基于深度条件依赖网络的裁判文书信息抽取
时间:2023-06-10 14:10:24 来源:雅意学习网 本文已影响 人 
翁 洋,向 迪 ,郭晓冬,洪文兴,李 鑫
(1.四川大学数学学院,四川成都610064;
2.厦门大学航空航天学院,福建厦门361102;
3.四川大学法学院,四川成都610207)
近年来,司法领域的数据量迅速增长.法官、律师和检察官等法律专业人员不仅要处理大量案件,还需要查阅大量档案以供参考或分析与案件有关的数据.这可能会导致司法工作效率低下,出错的风险增加.如何将人工智能技术应用在司法领域,提高司法人员在案件处理环节的效率逐渐成为法律人工智能研究的热点[1-3].人工智能在法律领域的落地,不仅需要了解法律规范,还需要对法律运行状态有深刻的认知.法律的实施、运行情况被集中地记录在裁判文书中,我国已有近亿份裁判文书上网公开,为法律人工智能应用提供了坚实的数据基础.因此,本文将重点放在如何帮助司法人员利用大规模裁判文书对案件进行解释和公正判断上.对于司法判决的可解释性和公正性,一种可行的方法是从裁判文书中抽取相关案件要素,案情事实中的重要事实表述是法律规范所涉要素在具体案件中的具体表现,可以使用这些事实描述来帮助司法判决;
另一种可行的方法是从裁判文书中挖掘争议焦点,我国法院已形成了通过围绕争议焦点展开审判提高审判效率的审判模式,利用争议焦点理清审判思路可以帮助司法公正.所以,面向大规模裁判文书的信息抽取技术的突破能提高法院运行效率,为法官的审判工作提供辅助;
为法律人工智能的新技术研究提供支撑;
对社会运行态势进行研判,为党政机关决策提供辅助.
信息抽取是从自然语言文本中抽取指定类型的实体、关系与事件等事实信息,并形成结构化数据输出的文本处理技术[4-6], 然而,由于法律领域的知识壁垒,基于裁判文书的信息抽取技术还处于主要利用基于人工制定规则匹配的阶段[7].目前在法学领域内存在两种裁判文书信息抽取方法:一是正则表达式匹配的方法,即通过人工制定匹配规则及策略进行相应的标签确定;
二是基于机器学习的文本分类方法,通过法学专家制定标签体系,并根据标签体系标注数据,利用标注数据训练文本分类模型.
在具体案件中,多个司法标签可能出现在同一语句中,以符合案件实际情况及通常的语言表达习惯.因此,将裁判文书信息抽取任务转换为多标签文本分类是自然语言处理技术应用在司法领域的合理应用.由于法律信息的独特结构、法言法语自成体系的表达和推理方法,传统的低召回的正则提取方式和实体识别提取方式便不再适用,需要根据领域专家针对所需裁判文书的信息标签体系进行分类.
早期的多标签文本分类算法将多标签问题转变为多个单标签的分类问题[8],这类方法会丢失标签之间的相关性.利用标签之间的依赖关系已是多标签学习的一个重要研究方向[9-14].概率图模型是一种描述变量之间关系的模型框架,其在多标签分类中也有诸多应用,例如贝叶斯网络[15-17]和条件随机场[18],然而这些图模型需要复杂的学习和推断过程.Guo等[19]提出条件依赖网络(conditional dependency network,CDN)来建模标签之间的依赖关系,直观地描述了标签之间的依赖性,并且不用进行复杂的网络学习和推断.在文本多标签分类任务中,传统的多标签学习算法一般利用词层级的稀疏特征作为文本的特征表达,例如词袋模型和n-gram[20].这些表达忽略了文本中深层次的语义信息,而传统多标签分类算法自身的特征提取能力不足,这导致传统的多标签算法难以充分利用文本信息.为了更有效地利用文本信息,许多深度学习网络模型[21-24]被应用于多标签文本分类任务中.然而,在这些网络结构中标签之间的依赖关系也没有得到很好的利用.为了更好地利用标签之间的依赖关系,Kurata等[25]提出当用卷积神经网络(CNN)处理多标签文本分类任务时,用标签之间的共现关系来初始化网络最后输出层的权重,以此利用标签之间的依赖关系.Chen等[26]建立卷积神经网络-循环神经网络(CNN-RNN)网络,CNN-RNN将CNN和RNN整合在一个网络中以利用文本的语义表达,并建模标签之间的关系.Baker等[27]利用基于CNN的共现行为来初始化最后的隐藏层以提升模型表现.Yang等[28]提出SGM,其利用基于长短时记忆(LSTM)的序列到序列的网络结构来逐次产生标签,同时网络中还利用了注意力机制.随着预训练模型(bidirectional encoder representations from transformers,BERT)[29]的广泛流行,X-BERT[30]的出现利用BERT来处理极大规模多标签文本分类问题.除此之外,很多用于多标签文本分类的深度学习模型具有特定的形式,不容易进行模型扩展,难以让各种强有力的网络模型在多标签文本分类任务中得到简便有效的利用,因此研究深层语义表示和要素标签建模相结合的深度学习框架显得尤为重要.
本文的主要目的是为了将司法信息从裁判文书中自动抽取出来,并根据领域专家设计的标签体系进行分类.因此根据司法判决可解释性和公正性的需要,进行以下两个裁判文书信息抽取任务,一是案件要素抽取,二是争议焦点抽取.具体地,给定司法文书中的相关段落,系统需针对文本信息进行判断,识别其中的关键标签信息.然而这些标签之间存在依赖关系,一个司法标签的出现可能导致另一个司法标签出现概率的增加.现有的大多数工作只关注于标签的提取任务,而忽略了标签之间的依赖关系.为了解决这个问题,提出了基于深度条件依赖网络的裁判文书信息抽取框架(framework for information extraction of judgment documents based on deep conditional dependency network,DCDN),即利用深度CPN去构建司法标签间的依赖性,以更准确的抽取裁判文书中的信息.
总的来说,本文的贡献为以下几点:
1) 将构建标签关系的条件依赖网络思想与深度学习网络模型结合在一起,更好地利用裁判文书文本信息和司法标签之间的依赖关系,并将它们置于同一网络下互相指导学习,以此来提升具有依赖关系的司法标签提取效果.
2) 在真实场景司法数据集CAIL2019(案件要素抽取)上的实验结果表明本文提出的框架用于案件要素抽取任务具有较好的扩展性和有效性,此外,本文的模型取得了几乎全方位的效果提升.
3) 在真实场景司法数据集LAIC2021(争议焦点识别)上的实验结果表明本文提出的框架用于争议焦点任务具有较好的有效性,本文的模型相比基线有一致且较大的改进.
1.1 裁判文书信息抽取任务描述
裁判文书信息抽取是从裁判文书中抽取指定类型的司法信息.裁判文书信息抽取的任务多样,包括并不仅限于裁判文书的段落标签、争议焦点、案情事实中的案情要素以及案情事实中的实体和关系.结合法学知识,主要考虑了两个信息抽取任务,一是案件要素抽取,二是争议焦点抽取.案件要素指案情事实描述中的关键行为词及与行为相关的要素.案件要素提取任务是对裁判文书案件事实描述段落打上相应的案件要素标签(图1左),属于多标签样本分类任务.此外,案件标签间往往存在依赖关系,即在同一个案件事件描述中一个案件要素标签的出现可能导致另一个案件要素标签出现概率的增大.例如,在离婚案件中,案件事实如果有“婚后有子女”的标签,那么它同时具有“支付抚养费”标签的概率就会很大.争议焦点是案件双方当事人争执的核心分歧点和法官裁判思路的内容,争议焦点提取任务是根据裁判文书中原被告的诉请及答辩内容,对其中诉辩双方在证据、事实和法律适用方面的的争议焦点进行识别和检测(图1右),属于多标签样本分类任务.同理于案件要素提取,争议焦点间往往也会存在依赖关系.

图1 裁判文书信息抽取的例子Fig.1Example of information extraction from judgment document
1.2 DCDN

图2 DCDN框架示意图Fig.2DCDN framework diagram
受到CDN[19]描述的标签之间的依赖关系启发,利用条件依赖网络的思想建模标签之间的依赖关系,以此构建基于深度条件依赖关系的裁判文书信息抽取框架.本文提出的DCDN,主要包含裁判文书特征提取网络与标签依赖关系网络两个部分,假设每一个司法标签与其他司法标签有关,关系程度的大小由权重决定.整体板块如图2所示.
随着BERT的出现,将BERT融入深度学习模型是得到高精确、高召回模型的常见措施,因此,本文中首先使用BERT作为基础模型以获取裁判文书输入序列的上下文表示.输入到BERT的序列通常为:
[CLS]
然后利用BERT获取每个字符的上下文表示H(x),用于特征抽取.对于输入序列(x1,x2,…,xN),有
H(x)=Bert(x1,x2,…,xN).
(1)
引入一个新的参数矩阵Wf∈RL×dim(H(x)),其中L表示需分类的司法标签数,那么司法标签预测信息向量可以通过下式得到:
F(x)=WfH(x).
(2)
正如图2所示,将不包括第i个标签的标签集y-i中司法标签的具体值(1或0)做线性组合之后加到标签信息预测向量F(x)的第i维上,以此获得一个在给定x和y-i中司法标签具体取值的情况下第i个司法标签的最终预测信息,即:
F(x)i+wi1y1+wi2y2+…+wii-1yi-1+
wii+1yi+1+…+wiLyL,
其中wij是权重参数,它在一定程度上暗示第i个司法标签和第j个司法标签的相关程度.让Wy∈RL×(L-1),Wy中的元素即为wij,然后便能得到司法标签的最终条件预测信息:
F(x)+Wy·Ys,
上式中·为Hadamard乘积,Ys∈RL×(L-1)表示司法标签具体取值的矩阵.Ys第i行的形式如下:
y1,y2,…,yi-1,yi+1,…,yL,
随后利用sigmoid函数σ便能得到每个司法标签的条件预测概率:
(3)
2.1 损失函数及训练方式
DCDN中网络结构的最终输出为在给定裁判文本序列x和一定司法标签具体值下对某一个标签的条件概率预测,输出第i个司法标签的条件概率预测值如式(3)所示.这是一个在一定条件下的二值概率预测问题,因此用binary-crossentropy损失函数:
(1-yi)log(1-p(yi=1|F(x),y-i))],
(4)
其中D是样本数量,训练过程中可为每个批次中的样本数量.训练过程中,在预训练模型特征提取网络前端输入了裁判文本序列x后,对于每一个司法标签的预测还需要输入此样本x训练数据对应的其他司法标签值,这些都是类似于已有观测的特征输入.整个训练过程本质上与普通神经网络的训练过程一致.
本文中用反向传播算法来说明DCDN在训练过程中参数的梯度计算形式.仅仅给出DCDN中F(x)之后的参数梯度形式,当误差由DCDN后端传到F(x)之前的网络结构时,参数梯度的计算方式与通常的神经网络反向传播梯度计算方式一致.
首先令
则
使DCDN最后未通过sigmoid函数的输出为:
Z=F(x)+Wy·Ys,
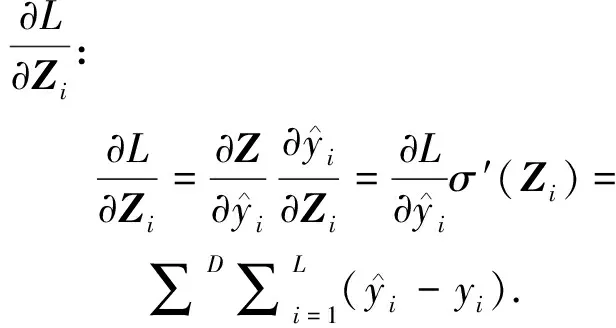

位于输出层前一层的误差δ′i可通过F(x)反向传播.设输出层前一层的输出Z′,则
出现以上求和式的原因为Z′在经过全连接层之后与F(x)中的每一项均有关.由δ′i便可将误差传播到网络前端,据此可根据具体网络结构计算每个参数的梯度.在计算网络参数的梯度之后,通过一些深度学习的优化方法就可进行训练过程中的参数更新.
2.2 预测推断
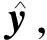



算法1gibbs sampling for inference
输入:Text sequence,x; Number of labels,L; Burn-in iteration number,nb; Instance collection iteration number,nc
输出:Predictor sequence of labels,y.
1: initializey=(y1,y2, …,yL),l=0;
2: choose a random orderingrover label spaceY.
3: forj=1 tonb+ncdo
4: fori=1 toLdo
5:q=p(yr(i))=1|F(x),y-r(i))
6: sampleu~uniform distribution of (0,1);
7: ifu≤qthenyr(i)=1
8: elseyr(i)=0
9: end if
10: ifj>nbthen
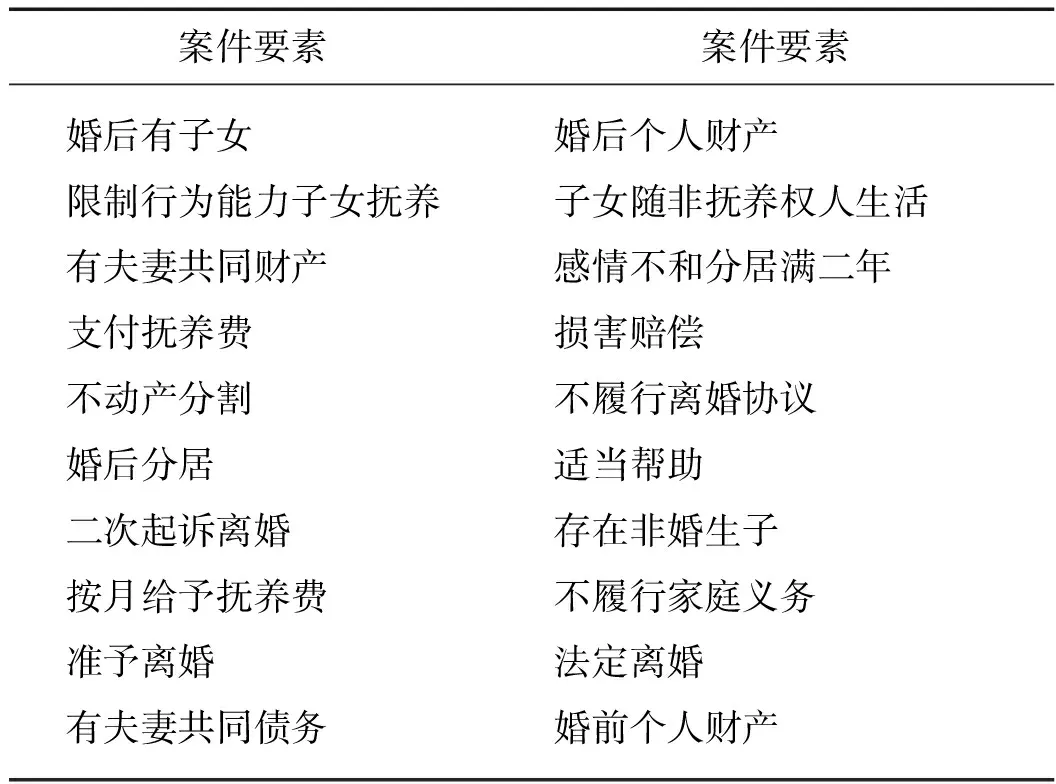
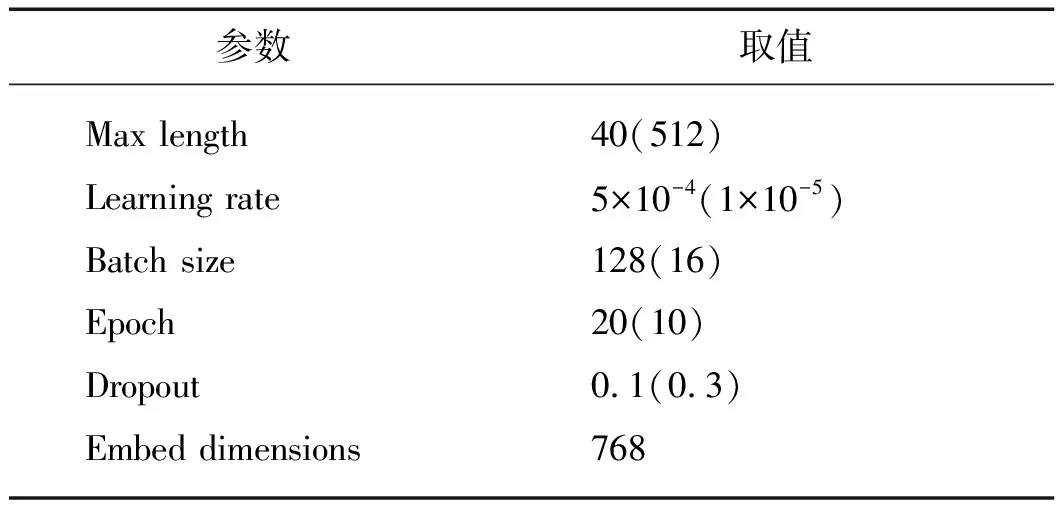
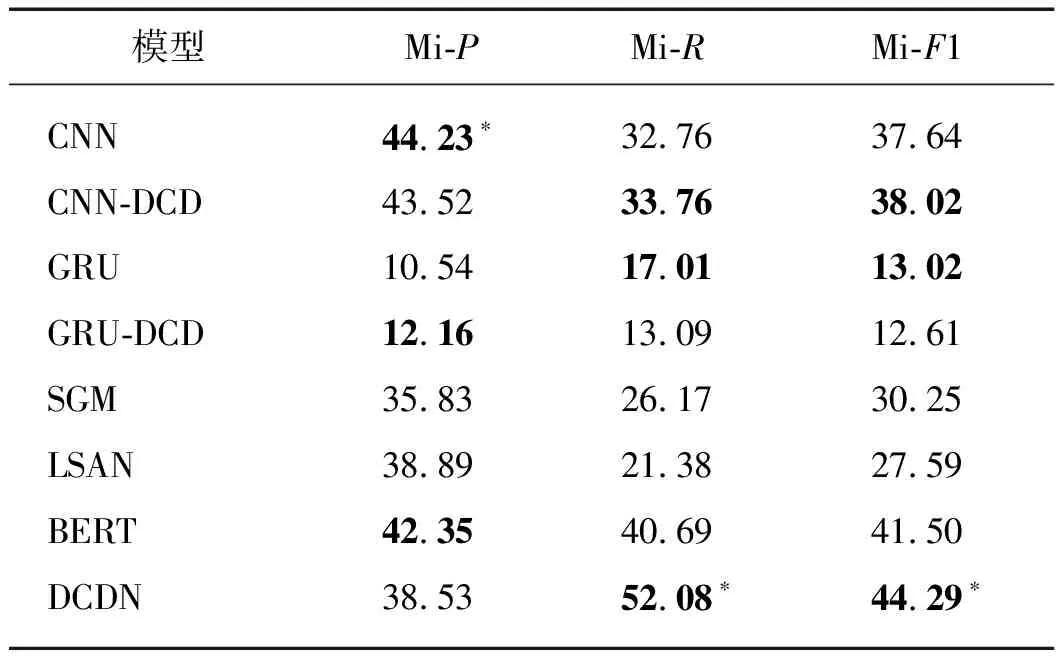
12: ifl 14: end if 15: end if 16: end for 17: end for 在CAIL2019(http:∥cail.cipsc.org.cn:2019/index.html 2019年中国法研杯司法人工智能挑战赛)(案件要素抽取)上进行裁判文书案件要素信息抽取实验.数据集中的全部数据来源于中国裁判文书网上的法律文书.每个训练数据的文本由法律文书的案情描述部分组成,其中每个句子都被同时分配了至少一个对应的类别标签.在这篇文章中,用离婚领域的小数据集来进行实验,并把数据集划分为训练集和验证集.其中,训练集包含10 484条句子层级的样本,而验证集包含1 201条句子层级的样本,并且整个数据集一共有20个标签(表1). 表1 预定义案件要素标签 在LAIC2021(http:∥data.court.gov.cn/pages/laic2021.html 第四届中国法研杯司法人工智能挑战赛)(争议焦点识别)上进行裁判文书争议焦点信息抽取实验.全部数据来源于浙江省高级人民法院提供并标注的法院裁判文书,包含大约14 000篇裁判文书以及人工额外标注的争议焦点(标签形式),其中所涉及到的裁判文书均为民事判决书,涉及的案由包括民间借贷、离婚、机动车交通事故责任、金融借款合同等.在本文中,按8∶1∶1的比例将数据集划分为训练集,验证集和测试集.这个数据集一共包括了148个争议焦点标签. 采用Micro精确率(Mi-P)、Micro召回率(Mi-R)和Micro-F1值(Mi-F1)作为评价指标. 利用下述基线模型与本文提出的框架进行对比. CNN:用CNN作特征提取表达,之后利用sigmoid函数得到每个标签的概率输出. RNN:用RNN作特征提取表达,其他与CNN相同. BERT:用BERT作特征提取表达,其他与CNN相同. SGM[28]:将多标签分类任务视为序列生成问题,构建基于LSTM的序列到序列的网络模型.不仅构建了标签间的依赖性,还获取了输入文本的关键信息. LSAN[32]:基于注意力机制来学习特定标签的文档表示,能够利用标签的语义信息来确定标签和文档之间的语义联系来建立特定标签的文档表示. RBT-MRC[33]: 引入标签信息和法律先验知识构造辅助问句,利用BERT机器阅读理解模型建立辅助问句和裁判文书之间的语义联系提取司法要素,该方法仅在案件要素提取任务中作为基线模型. 此外,为了证明CDN融入深度学习模型的思想具有良好的扩展性,还考虑将CDN融入CNN(CNN-DCD)和GRU(GRU-DCD)作为基线模型. 考虑到两个数据集的最大字长,数据量等各不相同,设置两个数据集上实验的参数如表2所示.在CAIL2019(案件要素抽取)数据集上,用Adam优化器[34]极小化损失函数,并设置优化器中的两个动量参数β1和β2分别为0.900和0.999.实验中初始的学习率为0.000 5,并且每3个训练轮次后学习率缩减为原来的五分之三.对于在DCDN中涉及的Gibbs采样过程,设置burn-in次数为10,并且进行另外的10轮迭代来收集采样样本.在DCDN的训练过程中每1 000 表2 超参数设置 次做一次验证集上的评估.所用的BERT中文预训练模型为Chinese_L-12_H-768A-12(https:∥github.com/google-research/bert#pre-trained-models). 在LAIC2021(争议焦点识别)数据集上,用Adam优化器[29]极小化损失函数,并设置优化器中的学习步长为0.000 01.对于在DCDN中涉及的Gibbs采样过程,与CAIL2019(案件要素抽取)中设置保持一致.在完成训练之后,选择在验证集上具有最低损失的模型作为最终的测试模型,并在测试集上测试结果.所用的BERT中文预训练模型为bert-base-chinese(https:∥huggingface.co/bert-base-chinese). 表3给出了DCDN和所有基线模型在CAIL2019(案件要素抽取)数据集上的实验结果.如表3所示,DCDN在所有评价标准上都得到了最好的结果.与CNN、GRU、SGM、LSAN和RBT-MRC模型相比,DCDN模型的改进较大.与现在最常用的BERT模型相比,Mi-P增加了约0.37个百分点,Mi-R增加了1.62 个百分点,Mi-F1分数增加了1个百分点.这表明DCDN在案件要素抽取任务上的有效性.此外,CNN-DCD和DCDN模型相较于无深度CDN的CNN、BERT模型在所有指标上都得到了提升,GRU-DCD模型相较于GRU模型在Mi-R和Mi-F1得到了提升.这表明了将条件依赖网络融入深度学习模型的思想具有良好的扩展性.综合来看,本文的模型优于基准模型,表现出融入要素标签之间的依赖关系可以使案件要素抽取的效果得到进一步提升. 表3 在CAIL2019(案件要素抽取)验证集上的实验结果 表4给出了DCDN和所有基线模型在LAIC2021(争议焦点识别)数据集上的实验结果.如表4所示,DCDN在Mi-R和上Mi-F1分数都得到了最好的结果.Mi-P相较于在此指标上表现最好的CNN模型降低了5.70个百分点,Mi-R相较于在此指标上表现最好的BERT模型提高了11.39个百分点,Mi-F1分数相较于在此指标上表现最好的BERT模型提高了2.79 个百分点.这表明DCDN在争议焦点识别任务上的有效性.此外,CNN-DCD和DCDN模型相较于对应的CNN、BERT模型在Mi-R和Mi-F1分数上得到了提升,GRU-DCD模型相较于GRU模型在Mi-P上得到了提升.这表明了将CDN融入深度学习模型的思想具有良好的扩展性. 表4 在LAIC2021(争议焦点识别)测试集上的实验结果 值得一提的是,相较于CAIL2019(案件要素抽取)是对短文本的司法句子进行标签标注,LAIC2021(争议焦点识别)是对长文本的司法段落进行标签标注并且标签数多达148个,这些易导致实验的最终效果不佳.此外,CNN擅长空间特征的学习和捕获.RNN擅长时序特征的捕获.传统的RNN模型在解决长序列之间的关联时,表现很差,原因是在进行反向传播的时候, 过长的序列导致梯度的计算异常, 发生梯度消失或爆炸.争议焦点识别更注重于局部信息抽取,而不是时序特征的捕获,例如出现“抚养”,倾向于根据这两个字给段落打上“抚养费”标签,而不是通过这个段落的语义.所以在长文本LAIC2021数据集上,GRU和基于LSTM的SGM、LSAN的效果不好,而基线模型CNN的Mi-P得到了最好的效果. 本文给出了一个直观的例子(表5)来证明DCDN在争议焦点任务上的重要性. 如表5所示,案例是关于医疗费用纠纷案.本案的争议焦点为:1) 医护费用认定,2) 保险公司责任承担情况.DCDN正确预测出医护费用认定焦点,错误预测出易混淆的基于医疗费用的损失赔偿数额认定焦点.而BERT模型无法预测出任何争议焦点.由该案例知,DCDN在显著提高模型召回率的同时,也会降低模型的精确率. 表5 争议焦点样例分析 本文提出了DCDN,该方法首先采用BERT预训练模型来提取裁判文书的深层次语义信息,再借助CDN的思想构建司法标签间的依赖关系.结合法学知识,主要考虑了两个信息抽取任务,一是案件要素抽取,二是争议焦点抽取,并在两个真实数据集上进行了实验.实验结果表明,本文的模型相比基线有一致且较大的改进,这表明该模型在裁判文书信息抽取上的有效性.此外,还实验了将CDN运用到其他深度学习模型上,证明了该模型的扩展性. 然而本文发现该框架的训练和预测是完全割裂开的,训练的目的是为了获得描述标签依赖关系的条件概率,预测时需要利用这些训练出的条件概率通过Gibbs采样进行推断,因此DCDN其实还不是一个完整统一的框架.在未来的工作中,希望通过考虑整体性的所有标签以指导整个网络的学习.
3.1 数据集和评价标准
3.2 实验设置
3.3 结论和讨论

3.4 样例分析








