自注意力机制和BiGRU相结合的文本分类研究
时间:2023-06-11 12:35:13 来源:雅意学习网 本文已影响 人 
石 磊,王明宇,宋哲理,陶永才,卫 琳,高宇飞,范雨欣
1(郑州大学 信息工程学院,郑州 450001)
2(郑州大学 软件学院,郑州 450002)
3(郑州财税金融职业学院 信息技术系,郑州 454048)
文本分类技术是对文本集按照一定的分类体系或标准进行自动分类标注的技术[1].20世纪90年代,在计算机研究领域各种基于数学表达的机器学习方法不断涌现,一些经典的机器学习方法,如支持向量机、朴素贝叶斯、决策树、最近邻方法等被广泛应用于文本分类研究.PANG B等人[2]使用词袋模型,结合贝叶斯、最大熵、支持向量机等机器学习方法对IMDB影评数据集进行情感分类,取得了较好的效果.基于机器学习方法的文本分类模型虽然拥有较为简单的函数表达,但其通常需要繁杂的人工特征工程,生成的文本特征表示均为高维度的稀疏向量,忽略了词义、词序等信息,其特征表达能力也相对较弱,在分类任务中无法很好地保留上下文信息.Bengio等人[3]提出神经网络语言模型(neural network language model,NNLM),将深度学习方法引入自然语言处理研究领域.神经网络语言模型将单词映射到低维稠密空间,并采用词向量度量单词之间的语义相关性.此后Golve[4]和Word2vec[5]等词向量模型的提出,实现了词向量的高效运算,使得深度学习方法在自然语言处理研究领域的应用更为成熟.基于深度神经网络的文本分类方法使用数学向量对词汇进行语义表示,然后通过组合的方式获得句子和文档级别的语义表示.
CNN和RNN是当前文本分类研究中广泛应用的两种神经网络模型.CNN可以并行化提取文本局部特征,但无法考虑文本中的上下文语义信息.RNN中的隐藏状态使得网络具备了一定的记忆性,能够捕捉文本间的上下文语义信息与依赖关系,但其在文本分类任务中要解析全部文本内容后方能得出结论,无法实现模型的并行化运算,并且在模型训练过程中,有可能出现梯度弥散或梯度爆炸问题.
借鉴上述两种模型各自优势,本文提出一种SBUTC模型,使用自注意力机制将自然语言文本转换为含有丰富语义信息的向量表示,通过动态分配字嵌入的权重系数帮助模型更好地注意到对分类贡献较大的文本部分,同时结合CNN和BiGRU两种模型的优势,既使用含有不同尺寸卷积核的多通道CNN提取不同粒度的文本局部特征信息,又通过包含跳层连接结构的堆叠BiGRU网络获取文本间上下文语义信息和长距离依赖关系,从而提高模型的文本特征提取能力.实验结果与分析表明,SBUTC模型具有较好的分类性能.
CNN在文本分类任务中用于提取文本局部特征信息.Kim等人[6]提出TextCNN模型,使用不同尺寸的一维卷积核提取文本的局部特征.Kalchbrenner等人[7]提出一种动态卷积神经网络模型DCNN,使用卷积与k-最大池化相结合的方式对文本的句法结构进行动态建模,捕捉更多文本特征信息.Zhang等人[8]提出Character-level CNN模型,通过预先设计的字母表将文本单词转换为字符形式,使用one-hot编码对字符进行量化,将其作为模型输入,然后经过多层卷积和池化等操作获得文本分类结果.针对基于TF-IDF的SVM算法计算时间过长的问题,Wu等人[9]提出一种CNN与SVM相结合的模型CSVM,使用CNN提取文本特征表示,通过SVM分类器得到分类结果输出.为了解决浅层CNN在文本分类任务中无法很好地捕捉文本中的长距离依赖的问题,Johnson 等人[10]提出一种DPCNN模型,通过增加网络深度,堆叠多个卷积层,获得更高层次的文本局部特征,从而捕捉文本间的长距离依赖关系,提升分类效果.这些方法虽然提升了局部特征的提取能力,但是缺乏对上下文语义信息的挖掘,存在一定的局限性.
相较于CNN,RNN中的隐藏状态使神经网络具备一定的短期记忆性,这使其能够在一定程度上捕捉文本上下文语义信息和依赖关系.Xu等人[11]提出一种多通道RNN模型,用于动态捕获文本语义结构信息.在文本分类任务中,RNN的变体LSTM和GRU被广泛使用.Cho等人[12]提出的门控循环单元(Gated Recurrent Unit,GRU),简化了LSTM的结构,将输入门与遗忘门合并为单一的更新门,这个设计可以应对循环神经网络中的梯度弥散问题,更好地捕捉文本序列中时间步距离较长的依赖关系.为能够同时获取文本间的正、反向依赖关系,双向RNN被广泛使用.Lai等人[13]提出一种RCNN模型,使用双向RNN获取文本中单词的上下文信息,并通过最大池化方式进行文本分类.Adhikari等人[14]提出一种Bi-LSTM模型,通过设置正则化等操作实现了较好的文本分类结果.这些基于RNN的方法着重提取文本上下文语义信息和依赖关系,但是忽略了文本中一些重要的局部特征信息,对分类效果有一定影响.
一些研究通过将CNN与RNN结合的方式,发挥各自优势,提升分类效果.Xiao等人[15]提出char-CRNN模型,通过多层CNN将字符序列转换为文本特征并将其输入双向LSTM中进行处理.针对池化方法容易丢失部分局部特征的问题,Hassan等人[16]提出一种CRNN模型,丢弃传统CNN中使用的池化层并用LSTM进行替代,以捕捉文本间的长距离依赖关系.Zhou等人[17]提出C-LSTM模型,把经过卷积输出的特征集合重新排列,得到同一词窗经过不同卷积操作后的组合特征向量,并将这些新向量按照与原始文本相对应的顺序输入LSTM中,得到分类输出结果.
深度学习方法在处理文本数据时,通常采用取平均或者求和等方式生成文本的语义表示.实际上,文本不同部分对文本信息的影响是不同的.通过引入注意力机制,模型会对文本中的不同部分给予不同的关注度,实现更加合理的自然语言建模.注意力机制其本质为一个查询(Query)到一系列键值对(Key-Value)的映射,其将Query和每个Key进行相似度计算得到权重,然后使用Softmax函数进行归一化,最后将权重和相应的键值Value进行加权求和得到最终的Attention值[18].在文本分类任务中,注意力机制通过学习一系列的注意力分配系数,即权重系数,对RNN的每个单元输出向量赋予权重,将其加权和作为文本特征,从而帮助模型关注文本中对分类有重要影响的部分.Yang等人[19]提出HAN模型,通过在词汇与句子两个层次引入注意力机制赋予文档中重要性不同的词汇和句子不同强弱的关注度,在提升文本分类性能的同时实现对文本重要信息的筛选.Ma等人[20]将注意力机制与LSTM相结合,进行基于目标的文本情感分类工作.Ma等人[21]提出一种CGGA模型,使用多头注意力机制对文本特征进行权重赋值和更新,提升相应文本类别上的输出值,优化模型分类效果.
Vaswani等人[22]借鉴注意力机制的思想原理,提出自注意力机制.自注意力机制减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性.自注意力机制在文本中的应用,主要是通过计算词汇间的相互影响和依赖程度,使用注意力权重对已用数学表示的词嵌入进行加权线性平均,从而使每个词嵌入都含有所在句子中所有词的相关信息.这种方法更容易处理文本间的长距离依赖问题,文本中远距离依赖特征之间的距离被极大缩短,能被更好地利用.
本文结合CNN、GRU和自注意力机制,提出一种SBUTC模型,利用自注意力机制生成文本的数学向量表示,通过具有4种不同尺寸卷积核的CNN提取不同粒度的文本局部特征,并且使用含有跳层连接结构的BiGRU网络提取文本间的上下文语义信息和长距离依赖关系.SBUTC模型能够同时考虑文本的局部特征和上下文语义信息,减少一些关键特征的丢失.而自注意力机制赋予生成的字嵌入丰富的文本内部相关信息,提高分类准确率.
3.1 基于自注意力机制的文本表示
基于神经网络的词向量训练方法,如Word2vec和Glove等,均使用对文本静态编码的方法,无法解决文本中存在的一词多义问题.预训练语言模型则有效解决了这一问题,其核心思想是预先通过大规模语料训练出一个完整的语言模型,对于待处理文本通过综合分析字词位置、上下文语义等信息输出词嵌入,实现对词汇的动态编码.
本文通过对预训练语言模型ERNIE[23]进行微调的方式生成字嵌入表示,其间使用自注意力机制计算每一个字的self-attention值,该值决定了输入的文本中某一位置上的字与该文本内部其他部分的相互关注程度.self-attention计算过程如式(1)~式(3)所示:
(1)
(2)
(3)
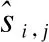
在中文文本分类任务中,一般需要对文本进行分词和去停用词等基于词粒度的处理.本文中的中文文本分类实验则采用基于字粒度的处理方式,将每一个文本实例看作是由字符构成的序列,并通过前述计算步骤将其转换成字嵌入序列.根据ZipF定律,大部分中文词汇出现次数很少,若使用基于词粒度的处理方式,会导致模型对应的词汇索引表规模过大,影响模型的训练效率和性能,并且在进行微调的时候,Out-of-Vocabulary问题会比较严重,而基于字粒度的处理方式能很好地避免这些问题,不再需要分词和去停用词等繁琐步骤.而且,在中文中单个汉字也有其特定意义,包含丰富的语义信息.此外,基于字嵌入的文本表示能够在一定程度上解决短文本特征词过少的问题,避免对文本中出现的不规则特征词的错误划分.
3.2 门控循环单元
GRU引入了门的概念,对原始RNN中隐藏状态的计算方法进行了修改,其单元结构如图1所示,包括重置门、更新门、候选隐藏状态和隐藏状态等部分.

图1 GRU结构
相关参数的计算和更新过程如式(4)~式(7)所示:
Rt=σ(ItWir+Ht-1Whr+br)
(4)
Zt=σ(ItWiz+Ht-1Whz+bz)
(5)
(6)
(7)
其中,假设隐藏单元个数为h,时间步t的输入为It∈1×d(1×d表示输入向量维度),上一时间步t-1的隐藏状态为Ht-1∈1×h,Wir,Wiz,Wih∈d×h和Whr,Whz,Whh∈h×h表示权重参数矩阵,br,bz,bh∈1×h是偏差参数,σ表示sigmoid激活函数,⊙表示做按元素乘法,1×h分别表示重置门、更新门、候选隐藏状态和隐藏状态的输出.重置门控制上一时间步的隐藏状态如何流入当前时间步的候选隐藏状态,有助于捕捉文本序列中的短期依赖关系.更新门控制隐藏状态应该如何被包含有当前时间步信息的候选隐藏状态所更新,有助于捕捉文本序列中的短期依赖关系.
GRU中的隐藏状态信息按照时间步顺序从前至后单向传递,只关注了文本中上文对下文的影响,无法体现出下文对上文乃至整体状态的影响,为了充分利用文本中的上下文关系,本文使用GRU的变体BiGRU,BiGRU每个时间步隐藏状态的输出由当前时间步前向隐藏状态和后向隐藏状态拼接而成,因此其受到前后两个方向信息传递的共同影响,包含的信息更丰富.BiGRU的模型结构如图2所示.
图2 BiGRU结构
3.3 模型整体结构
借鉴上述模型优点,提出一种SBUTC模型,模型结构如图3所示.

图3 SBUTC模型整体结构
1)使用自注意力机制生成新的字嵌入作为文本表示;
2)使用CNN提取文本局部特征;
3)利用BiGRU获取文本上下文语义信息和长距离依赖关系;
4)对CNN和BiGRU的输出进行融合;
5)使用全连接层,结合Softmax函数获得文本分类结果.
SBUTC模型由多个通道组成,其主体部分是4个CNN模型通道和1个BiGRU模型通道,将通过自注意力机制生成的字嵌入作为每个通道的输入,每个字嵌入的维度是768维.
4个CNN模型通道分别使用4种不同尺寸的卷积核,其大小分别为2×768、3×768、4×768和5×768,每种尺寸的卷积核数目均为300个,卷积步长(stride)设置为1,不进行补零操作.如图4所示,经过卷积操作之后得到文本的局部特征被送入池化层,池化层使用时序最大池化策略对这些特征进行筛选和过滤.经过4个CNN通道生成的特征向量会被拼接在一起作为全连接层输入的一部分,这些拼接在一起的向量会为文本分类提供丰富的局部特征信息.

图4 卷积过程
BiGRU模型通道由2个堆叠的BiGRU构成,隐藏层的维度均设置为300维.将文本序列从前后两个方向输入第1个BiGRU中,对其隐藏层中每一个时间步前后两个方向的隐藏状态输出进行拼接操作,作为第2个BiGRU每个时间步的输入.第2BiGRU也将其隐藏层中每一个时间步前后两个方向的隐藏状态进行拼接并输出.堆叠两个BiGRU,一方面增加网络的深度,有助于提升训练效率和模型性能,另一方面有助于提取更深层次的文本上下文语义信息和依赖关系.此外使用跳层连接结构,将堆叠的BiGRU最后的输出与输入文本序列按照时间步顺序一一对应并进行拼接,这样做避免了训练过程中梯度弥散或爆炸现象的出现,同时使向量中包含的语义信息更为丰富,在一定程度上避免重要信息的丢失.拼接得到的向量需进行线性变换运算,过程如式(8)所示:
yi=tanh(Wxi+b)
(8)
其中xi表示时间步i上经过拼接后的向量表示,yi是线性变换输出,其可以看作是一个潜在的语义向量,所有时间步上的y会被送入池化层,通过最大池化操作,最终获得文本全局特征的定长表示.
CNN和BiGRU的输出通过拼接操作进行融合,进而作为全连接层的输入.为更快计算,全连接层使用ReLU作为激活函数,并且加入dropout机制,在训练过程中,对于神经网络单元按照一定的概率将其暂时从网络中丢弃,使其不工作,这样做的目的是为了防止训练出的模型过拟合,提高模型的泛化能力.最后通过Softmax分类器获得分类结果,即在各分类标签上的概率分布,Softmax分类器将x分类为类别j的概率如式(9)所示:
(9)
其中,θ表示训练过程中的所有参数,k表示类别数.
4.1 实验环境
实验基于Facebook开源深度学习通用框架PyTorch(version-1.11),通过PyCharm开发平台使用Python3语言编程实现.实验运行环境如下:操作系统为Windows10,CPU是Intel i7-10875H,GPU是NVIDIA GeForce RTX 2060,显存规格为GDDR6 6GB.
4.2 实验数据集和评价指标
为验证SBUTC模型在中文文本分类上的有效性,相关实验在如下2个数据集上进行:
1)ChnSentiCorp数据集.该数据集是一个中文句子级情感分类数据集,包含酒店、笔记本电脑和书籍的网购评论,被划分为正面评价和负面评价两个类别,每个类别数据6000条,共有12000个数据实例,其中训练集占比80%,共9600个实例;
开发集占比10%,共1200个实例;
测试集占比10%,共1200个实例.
2)THUCNews_Title数据集.本文从THUCNews数据集中抽取财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐共10个类别的20万条新闻标题构成THUCNews_Title数据集,每个类别数据为10000条,其中训练集180000条,开发集10000条,测试集10000条.
ChnSentiCorp 数据集是二分类长文本数据集,而THUCNews_Title 数据集是多分类短文本数据集,两者都具有一定代表性.选择这两个数据集进行实验,可以对SBUTC模型的性能进行不同维度的评估.实验使用文本分类任务常用的性能评价指标:准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及F1值(F1-score)对提出的SBUTC模型进行评估.
4.3 实验预处理与超参数设置
对于ChnSentiCorp数据集,每个实例的文本最大长度值被设置为128,文本长度小于该值时进行补零操作,大于该值时进行截断操作.对于THUCNews_Title数据集,每个实例的文本最大长度值被设置为32,同样进行补零或截断操作.实验在训练过程中采用Adam优化器来优化模型参数,其对不同的参数使用相同的学习率,并在训练过程中对参数进行独立的自适应性调整,加快模型收敛速度.与此同时,采用warmup策略对学习率进行调整,该策略一方面有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳,另一方面有助于保持模型深层的稳定性.为了防止过拟合现象,使用weight_dacay和dropout机制.实验部分超参数设置如表1所示.

表1 模型超参数设置
在确定BiGRU和CNN相关参数时,本文做了以下两个实验:
实验1.BiGRU隐藏状态维度值对文本分类的影响.
在实验1中,暂时不使用CNN通道,将上游生成的字嵌入送入BiGRU通道中,对于BiGRU的隐藏状态,将其维度从100维开始调节,分别选取100、150、200、250、300、350、400这7个数值进行实验,以选取最优的隐藏状态维度数值.图 5(a)和图5(b)给出了在两个数据集上使用维度数值不同的隐藏状态得到的分类准确率的对比情况,图5(c)和图5(d)则展示了在不同维度下模型在训练集上训练1个epoch所需的平均时间.
对图5(a)和图5(b)进行分析,可以看出随着隐藏层维度的增加,分类效果有明显的提升,然而当维度达到300维后,继续提升维度值,在ChnSentiCorp数据集上F1值仅提升0.13%和0.25%,在THUCNews_Title数据集上F1值仅提升0.12%和0.23%,分类效果较300维并没有明显的提升,从图5(c)和图5(d)可以看出,当维度值大于300时,模型的训练时间大幅度增加,而模型性能却无显著变化,从计算量、模型效率和分类效果相结合的角度考虑,在后续实验中将BiGRU隐藏层的维度值统一设置为300.

图5 隐藏状态维度值对文本分类的影响
实验2.多通道CNN卷积核尺寸设置对文本分类结果的影响
SBUTC模型中CNN部分使用不同尺寸的卷积核提取不同粒度的文本局部特征信息,为验证卷积核尺寸的选取和卷积核数目的设置对文本分类的影响,将BiGRU通道相关参数按实验1中获得最优结果值设置,按表2所示对不同尺寸卷积核进行组合,每种尺寸卷积核的数目均设置为300,做对比实验.在两个数据集上的实验结果如图6所示.

表2 卷积核尺寸组合设置

图6 不同卷积核尺寸组合的实验结果
如图6所示,对于ChnSentiCorp和THUCNews_Title这两个数据集,A组、B组和D组的分类效果较好,分类准确率分别为95.67%、95.90%、96.17%和94.45%、94.30%、94.63%.对于ChnSentiCorp数据集,B组较A组分类准确率更高,而在THUCNews_Title数据集上,A组较B组分类准确率更高.当组合内包含大小为6的大尺寸卷积核时,无论在ChnSentiCorp长文本数据集上还是在THUCNews_Title短文本数据集上,分类效果均不理想.因此将多通道CNN的卷积核尺寸组合设置为(2,3,4,5).
4.4 模型实验结果分析
通过设置上述超参数搭建模型训练环境,使用训练集和开发集来拟合模型,最后通过测试集对模型的分类性能进行评估,在两个数据集上得到的测试结果分别如图7和图8所示,图中横坐标表示测试集数据所属的不同类别,纵坐标则表示模型对于测试集中不同类别数据的分类性能指标大小.

图7 ChnSentiCorp数据集上的实验结果
由图7和图8可知,模型在两个测试集上均取得了不错的分类效果.在ChnSentiCorp测试集上各类别的精确率、召回率和F1值均不低于0.95.对于THUCNews_Title测试集,各类别的精确率、召回率和F1值均超过了0.90,而其中科技、时政这两个类别文本相对更加复杂抽象,股票类别新闻标题与其他类别新闻标题在内容上较为相似,更容易产生分类错误,因此这3类别的评估指标相对其他几个类别较低.

图8 THUCNews_Title数据集上的实验结果
4.5 实验对比与分析
本文采用准确率和F1值作为评估指标,将SBUTC模型与以下模型或方法在两个不同数据集上进行实验对比.
1)SVM(Support Vector Machine).作为传统机器学习的代表,SVM在文本分类任务中常表现出较好的性能.首先通过Word2Vec方法获得输入文本的向量化表示,然后将词向量相加并取平均,得到一个和词向量维度相同的指示文章信息的向量,并将其作为SVM的输入,进行分类.
2)Naive Bayes.使用词袋模型将输入文本转换成数值型的特征向量,采用TF×IDF算法进行权重赋值和文本特征提取,将提取到的文本特征送入Naive Bayes分类器进行分类.
3)fastText[24].fastText是Facebook开源的一种快速文本分类模型,其基本思想是将文本的n-gram向量进行叠加平均获得文本向量表示,然后通过层次Softmax获得分类结果.
4)CNN.该模型是一个单通道CNN模型,使用窗口大小为3的单一尺寸卷积核提取文本局部特征信息.
5)Multi-Channel CNN[6].该模型即Kim提出的TextCNN模型,是一个多通道CNN模型,在卷积层使用窗口大小分别为2、3、4的卷积核提取不同粒度的文本局部特征信息,然后将经过最大池化操作后得到的特征进行拼接,送入全连接层并使用Softmax分类器获得分类结果.
6)BiGRU.将BiGRU最后一个时间步的前向隐藏状态和后向隐藏状态进行拼接,送入全连接层并使用Softmax分类器获得分类结果.
7)C-LSTM[15].该模型把经过单通道卷积输出的特征集合重新排列拼接,得到同一词窗经过不同卷积操作后得到的组合特征向量,并将这些新向量按照与原始文本相对应的顺序输入LSTM中,最后经全连接层和Softmax层输出分类结果.
8)Convolution-GRU[25].该模型使用1D Max Pooling对经过单通道卷积输出的特征集合进行特征筛选和降维,池化后的特征被送入GRU中,GRU每个时间步的隐藏状态输出经过Global Max Pooling、全连接层以及Softmax层最终得到分类结果.
9)Multi-Channel CNN-LSTM[26].该模型是一个由多通道CNN和LSTM组合而成的模型,首先使用具有不同尺寸卷积核的多通道CNN提取不同粒度的文本局部特征,然后把经过最大池化操作得到的特征送入LSTM层,再经过全连接层以及Softmax层得到分类结果.
10)Multi-Channel CNN&BiGRU.该模型一方面使用具有不同尺寸卷积核的多通道CNN提取不同粒度的文本局部特征并通过池化层进行特征筛选,另一方面通过BiGRU提取文本的上下文语义信息和依赖关系,并将多通道CNN与BiGRU提取的特征进行拼接,送入全连接层及Softmax分类器,得到最终的分类结果.
11)SelfAtt-MCCNN&BiGRU.在生成字嵌入时引入self-attention计算,然后使用与10)相同的方法进行文本分类.
12)SBUTC.该模型即本文提出的基于自注意力机制的多通道CNN与BiGRU混合模型.
从表3和表4可以看出,本文提出的SBUTC模型在两个数据集上均取得了较其他对比模型更高的分类准确率和F1值,对ChnSentiCorp测试集的分类准确率和F1值分别为96.17%和94.28%,对THUCNews_Title测试集的分类准确率和F1值分别为94.63%和93.33%.
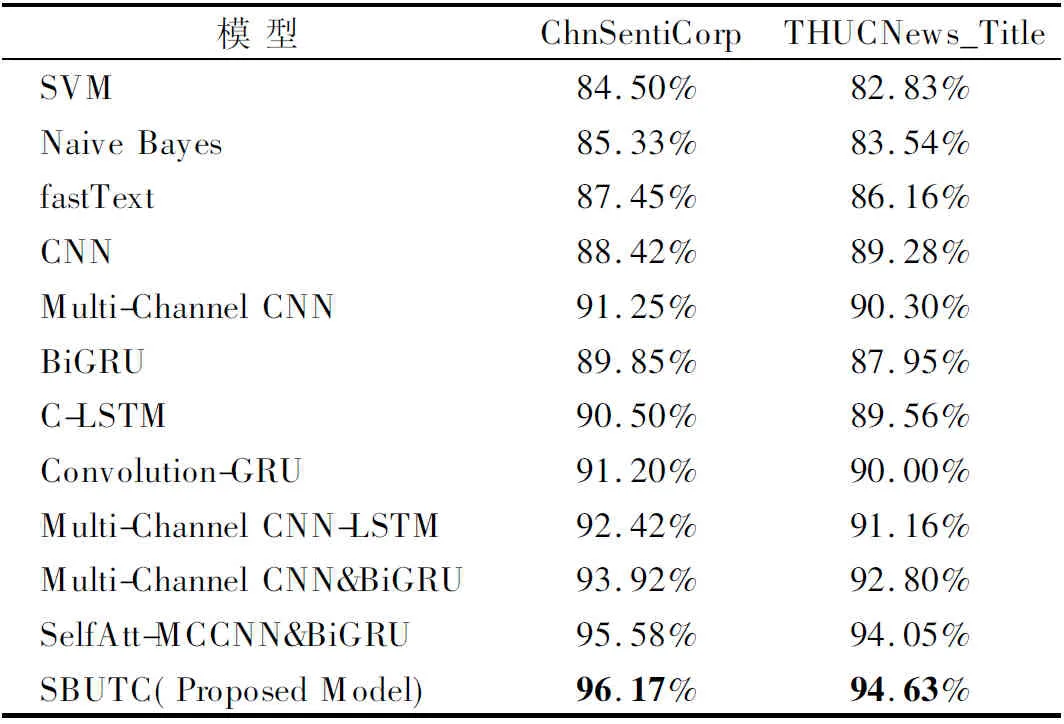
表3 本文模型和其他模型在2个中文数据集上的分类准确率对比

表4 本文模型和其他模型在2个中文数据集上的F1值对比
分析对比实验结果,可以发现在准确率和F1值这两个评估指标上,基于传统机器学习方法的SVM和Naive Bayes在两个数据集上的分类效果均不如基于神经网络模型的深度学习方法.SVM只是简单地将词向量相加并求平均后的结果作为文本的向量表示,因此分类效果并不突出.Naive Bayes从词频角度出发,使用TF×IDF算法进行简单的权重赋值和特征选择,分类性能稍优于SVM.然而SVM和Naive Bayes均不能像神经网络模型一样考虑文本内部的n-gram局部特征、上下文语义和依赖关系等对分类有重要影响的关键信息,分类准确率和F1值较神经网络模型方法明显较低.由此体现出基于神经网络的深度学习方法在文本分类任务中较传统机器学习方法更具优势.
fastText模型在两个数据集上的分类准确率分别为87.45%、86.16%,取得的F1值分别为85.16%、84.47%,均优于SVM和Naive Bayes.fastText模型是一个结构简单的神经网络模型,只有一层隐藏层和输出层,训练速度较快.在THUCNews_Title数据集上,CNN与BiGRU的分类准确率相近,没有较大差距,两者均能提取出有助于分类的文本特征信息,CNN较BiGRU分类准确率高1.33%,F1值高1.18%,这是因为THUCNews_Title数据集中的数据均为短文本,CNN凭借较多数目的卷积核这一优势能提取更多的文本局部特征信息,由于文本较短,文本内部的长距离依赖关系并不突出,BiGRU无法很好地发挥其作用.在ChnSentiCorp数据集上,BiGRU的分类准确率比CNN的准确率高1.43%,F1值高1.25%.ChnSentiCorp数据集大多为长文本,BiGRU可以从前后两个方向捕捉文本的上下文语义信息和长距离依赖关系,从而获得CNN无法提取的一些重要特征,分类效果更好.
通过比较Multi-Channel CNN与CNN、Multi-Channel CNN-LSTM与C-LSTM的实验结果可以看出,在模型中使用多通道CNN比使用单通道CNN能够取得更好的分类效果,多通道CNN使用不同尺寸的卷积核提取不同粒度的文本局部特征信息,能更好地捕捉有助于分类的关键局部特征,提升模型的分类性能.Convolution-GRU与C-LSTM相比,分类准确率和F1值更高,虽然两者都使用卷积层提取文本特征信息,但GRU与LSTM相比其内部单元结构更简单,参数更少,模型的迭代收敛速度更快.通过比较Multi-Channel CNN&BiGRU和Multi-Channel CNN、BiGRU的分类准确率以及F1值,可以发现融合CNN与RNN的多通道模型在分类性能上明显优于单独的Multi-Channel CNN或者BiGRU模型,Multi-Channel CNN&BiGRU结合了Multi-Channel CNN和BiGRU各自的优势,既可以提取不同粒度的文本局部特征信息,又能较好地捕捉文本间的上下文语义和依赖关系等信息,因此在文本分类中表现更出色.Multi-Channel CNN-LSTM与Multi-Channel CNN&BiGRU两者都是CNN与RNN相结合的模型,但一个是将CNN提取的特征作为LSTM的输入,而另一个是将CNN与BiGRU各自提取的特征信息进行拼接,Multi-Channel CNN-LSTM在两个数据集上的分类性能表现均次于Multi-Channel CNN&BiGRU,因为LSTM在隐藏状态信息传递过程中丢弃了一些CNN提取的重要特征,从而影响了分类结果.
对SelfAtt-MCCNN&BiGRU、SBUTC和Multi-Channel CNN&BiGRU的实验结果进行比较,可以看出在多通道模型中引入self-attention计算可以更好地提高分类准确率,self-attention机制计算单词间的相互影响和依赖程度,使用注意力权重对已用数学表达的中文字向量进行加权线性组合,使模型更加关注文本中对分类有较大影响的部分.本文提出的SBUTC模型,在引入self-attention计算和多通道CNN的同时,对BiGRU通道做进一步改进,通过堆叠两个BiGRU,增加网络的深度,帮助提升训练的效率和模型的性能,借鉴Resnet的思想,使用跳层连接结构,避免训练过程中梯度弥散现象的出现,同时使向量中包含的语义信息更为丰富,并在一定程度上减少重要特征信息在传递过程中的丢失,因此本文提出的SBUTC模型相较于其他几种对比模型或方法能够取得更好的分类效果.
基于自注意力机制的多通道CNN与BiGRU混合模型SBUTC,既使用含有不同尺寸卷积核的多通道CNN提取不同粒度的文本局部特征信息,又通过包含跳层连接结构的BiGRU捕获文本间上下文语义信息和长距离依赖关系,准确提取文本的全局特征.该模型利用自注意力机制生成含有丰富信息的字嵌入,通过动态分配字嵌入的权重系数帮助模型更好地注意到对分类贡献较大的文本部分.实验结果表明SBUTC模型与单一的CNN和BiGRU网络相比,能更充分地提取文本特征信息,获得了更好的结果,且自注意力机制能帮助模型提升分类性能.在接下来的研究中,将探索如何将自注意力机制与其他针对文本分类的深度网络结构相结合(例如图神经网络等),以期进一步提升深度学习在文本分类中的适应性.
猜你喜欢 集上语义向量 向量的分解新高考·高一数学(2022年3期)2022-04-28GCD封闭集上的幂矩阵行列式间的整除性四川大学学报(自然科学版)(2021年6期)2021-12-27聚焦“向量与三角”创新题中学生数理化(高中版.高考数学)(2021年1期)2021-03-19语言与语义开放教育研究(2020年2期)2020-03-31R语言在统计学教学中的运用唐山师范学院学报(2018年6期)2018-12-25批评话语分析中态度意向的邻近化语义构建中国修辞(2017年0期)2017-01-31“社会”一词的语义流动与新陈代谢中国社会历史评论(2016年2期)2016-06-27向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14“吃+NP”的语义生成机制研究长江学术(2016年4期)2016-03-11向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23






