基于维度-标签信息的多元情绪回归方法
时间:2023-06-12 20:30:14 来源:雅意学习网 本文已影响 人 
谭惜姿,朱苏阳,李寿山,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
随着社交网络的发展,监测互联网用户的具体情绪或他们对热点的情感态度,在政府决策、舆情监测和分析消费者情绪等方面,发挥着重要的帮助作用[1]。情绪分析是一种细粒度的情感分析任务,旨在分析文本所蕴含的情感取向或是情感强度,是自然语言处理领域中的研究热点[2-4]。目前,情绪分析可以分为两类方法: 情绪分类[5]和情绪回归[6]。与传统的情感分类不同(仅仅将文本分成正面、负面和中立三大类别),情绪分析旨在将文本标注为一系列的情绪类别,如“高兴”“悲伤”等等(情绪分类);
或者对文本的情绪维度进行打分,如“极性(Valence)”维度、“强度(Arousal)”维度和“可控性(Dominance)”维度(情绪回归)。这两种方法均可细分为读者情绪和写者情绪。例如,在新闻领域中的一条报道:
Iraq says the United States and Britain hold up delivery of needed supplies using their clout in the United Nations.
从读者的角度出发,会产生气愤、不满的情绪;
而从写者的角度出发,由于是新闻报道,因此其包含的情绪更倾向于客观、中立。
由于情绪分类的语料库较为丰富,且分类的结果可以直观反映出情感取向,所以在目前的情绪分析研究中情绪分类的方法占据主导地位。但是情绪分类依旧存在局限性: 由于不同语料的分类方法不同,用某种语料训练的情绪分类模型难以迁移到其他的语料中,在模型迁移方面有着很大的局限性。例如,Golubev等人[7]使用了在2013年提出的ROMIP新闻语料库以及从Twitter社交网络上收集的推文语料库SentiRuEval,这两个语料库的情感分类均为正面、负面和中立;
Jabreel等人[8]提出了一种基于深度学习的多标签情绪分类模型,该方法所针对的情绪标签为11种;
Yu等人[9]使用了双重注意力机制捕获重要的情感词,在中文的情绪分类语料库上进行了判别8种情绪标签的分类任务。由此可见,由于不同的情绪分类任务往往涉及到不同的情绪分类体系,因此,尽管情绪分类的相关研究取得丰硕的成果,但仍然受制于模型难以迁移的问题。
情绪回归方法的研究是基于Barrett等人[10]所提出的极性-强度-可控性模型展开的。该模型是由心理学界公认的用于描述情绪的极性-强度模型所拓展而来的,具有较高的公认性,因此回归模型的迁移难度较低。尽管如此,情绪回归研究的最大瓶颈在于语料的匮乏,目前较为常用的语料库为Buechel等人[11]所提出的EMOBANK,其中包含了10 000多条多维度情绪回归文本。除了大规模的语料库匮乏之外,在现有的方法中,情绪回归模型的准确率并不高,某一维度的准确率大约在0.3左右[12],可见情绪回归是一个有难度的任务。
在极性-强度-可控性的三维评分空间模型中,如图1所示,我们观察到不同的情绪标签具有不同的维度分值,每种情绪的维度分值都有一定的特点和规律,如“Disgust”“Fear”和“Sadness”等负面情绪具有较高的可控性,但在另外两个维度上的分值差别较大。因此我们认为情绪标签与维度之间必然存在某种关联信息,能用于判别情绪维度分数的高低或者情绪类别标签的不同。然而,该信息在过去的情绪分析研究中并未被充分利用。基于上述原因,本文拟提出一种能够利用情绪的维度-标签信息的情绪回归方法。该方法的特点如下:
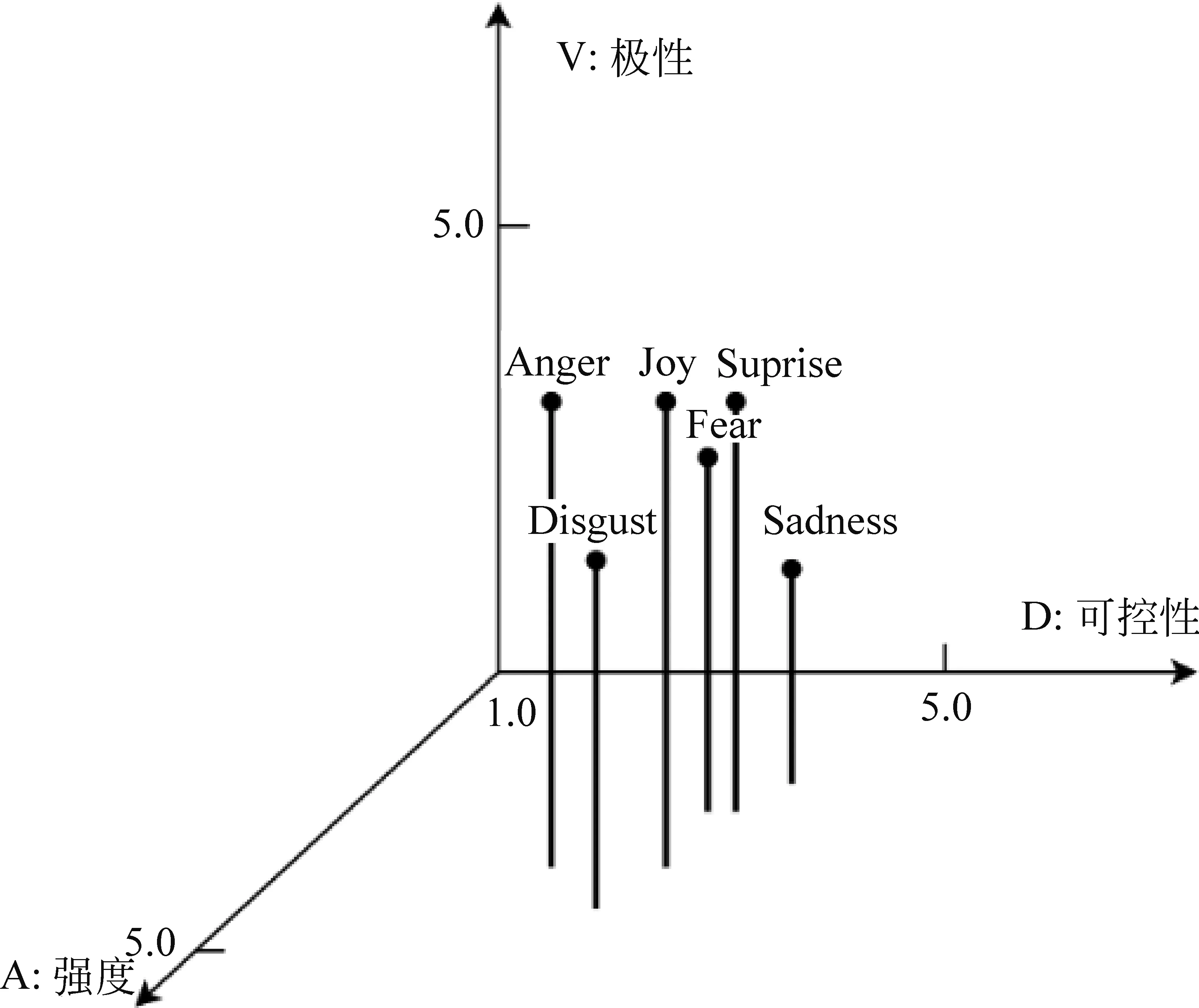
图1 强度-可控性-极性三维情感评分空间模型
(1) 利用了标签与维度之间的关联信息,从而利用情绪分类资源来帮助情绪回归任务的学习。如图1所示,若能知道输入文本的类别,那么可以判别其情绪维度的基本范围,例如,“Anger”类别在可控性维度上具有较低的分值。
(2) 过去的情绪回归方法只能对单个情绪维度进行打分,情绪分类和情绪回归任务不能同时展开[13],而本文所提出的方法可以同时对多个维度和类别进行学习,同时预测输入文本的维度分值与所属类别,减少了训练模型的数量,提高了模型的学习效率。
(3) 到目前为止,研究人员尚无利用情绪标签与情绪维度分值之间的关联性进行情绪回归的工作,因此用情绪类别标签辅助情绪回归任务是一种新颖的、具有开创性的方法。从实验结果来看,本文所提出的方法优于其他基准系统和自然语言处理领域内的先进系统,尤其在极性和强度两个维度上取得了较好的效果。
本文第1节介绍情绪分类和情绪回归的相关工作;
第2节详细介绍本文所提出的维度-标签信息的多元回归模型;
第3节通过具体实验来验证本文方法的有效性;
最后,第4节总结本文并展望未来的工作。
1.1 情绪分析
情绪分析的研究开始较早,从早期简单的支持向量机模型到现在广泛使用的深度学习模型,研究者们为提高模型的分析性能,提出了许多具有实用价值的语料库,例如,Reddy等人[14]提出了一种混合语言(坎纳达语-英语)的情绪分类语料,样本均来自推特,总共包含了156 000个单词;
Öhma等人[15]标注了一种多语言的细粒度情绪数据集XED,包括了英语、芬兰语等30种其他语言的标注结果,为低资源语言提供了新的资源。近些年,随着多模态研究的兴起,文本、图像、语音相结合的情绪语料库也逐渐出现,例如,Poria等人[16]提出了两人以上的大型多模态多方对话情感数据库,包含了音频、视觉和文本的形式。上述语料库均为情绪分析的研究提供了丰富的基本训练材料。
情绪分类和情绪回归是情绪分析中的两大任务。情绪分类旨在通过分析文本的情感特征,判断该文本的情感类别,具体如表1所示。研究人员已从不同的分类方法中提出了各种相应的模型。例如,He等人[17]提出了一种联合二值神经网络的方法(JBNN)。在该方法中,文本的特征表示通过一组逻辑函数和多个二值分类器在一个神经网络框架中同步进行,更好地满足了情感分类的需求,在Ren-CECps语料[18]上训练所得的8分类模型平均准确率可达71.72%。由此可见,目前情绪分类的研究成果已相当丰硕。

表1 情绪分类与情绪回归的具体样例
1.2 情绪回归
情绪回归的主要任务是给输入文本的多个维度进行评分,在本文中涉及三个维度: 极性(Valence)、强度(Arousal)和可控性(Dominance),回归模型将对输入文本的三个维度进行预测评分,具体如表1所示。该多维度的情感评分空间模型如图1所示。这三种维度都包含了不同的意义[11],极性倾向于表达情绪正负面的差异程度,该值越大表示属于正面情绪的可能性越大,反之属于负面情绪的可能性较大;
强度表示冷静或兴奋的程度;
可控性表示对某种情境的感知控制程度,即在特定情境下,情绪演变的难易程度。例如,表1中的第一条文本,让人产生伤心(Sadness)的情绪较为容易,因此可控性分值较高。情绪回归的研究到目前为止依旧较少,研究人员所提出的模型均是基于单任务的情绪回归模型。例如,Zhu等人[12]提出了一种用对抗注意力网络来完成多维情绪回归的任务,具体来说,该模型引入了注意力层来权衡输入序列中的单词,在注意力层之间采用对抗性训练,通过鉴别器学习到更好的权值;
Wang等人[19]提出一种区域CNN-LSTM模型,由区域CNN和LSTM两部分组成,预测文本的价值感知评分。
相比情绪分类任务,情绪回归起步较晚,主要原因有两个,一是情绪回归无法直观体现情绪的态度,二是现有的情绪回归语料匮乏。但情绪回归对情绪分析研究具有重大意义: ①可以客观地反映情感的强烈程度,而不仅仅是类别;
②由于每个维度之间是独立的,即使缺少某个维度(如极性)的情况下,在其他维度方面也依然具有可比性;
③不受制于分类方法,易于在其他语料库上训练。
目前,情绪分类和情绪回归的研究大多是独立展开的,但实际上,情绪分类的研究成果比情绪回归更加丰富且性能更好。因此,本文将结合情绪分类的方法,辅助情绪回归任务,从而取得了比单任务模型更好的预测结果。总体来说,本文方法的主要贡献如下:
(1) 可以对输入文本的多个维度同时预测分值,不需要每个维度单独展开,减少了需要训练的模型个数,提高了模型学习效率。
(2) 不再是单一的回归模型,在对文本进行回归预测的同时对其进行分类,利用情绪分类的输出概率,更正回归预测的结果。
3) 构造了新的损失函数,尽可能最大化两个不同情绪标签之间的空间表示距离,使得输入文本之间的特征更具有区别性。
本节将详细阐述本文所提出的基于维度-标签信息的多元情绪回归模型。首先介绍本文的任务定义与模型基本框架;
接着介绍基于BERT的特征提取模块、本文所提出的维度-标签信息学习模型,以及情绪分类辅助情绪回归的方法。
2.1 任务定义
本文方法将对输入文本进行3维度的回归预测,以及m个情绪标签的分类。包含n个输入文本的表示方法为:X={x1,x2,…,xi,…,xn},其中,xi为第i个文本。本文的回归模型称为维度-标签信息学习模型,该模型的最终输出向量分两类: 一类是预测的情绪维度分数,另一类是预测的类别概率,表达如式(1)所示。
yi=(y′i1,y′i2)
(1)
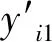

图2 基于维度-标签信息的多元情绪回归方法的主要框架
2.2 基于维度-标签信息的多元情绪回归模型框架
本文实现了一种多元情绪回归模型,主要框架如图2所示。首先,输入文本X,通过原始的BERT模型[20]进行特征提取,接着通过本文所提出的维度-标签信息学习模型进行训练;
最后输出为对应文本的强度-极性-可控性分值以及类别标签概率。
2.3 基于BERT的特征提取模块
BERT[20](Bidirectional Encoder Represen-tation from Transformers)作为一种预训练模型,具有良好的泛化性,近几年在自然语言处理领域得到了广泛使用[21-24]。该模型采用了Transformer[25]中的 Encoder 模块进行连接,是一个典型的双向编码模型。首先,该模型利用大规模的无标注语料,训练获得文本丰富的语义信息(语义表示);
然后将文本的语义表示在特定的自然语言处理领域做微调(fine-tuning),以适应下游任务。BERT 模型的特征提取主要框架如图3所示,其输入为原始文本,输出是融合了全部语义信息之后的向量表示,包括了词向量(Token Embeddings)、分段向量(Segment Embeddings)和位置向量(Position Embeddings)。其中词向量运用了Wu等人[26]提出的WordPiece方法,即将单词进行拆分,例如“playing”拆分成“play”和“##ing”。分段向量用于区别不同的句子,可用标签“A”“B”等来表示。位置向量标记每个输入单词的顺序。此外,每一段序列前还需加上“[CLS]”标志,在最后一层隐藏层中,该位对应的向量可作为整个输入文本的语义表示,运用于下游的分类任务;
每个句子的结尾必须加上“[SEP]”标志,用于区别不同的序列。
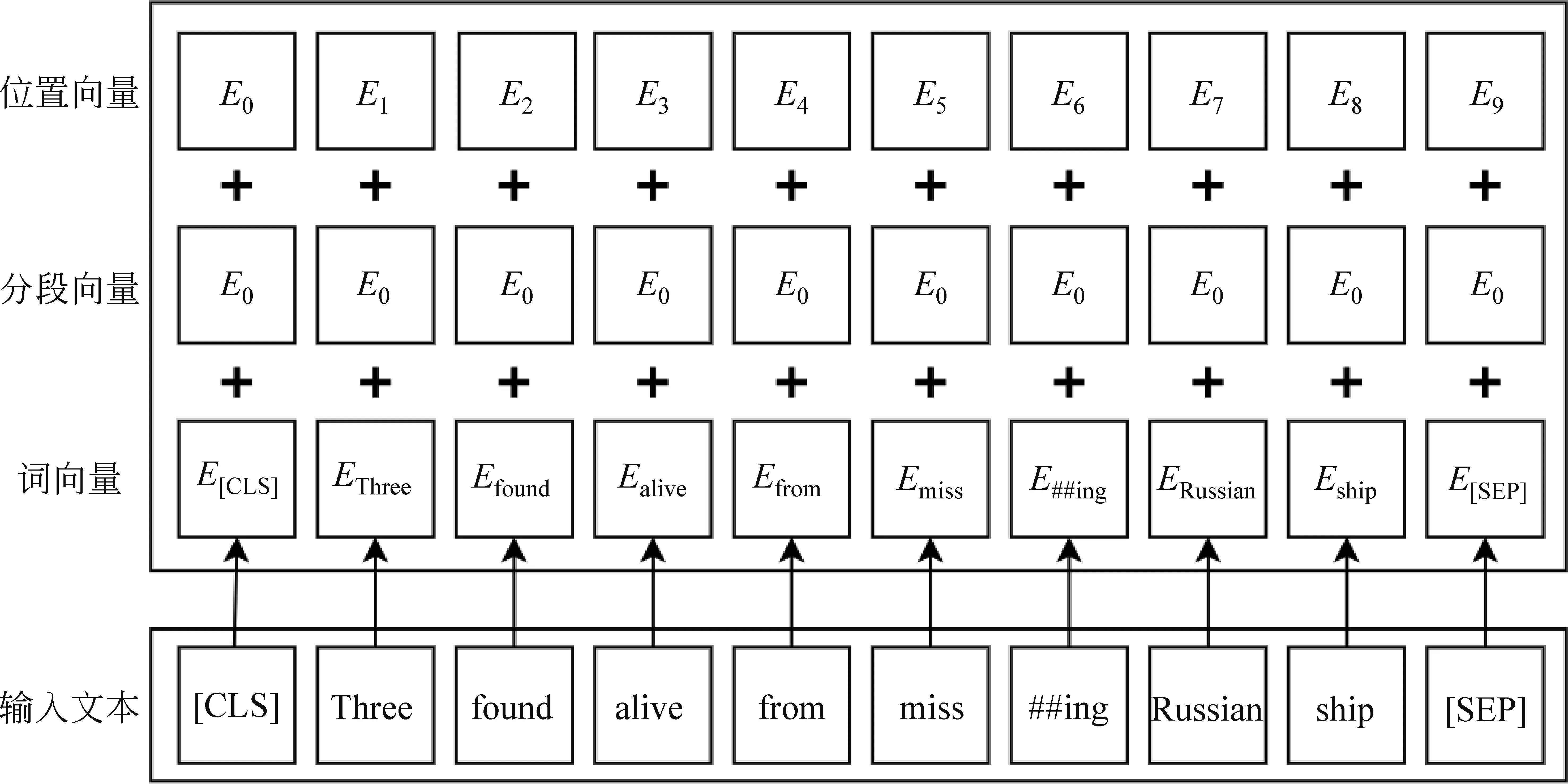
图3 基于BERT的特征提取模块主要框架

2.4 基于维度-标签信息的学习模型
这一模块会利用到维度-标签信息,从而构成一个新的模型,其基本结构建立在BERT模型之上。
BERT由多个隐藏层组成,每一层由两个子层组成,包括: 多头注意力机制和位置式全连接前馈网络,其中,多头注意力机制由多个可缩放的点乘注意力机制组成,每一层都使用了残差连接和标准化,因此可以将子层的输出表示如式(2)所示。
LayerNorm(x+SubLayer(x))
(2)
其中,x为输入文本,SubLayer(x)为子层的输出结果。BERT模型的整体基本框架如图4所示。
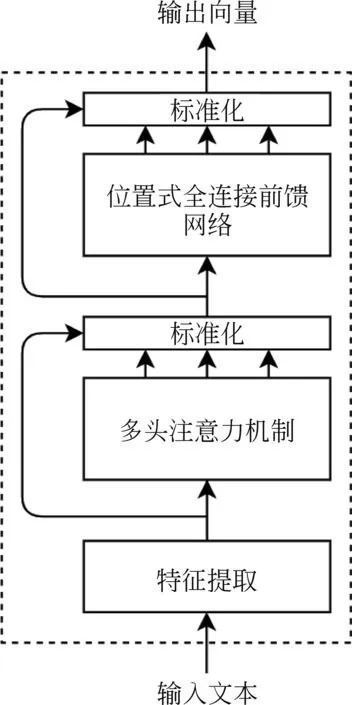
图4 基于BERT模型的主要框架
本文提出的基于维度-标签信息学习模型将通过减小相同类别标签之间的空间表示距离,达到优化情绪回归算法的目的。这里的距离我们分别使用了三种不同的方式: 余弦相似度、KL散度和欧氏距离。
2.4.1 基于欧氏距离的损失函数
(3)
EucDistij=
(4)

在原有的模型中,使用的均方误差损失函数表示为MSELoss,而在本文方法中的损失函数可表示如式(6)所示。
其中,B为批的大小(即每次送入网络中训练的数据的个数,在训练开始前人为设定),yi为该批中第i个输入文本的当前预测结果。
2.4.2 基于余弦相似度的损失函数
为了进一步找到更适合于情绪回归任务的损失函数,我们考虑了方向信息对预测结果的影响,因此引入了余弦相似度,用式(7)、式(8)来表示不同情绪标签之间的空间表示距离。
其中,Cosineij为第i个预测分值与第j个类别的平均值之间的余弦相似度。
此时,损失函数的计算方式如式(9)所示。
(9)
2.4.3 基于KL散度的损失函数
KL散度是衡量两个概率分布之间差别的非对称性度量。KL散度值越小,说明数据分布越相似,可以用于判别预测分值与真实分值之间的差异性。因此,我们认为KL散度可以作为损失函数的一部分,来帮助情绪回归任务,此时不同情绪标签之间的空间表示距离可以表示如式(10)、式(11)所示。
(10)
(11)
其中,KLij为第i个预测分值与第j个类别的平均值之间的KL散度。
此时,损失函数可以表示如式(12)所示。
(12)
通过上述方法让原有的损失函数更加适用于情绪回归任务。随后,利用新的损失函数继续训练维度-标签信息学习模型,三种不同的损失函数我们将在后续进行对比分析,最终该模型的输出包括了三维情绪分值和情绪类别的预测概率,如式(13)所示。
yi=(y′i1,y′i2)
(13)
本节首先介绍本文实验所使用的数据集,接着给出实验设置,包括本文方法所使用的参数和评价回归性能的指标;
然后介绍本实验中所用到的基准系统,展示本文方法与其他基准系统的对比实验,最后,将对实验结果进行详细的分析。
3.1 数据集
本文选取了EMOBANK[11]数据集中既包含维度分值又包含类别标签的样本,其内容均为新闻标题,包括了1 229条读者情绪样本和1 212条写者情绪样本,该部分主要用作训练集。此外,我们手工标注了来自GoEmotions[27]数据集中的读者情绪样本和写者情绪样本各200条,用作测试集,该部分的情绪分类体系与训练集相同。每一条样本均包括一句新闻标题文本、强度-可控性-极性分值和对应的情绪类别序号。其中,强度-可控性-极性分值区间为[1.0,5.0]。表2给出了该数据集在三维情绪模型上的平均分值。情绪类别共有6种,分别为: anger、disgust、fear、joy、 sadness、surprise。

表2 各类别在强度-可控性-极性维度下的平均值

续表
从表2可以看到,无论是读者情绪还是写者情绪,平均值大约为3.0,数据分布较为集中,读者情绪的平均值区间为[2.39,3.25],写者情绪的平均值区间为[2.54,3.18]。其中,写者的强度维度上各类别的差别非常小,说明通常情况下写者情绪较为稳定。
3.2 实验设置
本实验共使用了两种评估方法: 均方误差(Mean Square Error,MSE)和皮尔森相关系数(Pearson’s correlation coefficient,用r表示)。均方误差是指数据估计值与数据真值之差平方和的平均数,MSE越小表示模型具有更小的估计值;
皮尔森相关系数主要用于衡量两个数据分布之间的相关性,r值的范围为[-1,1],越接近0表示数据分布越不相关,具体表示如式(14)、式(15)所示。

表3给出了本文方法在训练时的超参设置,所有参数均是在本文所用的测试集上调试的。

表3 本文方法中的超参设置

续表
3.3 基准系统
为了验证本文方法在情绪回归任务中的优越性能,我们使用了以下基准系统进行对比实验。
(1)LSTM: 该系统为基于长短时记忆网络的回归模型[28],输入样本经过一层有256个神经元的LSTM层之后输入到有128个神经元的全连接层,最终输出预测的分值。
(2)CNN: 该系统为基于卷积神经网络的回归模型[29],输入样本经过3个有128个滤波器的卷积层之后(核大小为2,3,4,步长为1),输入到全连接层来完成回归任务。
(3)GRU: 该系统为基于门控循环单元的回归模型[30],输入样本经过两个GRU层,其中第一层GRU包含128个神经元,第二层GRU包含64个神经元,最后再通过全连接层来预测情绪维度的分值。
(4)BERT: 该系统为Devlin等人[20]提出的神经网络模型,是一种典型的双向编码模型。为适应情绪回归任务,本实验中采用的损失函数为均方误差。该系统的输出与本文方法相同。
(5)XLNet: 该系统为Yang等人[31]在BERT基础上提出的可泛化自回归预训练模型。该模型主要有两个特点: 一是最大化了一个序列的期望对数似然,即所有可能的因子分解顺序的排列;
二是不依赖于数据破坏,同时提供了一种消除BERT中独立性假设的方法。该模型在20种任务中均取得了比BERT更好的性能。
(6)MTL: 该系统为Akhtar等人[32]提出的多任务集成模型,主要由CNN、LSTM、GRU和手动提取特征模块组成,这种方法既可用于情绪分类也可用于情绪回归。该文的实验结果表明,这方法比单任务模型有更好的预测结果。
3.4 对比实验与结果分析
本节主要进行三种对比实验,一是比较本文所提出的三种损失函数对回归性能的影响,找到最适合情绪回归的损失函数;
二是比较本文方法与其他基准系统的回归性能,验证本文所提出的方法对改善情绪预测的分值是有效的;
三是研究分类方法对回归性能的影响,尤其是分类准确率对回归性能的帮助。
3.4.1 损失函数的对比与分析
为了对比欧氏距离、余弦相似度和KL散度参与损失函数计算之后对回归性能的影响,我们进行了对比实验,实验结果如表4所示。从实验结果来看,余弦相似度和KL散度的误差依旧较大,尤其是在读者领域,极性维度的MSE值均在0.25以上,可控性维度的r值均不超过0.1。相比之下,欧氏距离有着更好的预测能力,例如,在读者和写者两个领域中极性维度的r值均超过0.5,与此对应的MSE值在三种方法中是最低的。对于这种现象,我们猜想这是因为情绪回归模型对数值大小更加敏感,余弦相似度包含方向信息,而方向信息对预测结果的帮助并不大,甚至有可能起到误导作用;
而本文在计算KL散度时,所挑选的真实分布是三个维度在具体类别上的平均值,与真实值有一定的差别,对情绪回归的帮助有限。综上所述,为了获取更好的情绪回归结果,我们认为欧氏距离在参与损失函数计算时对提升回归性能的帮助最大。

表4 “余弦距离”“KL散度”与“欧氏距离”参与损失函数计算对于回归性能的影响
3.4.2 回归系统的对比与分析
表5给出了本文方法与6种基准系统在均方误差(MSE)和皮尔森相关系数(r)上的对比实验结果。
从整体的数据来看,本文方法的整体回归性能比其他方法更优越。

表5 本文方法与其他基准系统的对比实验结果
从三个不同的回归维度上看,极性维度的r值得分普遍较高,说明了在该维度中,回归模型拟合地相对较好。但是从MSE的测评结果来看,极性维度上的预测值与真实值之间的误差较大,我们认为这是由于个别预测值出现了较大的偏差,导致整体的误差增大。可控性维度在r值的评估中表现较差,尤其是写者方面,平均值不超过0.1,但本文方法在该维度上的回归性能依旧优越于其他方法。强度维度在r值上的评估结果均值在0.2左右,部分方法也取得了较小的误差。此外,任何一种系统在r值的评估上都没有取得很高的分数,基本处于0.5以下,可见该回归任务在本文使用的数据集上是具有一定难度的。
LSTM、CNN和GRU系统无论是在读者数据集还是在写者数据集上都呈现出误差大、相关性小的特点。这些模型未能有效学习到文本中的情感信息,可见普通的回归模型在处理情感分析问题时没有明显优势。XLNet系统是一种可泛化的自回归模型,但在情感回归的任务上的表现却不够优越,比如说在读者领域的极性方面,MSE值和r值都表明预测的结果与真实值之间相差较大。
MTL是一种专门为情绪分析任务设计的模型,由LSTM、CNN和GRU三个子模型和一个手动特征向量集合而成。该系统整体上的预测水平要高于这三个子模型,但在强度和极性这两个维度上表现不够好。相比于MTL系统简单地将四个模块拼凑成一个模型,本文方法考虑到了维度与标签信息之间的关联性,让标签资源来辅助情绪回归,因此本文方法在三个维度上都有较好的表现。例如,写者领域的极性维度中,MTL的MSE值高达0.557 6,为所有方法中最高,r值得分为0.176 5,而本文方法因利用了维度-标签信息,区分了本文的类别,有助于模型判别正负极性。因此在极性维度中,本文方法在MSE上取得了0.254 1,在r值上得分为0.584 6,均为所有方法中最优。尽管读者的可控性维度中,MTL的均方误差要略低于本文方法,但是我们猜想这是由于MTL添加了特殊的手动特征向量,使得结果误差减小。本文是基于维度-标签信息提出了更加适合于情绪回归任务的模型,在强度和可控性维度上具有相关性高、误差小的特点,从实验结果的整体上来看,本文方法确实能够更好地预测多维情绪分值。
BERT系统在极性维度上取得了较高的性能。在该维度的r指标上,BERT获得了0.5以上的分数,MSE仅为0.25左右,接近本文的分值。在强度维度中,虽然BERT介绍没有取得最高的分值,但是依旧能保持较低的误差。相比其他基准系统,BERT模型能更好地预测三个维度的分值,因此我们选用BERT来提取输入文本的特征。但是由于BERT没有考虑到情绪回归任务的特点,所以在部分维度中没有取得更优秀的性能。而本文方法将标签信息提取出来,帮助模型完成情绪回归任务,因此不仅可以在r值方面取得较高的分值,也可以在MSE中取得较低的误差,如在读者领域中,在强度这一维度上,BERT的MSE值为0.183 8,r值为0.204 9,而本文方法在这两个指标上获得的值分别为0.138 4和0.278 5,回归效果更好。
除此以外,我们还进行了分类方法对回归方法的助益效果实验。如表6所示,在训练开始前,我们设置了不同的随机种子,得到了不同的分类结果,按分类准确率由低到高的顺序,本文方法的回归性能(r值)也随之升高,由此可见分类方法的准确率对回归性能有一定影响。
从整体上看,本文方法在情绪回归领域有着更好的预测能力,虽然受到数据集的限制,在部分维度上的分值依旧有待提高,但是相比现有的普通神经网络模型或者专为情绪回归所设计的模型,本文提出的方法更能提取文本中的情绪特征,从而以较高的预测能力完成回归任务。

表6 分类方法对回归性能的影响
本文在情绪回归的任务上提出了一种基于维度-标签信息的多元情绪回归方法。该模型主要特点在于: ①充分考虑到情绪回归任务的难度,利用情绪分类的预测概率辅助情绪回归任务;
②可以同时预测三个维度的分值和各类别概率,是一种多任务、多元回归模型,在提高准确率的同时减少训练模型所需的时间;
③将不同情绪标签的文本空间表示距离扩大,尽可能突出两种不同情绪类别的特点,从整体上提升情绪回归的准确率。实验结果验证了本文方法可以有效应用于情绪回归任务,并取得较为良好的性能表现。但是,本文方法还有待进一步提高,例如,情绪分类任务中产生的错误分类结果会影响到情绪回归任务,导致最终维度分值的预测准确性下降。因此,在未来工作中,我们将致力于提高情绪分类的性能,从而减少分类的错误结果对情绪回归任务的影响,比如在采用多任务学习方式时给情绪分类任务和情绪回归任务使用与自身任务更适应的损失函数。








