挖掘社交媒体数据探究自然灾害时公众注意力的变化
时间:2022-12-03 21:05:02 来源:雅意学习网 本文已影响 人 
张晓涵 吕金鑫
(山东科技大学 测绘与空间信息学院, 山东 青岛 266590)
对一般灾害来说,遥感技术已成为当下应急减灾的重要手段,当灾害发生的第一时间,遥感能够提供受灾区域宏观、连续的灾情快照,从而为减灾提供有效的数据支持。尽管遥感技术在灾害领域应用中仍存在局限性,但随着科学的进步,高质量遥感数据的不断涌现,可更大程度上对灾情信息进行反馈。而随着新媒体时代的来临,正如过去十年所见证的那样,社交媒体使用量的激增为灾难情况下的多向交流提供了巨大的潜力。个人越来越多地使用社交媒体来表达他们对当前情况的需求、意见、描述和紧迫性。因此,大多学者认为社交媒体数据可以作为灾害情况下态势感知和救援需求的指标[1-3]。近几年,许多人研究了社交媒体社区的信息流在自然灾害事件阶段的演变模式[4-6],还有部分人专注于灾害期间社交媒体文本情感趋势,例如,有相关研究提出了一种基于情感词语义规则[7]的情感倾向计算方法[8],以及基于词向量的话题聚类方法用于对灾难发生时的社交媒体数据进行辅助分析[9-12],也有研究在灾害主题下通过使用情感词典对微博短文本进行情绪分析,并在灾害应对方面给出指导性建议[13-15]。
语义分析是指综合运用各类方法,学习或理解一段文本中所表达的语义内容,因此有助于对语言理解的方法基本都可算为语义分析的范畴[16]。本研究以微博文本数据源为主着重讨论了一个利用社交媒体数据评估灾害影响的框架,综合运用了语义分析中的批量分词、元词频统计、实体识别以及情感分析等方法,并以2021年10月山西暴雨灾害为例,考察了利用微博平台社交媒体信息提取以告知山西省灾害响应和恢复的潜力。
1.1 研究案例
自2021年10月2日起,山西降雨显著增强。监测显示,2日20时至6日20时,忻州南部、吕梁、太原、阳泉、晋中、临汾、长治累计雨量突破100 mm。其中,太原、阳泉、临汾、长治、吕梁、晋中等大部分地区创下了10月上旬累计降雨量纪录。并受持续强降雨影响,多地出现内涝、地质灾害、洪水等灾情,造成人员伤亡。借此,本研究选取山西省为研究区域,并对一些受暴雨影响较大的城市进行重点分析。
1.2 研究数据
通过网络爬虫技术获取2021年10月1日至2021年10月20日包含山西各城市名称的且与暴雨相关的微博数据,爬取内容包含每条推文的用户ID、用户名、链接、发布日期、位置以及文本内容等信息。由于社交媒体数据庞大且嘈杂,他们需要被挖掘和整合才能用于研究抗灾能力。挖掘社交媒体数据包括数据清理、文本分析和数据可视化,由于其巨大的数量、不平衡的用户构成,并且还有一些因为网络延迟问题导致用户重复发表的推文,所以对于所获取的数据我们进行了数据去重、语料清洗和停用词过滤等数据预处理工作。经初步清洗后的涉灾社交媒体数据共10 815条。示例数据如表1所示。

表1 山西暴雨社交媒体示例数据
其中各城市社交媒体数据量占比如图1所示。

图1 各城市社交媒体数据量占比
2.1 关键词抽取
词频-逆文档频率法(term frequency-inverse document frequency,TF-IDF)是用于数据挖掘的一种加权技术,其中TF是词频(term frequency, TF),式中用F表示,词频指的是某一个给定的词语在该文件中出现的次数,这个数字通常会被归一化。IDF是逆文本频率指数(inverse document frequency,IDF),式中用FID表示,这是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数。因此,TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF的计算如式(1)所示。
(1)
式中,Nw是在某一文本中词条w出现的次数;N是该文本总词条数。
IDF的计算公式如式(2)所示。
(2)
式中,Y是语料库的文档总数;Yw是包含词条w的文档数,分母加一是为了避免w未出现在任何文档中从而导致分母为0的情况。
TF-IDF就是将TF和IDF相乘,如式(3)所示。
(3)
从以上计算公式便可以看出,某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
2.2 命名实体识别
关于社交媒体文本的地理命名实体抽取,本文选用中文词法分析(lexical analysis of Chinese,LAC)模型,LAC是一种联合的词法分析模型,输入采用独热编码(one-hot)方式表示,每一个字有相应的id对应,one-hot序列通过字表转换为实向量表示的字向量序列,字向量再作为循环单元(gated recurrent units,GRU)的输入,学习输入序列的特征表示得到新的特性表示序列,这里还使用一个堆叠的双向GRU结构来增强学习能力,条件随机场(conditional random field,CRF)以GRU学习到的特征为输入,从而可以实现中文分词、词性标注、专名识别等功能。在长文本上准确复刻了百度AI开放平台上的词法分析算法。效果方面,分词、词性、专名识别的整体准确率95.5%;单独评估专名识别任务,F值87.1%,准确率90.3%,召回率85.4%。
2.3 基于百度的情感分析
百度AI开放平台提供全球领先的语音、图像、自然语言处理等多项人工智能技术,我们将预处理后的社交媒体文本数据通过百度的AI接口进行的情感倾向性分析。首先对社交媒体文本数据进行情感语料标注,其中积极、消极语料各标注一千条。然后采用百度AI内置神经网络训练模型进行训练,本次研究所训练模型相对于百度AI平台提供模型准确度提升20%左右。情感结果为[-1,1]之间的情感值,当数值越接近-1代表有强烈的消极情感,当数值越接近1代表有强烈的积极情感。
3.1 公众区域注意力分析
社交媒体中的位置信息是实现一系列分析的基本参数,但一般公众发布社交媒体时只有少部分人选择发送位置,借此本研究考虑利用社交媒体文本中的位置信息来弥补社交媒体位置信息不足的缺点。当灾害发生时,处在灾害影响范围的人可能会发布社交媒体以告知灾害严重性,但不在灾害影响范围的公众会通过新闻等途径对灾害进行了解,并发布社交媒体对受灾严重的地区进行讨论,所以受公众谈论最多的城市和区域可能是最应收到关注的地方。
借此本研究使用中文词法分析LAC模型对暴雨中阶段社交媒体文本中的位置信息进行抽取,通过地理编码赋予其坐标值,其中经LAC模型得到的公众关注区域的前十五,如表2所示。

表2 暴雨期间公众重点关注区域
根据关注权重将公众关注高的区域以核密度分析方法进行可视化,从图2可知,公众关注的重点区域都在山西省南部,其中太原市受到的关注最多,这是因为太原作为山西省会人口基数相对于其他城市较多,当暴雨对城市道路通行造成影响时自然有较多的人进行关注,值得注意的是位于太原西南方向的平遥古城也受到了较多的关注,这是因为公众十分担心强降雨是否会对该世界文化遗产造成实质影响。

图2 文本位置核密度图审图号:晋S(2022)005号
3.2 公众情感时空分析
本研究依托于EasyDL平台,选择高精度且同时兼顾准确率(Precision)和召回率(Recall)的情感分析模型。根据本研究所标注的情感语料,其模型训练效果如表3所示。

表3 情感分析模型效果 单位:%
从结果精度来看,整体情感预测的准确率达到94.6%,且正向和负向样本的F值、精确率以及召回率都有着较好的精度结果。这也为我们后续灾害背景下的公众情感值预测提供了科学支持。
3.2.1公众情感时间演变
我们从时间尺度上对社交媒体文本情感值进行分析,由图3可看出在灾害发生的各个阶段积极情感占比始终高于消极情感和中性情感,且积极情感呈现先下降再上升的趋势,在暴雨中阶段达到最低值50%,随后在暴雨后阶段上升至70%。而消极情感的走势与积极情感呈现相反的趋势,在暴雨阶段达到峰值40%后大幅降落,中性情感占比则是一直维持在10%左右。

图3 情感趋势变化
由此可以看得,大部分公众对这次灾害始终抱有积极的态度,就算是暴雨发生最密集的阶段积极情感也占据着较高的占比。而在暴雨后更是达到了积极情感占比的峰值,说明尽管暴雨灾害对公众过生活带来了较大的影响,尤其是暴雨后带来了滑坡、墙体开裂等所导致的次生灾害,但是随着救援工作和后续修缮工作的展开,公众始终保持着较为积极的态度。
3.2.2公众情感空间分布
对于公众情感分布的空间特征来说,本研究将自身带有地理位置的微博进行地理展布,并借助渔网图进行空间分析,以此分析暴雨中和暴雨后阶段的公众情感变化趋势。借助渔网图可以高效地统计出格网中所占要素的多少,有助于分析不同区域间的情感状态。
由图4的社交媒体文本情感值空间分析可看出,在暴雨中阶段山西省南部还是存在大量的消极情感,这也是因为该阶段持续的高强度降雨使得公众的生活受到了影响,但随着暴雨停止以及全国各地前来支援工作的展开,在暴雨后阶段山西省各城市的公众情感值也基本被积极情感所占据,这也体现了灾害各阶段情感值的异步性和差异性。社交媒体数据与路网数据相结合可看得在暴雨期间山西省南部道路主干道上存在大量的消极情感,这也证实了交通可达性高的区域受暴雨影响较大。
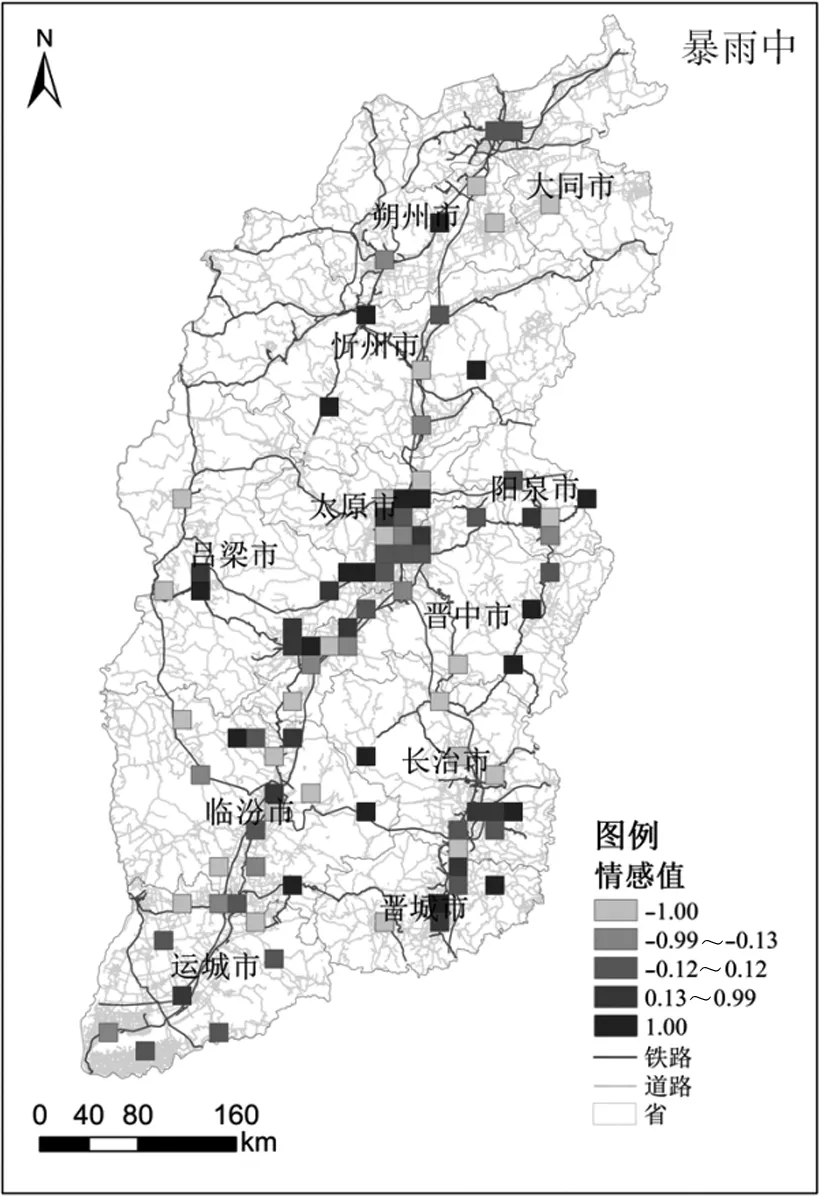
图4 公众情感分布图
3.3 公众文本关注热点分析
对于社交媒体文本关注内容的挖掘,我们首先使用jieba这一成熟的中文分词python库完成社交媒体的分词,随后通过sklearn中实现的TfidfVectorizer类方法来完成TF-IDF关键词信息抽取,同时在处理过程中设置哈工大停用词表(stopword)来去掉复杂符号以及无效字词等数据噪声,最后根据所得词频的权重制作词云图,如图5所示。

(a)暴雨前 (b)暴雨中 (c)暴雨后
通过词云图对高词频关键词进行可视化展示,过滤了大量的低质文本信息,有助于快速了解灾害主题。从图5可看出灾害不同阶段的公众注意力变化,在暴雨前的公众发布微博中大多是对气象局做的预警进行讨论,所以高词频被“天气”“预计”和“降雨”等所占据,而在暴雨发生阶段公众除了发布一些有关暴雨的实时变化和受损程度外,关注更多的是如何进行灾情处理和救援工作,所以该阶段的词频被“暴雨”“救援”“高速”“滑坡”和“坍塌”等词所占据,而在暴雨后阶段我们可以看出词云中出现了“文物”“古建筑”“严重”等对词,这是因为山西为中国地上文物最多的省份,据山西省文化厅在《山西省文化资源概况》中公布的文物资源统计数据为:古建筑及历史建筑约2万处,其中木构建筑9 000余处,宋、金以前的木构建筑106处,占全国同期木结构建筑物的70%以上;元代以来的古戏台2 000多座,均居全国之冠。所以当公众解决暴雨对自身带来的不利影响后,注意力焦点自然放到了易受暴雨次生灾害影响的古建筑上,而相关减灾部门在灾后也需要仔细排查古建筑的受损情况并进行修缮。
自然灾害事件会在很大程度上影响人类的生活,而这一过程也会不可避免地在社交媒体上留下痕迹,社交媒体数据似乎是对传统数据的有益补充,每个数据都阐述自己的情感和观念。当通过社交媒体数据对灾害发生过程有一个准确理解的时候,可以更有效地降低灾害风险。借此我们将社交媒体数据作为灾害影响评估的重要数据源。在本研究中我们以2021年10月山西暴雨为例,借助于语义分析的多种文本探测方法对微博涉灾社交媒体文本进行深度挖掘,探究了灾害期间公众注意力焦点和情感变化,主要解决在灾害发生期间减灾人员无法获取灾害发生地的实时状况的情况。但仍然存在一些不足,本研究采用的数据相对来说较为单一,因此,如何将灾害发生过程中所采集到的多源数据进行深度融合将是我们下一步研究的重点。接下来可考虑将社交媒体数据和灾害传统检测数据进行深度融合,使社交媒体数据和权威数据在灾害研究中相互补充。
猜你喜欢 词频暴雨灾害 “80年未遇暴雨”袭首尔环球时报(2022-08-10)2022-08-10暴雨突袭南方周末(2019-06-13)2019-06-13暴雨袭击支点(2017年8期)2017-08-22灾害肆虐环球时报(2017-08-14)2017-08-142015年我国海洋灾害造成直接经济损失72.74亿元紫光阁(2016年4期)2016-11-19猛兽的委屈少儿科学周刊·儿童版(2015年7期)2015-11-24词频,一部隐秘的历史读者·校园版(2015年7期)2015-05-14汉语音节累积词频对同音字听觉词汇表征的激活作用*心理学报(2014年4期)2014-02-02






