基于多模体的虚假链路预测
时间:2022-12-05 20:45:03 来源:雅意学习网 本文已影响 人 
张 毅,许 爽
(大连民族大学 信息与通信工程学院,辽宁 大连 116605)
链路预测和虚假链路预测是复杂网络科学中的重要分支,通过已知的网络节点信息和结构信息来预测节点之间产生链接的概率或可能性[1]。预测包含两方面的内容:对尚未发现或未来可能产生的链接的预测对网络中存在的虚假连接的识别,即链路预测和虚假链路预测[2]。链路预测已经形成了较为完善的方法体系,然而识别网络中的虚假链接问题还没有得到太多的关注,一般认为虚假链接是网络中真实存在的边,并且其在网络中起着一些特殊的作用[3],如果预测方法不够准确,将一些重要的链接错误识别,网络的连通性将造到破坏,从而破坏系统的功能。[4]。
Guimerà和Sales-Pardo[5]提出了虚假链接、识别缺失和虚假链接的随机块模型。Peng Zhang和Dan Qiu[6]等将18种基于网络相似性的预测指标移植到虚假链路预测中进行预测实验。基于网络相似性的虚假链路预测方法和链路预测中存在同样的问题不适用与大规模的网络,且大多数相似性方法在虚假链路预测中对噪声更敏感。An Zeng 和 Giulio Cimini[7]提出了一种基于融合相似性指标和边缘中心性的预测方法,该方法能有效地识别和去除虚假链路,但存在着减小连通片的大小和扭曲网络其他静态和动态特性的重要缺点。Liming Pan[8]等根据预定义的结构哈密顿量估计网络的概率,将未观测链路的存在可能性得分通过向网络中添加聚焦链路的条件概率来量化,而观测链路的虚假概率通过删除链路的条件概率来量化,但基于似然分析的方法算法的框架更加复杂,时间复杂度很高,大大增加了预测时间成本。
为了提升虚假链路预测的预测结果准确性,拓展虚假链路预测的应用范围。本文从网络模体结构的角度出发,分析不同模体结构中的节点在真实网络中的相互作用模式,结合机器学习相关模型提出基于多模体的虚假链路预测方法,并在多个真实数据集上进行实验分析,改善了虚假链路预测的预测效果与性能。
1.1 问题描述
本文的实验数据为六个无权无向的真实网络,定义无权无向网络表示为G=(V,E),其中V是所有节点的集合,E是网络中连边的集合,V个节点两两相连接一共可生成U条连边,即U=|V|(|V|-1)/2,将U称为网络中所有可能相连边的全集。E为已存在的连边集合,则U-E为不存在的连边。
将连边集合E按9:1的比例划分作为训练集ET与测试集EP的正样本,在网络不存在连边集合U-E中,随机抽样与正样本数量相同的连边作为训练集ET与测试集EP的负样本,另外训练集负样本中存在pM(p∈(0,1))条不存在边被作为虚假连边添加到网络中。
1.2 评价指标
采取AUC(Area Under Curve)来评价预测的准确性,多角度评价算法预测效果。AUC指标采用曾安等在2012年定义的方法,随机的挑选一条虚假连边和一条真实连边,并比较它们的分数值。AUC值越高表示算法预测准确度越高在n次独立比较的过程中,如果S真实>S虚假,则n1+1,如果S真实=S虚假,则n2+1,AUC定义为
2.1 基于共同邻居相似性的预测方法
CN指标(common neighbors):CN指标又称为结构等价,该指标通过得知两个节点共同邻居的数量,来判断节点相似性。CN指标定义为:节点Vx的邻居集合为Γ(x),节点Vx的邻居集合为Γ(y)。则Vx和Vx的相似性定义为
AA指标(Adamic-Adar):在共同邻居的基础上考虑两端节点度的影响,则演变为AA指标[9]。AA指标的思想则是度小的共同邻居节点贡献大于度大的共同邻居节点。其定义为
其中kz表示x和y的共同邻居节点的度。
RA指标(resource allocation):从网络资源分配角度出发,周涛等人提出了基于信息分配的指标RA[10]。具体定义为

其中kz表示x和y的共同邻居节点的度,
2.2 基于模体特征的预测方法
模体[11]一般由少数几个节点连接而成。大多数网络中3个节点和4个节构成的模体较为常见。本文只涉及3节点和4节点的普遍情况。对于无向网络,3个节点构成的连通性模体结构有2种,4个节点构成的连通性模体结构有6种。
考虑到不同预测连边的选取,原有的模体数量将会增至12个如图1。对于某个模体特征来说,待预测连边上的某个模体数量就作为这个模体结构的模体特征。每个模体中待预测连边的相互作用关系在不同类型的网络中也会赋予不同的意义,在科学家合作网中代表两位科学家是否存在合作的可能[14],在蛋白质相互作用网络中表示两个蛋白质分子之间是否有连接,在社交网络中表示两个网友在不久的将来是否可能成为互关的好友。
在基于单模体的虚假链路预测实验中,12种模体结构每种都单独作为一个网络特征,在每个实验数据上单独进行12次虚假链路预测实验,对比分析不同数据集下基于单模体的虚假链路预测实验结果。在基于多模体的虚假链路预测实验中,结合机器学习模型融合提取12种模体特征进行实验。在进行融合模体与网络表征学习的虚假链路预测实验时,将12种模体特征与多维的节点嵌入向量全部作为机器学习分类器的输入,进行虚假链路预测实验。
基于模体结构的预测方法核心是提取训练集和测试集的模体特征,即计算连边对应的每种模体的数量。以图中abcdef六个节点简化的小网络图为例,来分析计算待预测连边(a,b)对应的每个模体特征如图2。首先寻找与a相连接不与b连接,或与b相连接不与a连接的点,这样就找出了2个三节点模体M1。模体结构 M2的计算方法为寻找节点(a,b)的共同邻居数。M6的计算方法为寻找节点ab除去共同邻居外的其他各自邻居节点,然后这些邻居节点间存在几对连接,即等于(a,b)对应的模体特征M6数量。以此类推,计算得出小网络图中待预测连边(a,b)对应模体特征的数量。

图1 十二种模体结构

图2 模体计算过程
2.3 随机森林分类器
随机森林[12]或随机决策森林是一种用于分类和回归任务的集成学习方法,它在训练时会构造大量相互没有关联的决策树,根据Bagging[13]思想,每棵决策树都是一个分类器,对于一个输入样本,N棵树会有N个分类结果,随机森林集成了所有的分类结果,将投票次数最多的类别指定为最终的输出。对于分类任务,随机森林的输出是大多数决策树选择的类。对于回归任务,返回单个树的平均值[14]。集成学习通过建立几个模型组合的来解决单一预测问题优于任何一个单分类的做出预测,因此具有极好的准确率。此外随机森林还具有能够有效地运行规模较大的数据集,自动评估各个特征在分类问题上的重要性,和高效处理高维特征的输入样本等优点。所以在实验的预测部分选用随机森林分类器进行虚假链路的识别,此外在实验结果分析环节部分模体结构组合时也运用了随机森林的评估特征重要性方法。
3.1 数据说明
本文在虚假链路识别实验种使用了6个真实网络数据,包括科学家合作网络,蛋白质相互作用网络和社交网络三种类型的网络,其中Ca-Erdos992、CA-GrQc[15]为科学家合作网络数据,bio-SC-LC[16]、bio-HS-HT[16]为蛋白质相互作用网络数据,lastfm_asia[17]数据和musae_twitch[18]数据为社交网络数据。
(1)Ca-Erdos数据。鄂尔多斯协作网,利用保罗·鄂尔多斯与他的合著者们的合作数据构建一个名为鄂尔多斯协作网的网络。包含5 094个节点与7515条连边。
(2)CA-GrQc数据。Arxiv广义相对论范畴的科学家协作网络。包含5 242个节点与14 496条连边。
(3)bio-SC-LC数据。中小型蛋白质-蛋白质相互作用网络,节点代表蛋白质分子,连边表示是否存在相互作用。包含2 004个节点与20 452条连边。
(4)bio-HS-HT数据。高通量蛋白质相互作用网络。包含2570个节点与13691条连边。
(5)lastfm_asia数据。LastFM用户的社交网络,于2020年3月从公共API收集。节点是来自亚洲国家的LastFM用户,边是它们之间的相互跟随关系。包含7 624个节点与27 806条连边。
(6)musae_twitch社交网络数据。以某种语言进行流式处理的英文区游戏玩家的Twitch用户网络。此社交网络收集于2018年5月,节点是用户本身,链接是用户之间的友谊。包含7 126个节点与35 324条连边。
3.2 基于单模体的虚假链路预测结果与分析
本小节将12个模体作为特征在科学家合作网络、蛋白质相互作用网络和社交网络上实现基于单模体特征得虚假链路预测,观察分析不同模体在不同类型网络上的预测结果。基于单模体的虚假链路预测实验结果见表1。

表1 基于单模体的虚假链路预测实验结果
从上述基于单模体的虚假链路预测实验结果可以看出,在三种不同类型网络中预测效果最好的单模体结构都是模体M2。在科学家合作网络中大多数科学家的合作形式都是模体M2,即具有共同合作者的两个科学家以后产生合作的可能性会很大;
在社交网络中,表示具有共同网络社交好友的两个用户成为社交好友的概率会更高。
从横向上来看,对比6个网络中预测效果最好的单模体M2的AUC值,可发现预测准确度最高的为CA-GrQc网络,AUC值高达0.916,计算分析网络的基本拓扑属性,CA-GrQc网络的匹配系数和平均聚类系数在6个网络中均是最高。侧面的反应了在匹配系数和平均聚类系数较高的网络中基于单模体特征的虚假链路预测效果更好。再次观察发现ca-Erdos网络在6个网络中基于单模体M2预测的AUC值最低,且网络的匹配系数和平均聚类系数在6个网络中也均是最低的,再一次证实了上述的观点。
结合上述对实验结果的观察与分析,可发现基于单模体的虚假链路预测方法具有一定的通用性。可延伸到其它科学家合作网络、蛋白质相互作用网络和社交网络,甚至这三种类型之外的其他网络,在以后进行基于单模体特征的虚假链路预测时,为了更快取得较好的预测效果,可优先选择M2模体特征在网络的匹配系数和平均聚类系数高的网络上进行预测,从而节省特征提取过程的时间,降低复杂度。
3.3 基于多模体的虚假链路预测结果与分析
传统的基于网络结构相似性的方法中大多只关注其中的一种网络结构,即其中的一种三节点的模体结构,而忽略了节点之间存在的其他作用模式及多种模式的组合。本小节应用随机森林集成学习模型融合12种模体特征进行虚假链路预测,并将预测结果与上一节中预测效果最好的单模体和3种基于共同邻居的相似性指标的预测结果进行比较。对比实验的结果见表2。

表2 三种预测方法的实验结果
从上述三种方法的虚假链路预测实验结果可以看出,综合多种模体特征进行预测的实验结果比基于任意单模体结构和共同邻居相似性的预测性能都要好。在科学家合作网络中多模体的预测准确率比M2提高了44.3%和7.5%,比共同邻居相似性指标最高提高了44.13%和7.3%。在蛋白质相互作用网络中多模体的预测准确率比M2提高14.06%和18.21%,比共同邻居相似性指标最高提高13.28%和17.36%。在社交网络中多模体的预测准确率比M2提高了14.04%和13.73%,比共同邻居相似性指标最高提高13.68%和12.82%。
分析传统链路预测方法 CN、AA、RA 方法的拓扑结构可以发现,这三个指标在拓扑结构上与模体结构 M2一样,预测结果也显示预测指标AUC的值相差不大,说明上述方法仅仅代表一种模体结构,没有考虑到其它模体结构。综合以上的分析,可以得出综合多模体结构的预测方法进行虚假链路预测能够有效提高预测的准确率。
3.4 模体的相关性分析
使用Pearson相关性分析方法来衡量在虚假链路识别中使用的12个模体结构之间的相关性。从三种不同类型网络中各选取一个进行分析,相关性分析热力图如图3。

a)热力图1 b)热力图2 c)热力图3图3 相关性分热力图
科学家合作网络以CA-GrQc网络为例,社交网络以lastfm_asia网络为例进行分析如图3a、3c。12个模体结构被分为两个不同的集合,第一个集合包括模体 M1、M3、M9、M5和M4,它们之间有较强的相关性,观察这5个模体的结构可以发现,这5个模体结构中待预测连边的两个节点没有共同邻居,它们关注的是除共同邻居外与各自邻居节点之间的结构。第二个集合包括模体 M7、M2、M8、M12、M6、M10和M11,这7个模体结构中有6个模体结构的待预测连边节点存在共同邻居,剩下1个模体是待预测连边节点各自的邻居相互连系,即这7个模体仅关注待预测连边中节点的共同邻居之间的关系或节点的邻居节点之间的关系。
蛋白质相互作用网络以bio-HS-HT网络为例进行分析如图3b。特征被大体分为三个不同的集合,第一个集合包括特征M1、M3、M9、M5和M4,与如图3a、3c类似。第二个集合包括特征 M7、M2、M8、M12、M10和M11,这6个模体结构中,大多数模体关注待预测连边中节点的共同邻居之间的关系或共同邻居与单个节点的邻居之间的关系,第三个集合只有剩下的M6模体,它与前两个集合关注点都不一样,它关注的是预测连边节点各自的邻居相互联系。
结合以上三种不同类型网络数据的相关性分析结果发现,在两组数据中,模体结构M1、 M3、M9、M5和M4 总被划分为同组,模体结构M7、M2、M8和M12 总被划分为一组,且模体M6和其他模体的相关系都较弱。可以进一步说明,模体之间的存在相关性与模体结构相似有关,相关性强的模体结构在拓扑结构上比较相似。
为比较部分模体结构组合后的预测效果是否优于多模体的预测效果,根据相关性分析与特征重要性排序进行特征选择,在三个网络分别选出5个模体进行组合后进行预测,并将预测结果与三种经典的特征选择方法、基于多模体预测方法在不同的数据划分比例下进行对比,结果如图4。
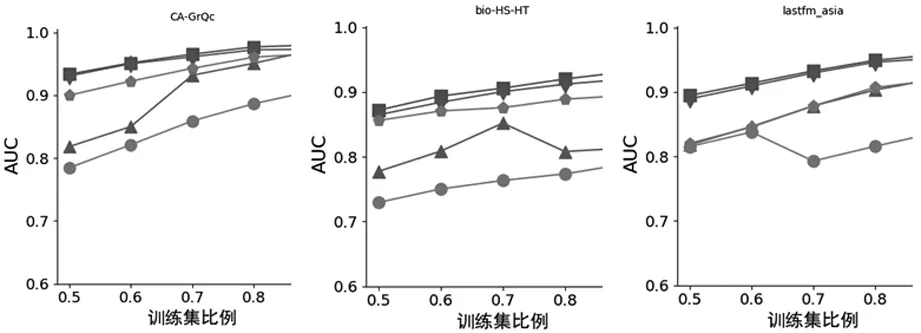
a)分析图1 b)分析图2 c)分析图3图4 虚假链路预测特征选择结果对比
上图中正方形表示多模体预测结果,菱形、三角形和圆形连线分别表示包裹式、过滤式和嵌入式特征选择方法的预测结果,六边形表示根据相关性分析与特征重要性排序进行特征选择后的组合模体预测结果。分析上图特征选择预测结果对比,可以发现在三种不同的网络数据中数据划分的多个情况下,多模体的预测效果依然是最好的,并且不同的特征选择方法的预测效果随训练集比例的上升,变化的趋势也有差别,说明预测的效果于训练集样本比例也有密切的关系。
与三种经典的特征选择方法和多模体的预测方法的预测结果在不同的数据划分比例下进行对比,发现多模体的预测效果依然优于其他组合方法,并且随训练集比例的上升,预测准确度也呈现上升趋势。综上基于多模体的虚假链路预测方法大大提升了虚假链路预测的准确度。在后续的研究中,将在有向网络或时序网络上继续探究基于模体的虚假链路预测方法,扩大虚假链路预测应用范围。
猜你喜欢 链路节点预测 无可预测黄河之声(2022年10期)2022-09-27一种移动感知的混合FSO/RF 下行链路方案*火力与指挥控制(2022年8期)2022-09-16基于RSSI测距的最大似然估计的节点定位算法导航定位学报(2022年4期)2022-08-15选修2-2期中考试预测卷(A卷)中学生数理化(高中版.高二数学)(2022年4期)2022-05-25选修2-2期中考试预测卷(B卷)中学生数理化(高中版.高二数学)(2022年4期)2022-05-25选修2—2期中考试预测卷(A卷)中学生数理化·高二版(2022年4期)2022-05-09分区域的树型多链的无线传感器网络路由算法现代电子技术(2022年4期)2022-02-21天空地一体化网络多中继链路自适应调度技术移动通信(2021年5期)2021-10-25基于图连通支配集的子图匹配优化算法计算机应用与软件(2021年10期)2021-10-15基于点权的混合K-shell关键节点识别方法华东师范大学学报(自然科学版)(2019年3期)2019-06-24








