范数s为30,融入标签知识的中心损失中的超参数λ为0.5。每个语句经过训练由一个256 维的特征向量进行表示。在未知意图检测器模块中,将256 维的向量分别通过一个128 维、64 维和32 维的线性层,每次降维后使用Tanh 激活函数增加非线性因素,并用对称的结构重建向量至256维。
对于基线模型,按照原文献的参数设置进行实验。设置MSP 和DOC 的阈值为0.5,在训练时使用梯度截断避免梯度爆炸问题。设置LMCL 的超参数m=0.35、s=30。设置SEG 的超参数m=1、λ=0.5,经过特征提取模块后得到的特征均为12维。由于LMCL 和SEG 均使用LOF 作为未知意图检测器,因此对LOF 算法设置的超参数进行统一。为证明本文提出模型具有适应性,将所有模型运行超过5 次实验的平均结果作为最终结果。
3.3 不同模型在SNIPS 数据集上的实验结果对比
在已知意图占比为25%、50%和75%时,各模型整体Macro F1 得分如表2 所示,各个占比的前两名结果均用粗体标记。LeCos 损失函数在LMCL 基础上进行改进,融入标签知识后整体Macro F1 得分均有所提升,证明了标签知识的有效性。此外,LeCosRE 未知意图检测模型在已知意图占比为25%、50%、75%时均获得了比基线模型更好的结果,Macro F1 得分相比于表现最优的SEG 基准模型分别提升了16.93%、1.14%和2.37%,尤其在训练集样本类别和数量较小的情况下,整体样本的Macro F1得分大幅提升。

表2 SNIPS 数据集上的Macro F1 得分对比 Table 2 Comparison of Macro F1 score on the SNIPS dataset
3.3.1 损失函数实验结果与分析
图4 为分别使用LMCL 和LeCos 对训练集已知意图样本进行训练及样本特征经t-SNE 降维后的可视化图像。

图4 LMCL 和LeCos 训练集样本特征分布Fig.4 Sample feature distribution with LMCL and LeCos training set
由图4 可以看出,经LeCos 训练的已知意图特征在空间表现上效果更好,LeCos 不但在类间添加了足够的间隔距离,也使每个意图类别的特征向其类别中心靠拢。
测试集样本特征经t-SNE 降维后的可视化图像如图5 所示,其中,Seen 代表已知意图特征,Unseen代表未知意图特征。

图5 LMCL 和LeCos 测试集样本特征分布Fig.5 Sample feature distribution with LMCL and LeCos test set
由图5 可以看出,训练集和测试集间具有差异性。经LMCL 学习的特征分布更加狭长,甚至有类别间重合的情况,且有一个已知意图类别的特征被未知意图特征基本覆盖,增加了LOF 算法的检测难度,而LeCos 较LMCL 的特征分布更加合理。
3.3.2 未知意图检测实验结果与分析
使用自动编码器代替LOF 算法作为未知意图检测器,在已知意图占比为25%时已知、未知意图样本的识别准确率及Macro F1 得分如表3 所示,其中最优指标值用粗体标记。

表3 SNIPS 数据集上已知意图占比为25%时的准确率及Macro F1 得分 Table 3 Accuracy and Macro F1 score when the proportion of known intents is 25% on the SNIPS dataset
在未知意图检测阶段,LeCos 表示使用LOF 算法,而LeCosRE 表示使用自动编码器,本文也验证加入一个极小的随机噪声即LeCosRE w/o noise 可以模拟训练集及测试集间的差异性。由表3 可以看出,LeCosRE 在已知意图占比较小时,对于已知意图和未知意图的检测效果明显提高。
表4 和表5 分别是已知意图占比为50%和75%时已知意图与未知意图的识别准确率及F1 得分,其中最优指标值用粗体标记。由表4、表5 可以看出,LeCosRE 可以在基本不影响已知意图分类整体水平的情况下,检测出更多的未知意图,尤其是语义与已知意图较为类似的未知意图,使系统的整体性能进一步提升。

表4 SNIPS 数据集上已知意图占比为50%时的准确率及Macro F1 得分 Table 4 Accuracy and Macro F1 score when the proportion of known intents is 50% on the SNIPS dataset

表5 SNIPS 数据集上已知意图占比为75%时的准确率及Macro F1 得分 Table 5 Accuracy and Macro F1 score when the proportion of known intents is 75% on the SNIPS dataset
可见,自动编码器重建误差的方法较LOF 算法能检测出更多未知意图的原因主要为:1)两者确定已知意图边界的方式不同,LOF 算法更倾向于使每类意图的样本尽可能保持同一密度,但特征分布很难保证这一前提,而自动编码器的优势在于其数据相关的特性,可以得到针对已知意图更合理的边界;
2)在训练自动编码器时,加入微小的高斯随机白噪声项用于模拟训练集与测试集之间的差异性,通过实验对比可知,随机噪声可提升模型的鲁棒性。
3.4 不同模型在ATIS 数据集上的实验结果对比
为验证本文提出模型的通用性,在ATIS 数据集上的实验结果如表6 所示,在3 种已知意图占比下的前两名结果均用粗体标记。

表6 ATIS 数据集上的Macro F1 得分对比 Table 6 Comparison of Macro F1 score on the ATIS dataset
ATIS 数据集是一个类别分布极不平衡的数据集,其中一个意图“flight”的样本量占总体的96%,将该意图始终划为已知意图。在这种条件下,LeCos仍可以获得不错的分类效果,而本文提出的模型LeCosRE 在已知意图占比为25%时较现有模型提升明显,主要原因总结为以下2 点:
1)ATIS 数据集是航空旅行领域的对话数据集,不同意图语句间的关联性比SNIPS 数据集更强,且其中一个意图“flight”的样本量占总体的96%,特征提取模块学习到的信息基本只有“flight”本身。在测试时未知意图特征在空间分布上表现为散落在“flight”内部或周围。对于该意图内部的未知意图特征点,所有模型基本无法有效检测,而LeCosRE 较仅使用LOF 算法学习到的已知意图的特征边界更加合理,因此可以检测到更多在该意图周围的未知意图。ATIS 数据集上已知意图占比为25%时的未知意图检测结果如表7 所示,可以看出LeCosRE 学习的特征分布更加合理,已知意图的识别效果提升明显,对于未知意图检测效果也更好。

表7 ATIS 数据集上已知意图占比为25%时的准确率及Macro F1 得分 Table 7 Accuracy and Macro F1 score when the proportion of known intents is 25% on the ATIS dataset
2)“flight”样本量过大,会导致无法有效学习监督分类器。ATIS 数据集除“flight”意图外,其余意图只有几十个甚至几个样本。当已知意图占比更大时,没有足够的样本训练已知意图分类器,分类结果不理想。Macro F1 得分的评价指标容易受样本量较少类别意图的影响,因此各模型整体Macro F1 得分均不高。尤其MSP 和DOC 随已知意图占比的增加,整体Macro F1 得分骤降。
为解决在实际应用场景中用户语句与对话系统预设意图不相符以至于无法进行有效检测的问题,本文提出基于重建误差的未知意图检测模型LeCosRE。首先使用融入标签知识的联合损失函数LeCos 训练已知意图分类器,使得已知意图特征的空间分布类间距离大且类内距离小。然后使用已知意图特征训练自动编码器作为未知意图检测器,由于自动编码器仅学习已知意图的相关信息,对未知意图的重建误差较大,因此可以检测出更多的未知意图样本。在SNIPS 和ATIS 数据集上的实验结果表明,LeCos 损失函数赋予不同类别样本更为合理的空间分布,LeCosRE 未知意图检测模型可以提升对话系统整体性能,并检测出更多的未知意图样本,尤其在训练样本数量、类别较少的情况下检测效果相比于基线模型提升明显。后续将尝试利用胶囊网络、BERT 等网络结构结合联合损失函数对语句特征进行学习,探索更适合下游任务的特征空间分布,提升未知意图检测效率。
猜你喜欢编码器意图类别原始意图、对抗主义和非解释主义法律方法(2022年2期)2022-10-20融合CNN和Transformer编码器的变声语音鉴别与还原网络安全与数据管理(2022年1期)2022-08-29陆游诗写意图(国画)福建基础教育研究(2022年4期)2022-05-16制定法解释与立法意图的反事实检验法律方法(2021年3期)2021-03-16基于FPGA的同步机轴角编码器成都信息工程大学学报(2018年3期)2018-08-29壮字喃字同形字的三种类别及简要分析民族古籍研究(2018年1期)2018-05-21应用旋转磁场编码器实现角度测量西安工程大学学报(2016年6期)2017-01-15服务类别新校长(2016年8期)2016-01-10基于数字信号处理的脉冲编码器探测与控制学报(2015年4期)2015-12-15多类别复合资源的空间匹配浙江大学学报(工学版)(2015年1期)2015-03-01








