科学数据语义关联技术研究与应用
时间:2023-06-25 20:00:05 来源:雅意学习网 本文已影响 人 
刘峰,韩芳*,魏天珂,陈锟,赵月红,吴慧,范国梅
1.中国科学院计算机网络信息中心,北京 100083
2.中国科学院过程工程研究所,北京 100190
3.中国科学院植物研究所,北京 100093
4.中国科学院微生物研究所,北京 100101
数据爆炸式增长给前沿科学带来了巨大挑战,也催生了以海量数据为驱动的第四范式——数据密集型科学[1]。密集的科学数据作为科学发展的新型战略资源,是驱动创新的重要因素。2019年6月,我国科技部、财政部联合首发认定了20 个国家科学数据中心[2],其中有11 个依托于中国科学院单位建设。随后,中国科学院启动建设了以“总中心-学科中心-所级中心”三类科学数据中心为核心,安全体系、运行体系和评价体系共同保障与驱动的一体化中科院科学数据中心体系。目前,已初步建成了1个总中心、18 个学科中心和16 个优秀所级中心。有了数据中心的强大支撑,第四范式就可以发挥它的真正实力。利用大数据+人工智能技术,计算获取未知的理论,挖掘交叉学科关联关系,形成融合多学科领域、多要素的知识网络。
数据中心的快速发展,在推动科学数据的汇聚、管理和服务的同时,也产生了新的数据“语义孤岛”。数据中心之间因缺乏语义一致性造成了新的共享和互操作难题。以新冠病毒防治、黄河流域生态治理、应急灾难救治等为典型场景的融合科学的发展,都需要跨学科、全景式、全流程的科学数据开放共享[3],而科学数据中心的数据共享依然停留在单领域、数据集元数据语义可发现层面。尽管跨领域、数据内容层面普遍存在着语义关联关系,却没有被充分挖掘与揭示。以上问题严重制约了科研创新与发展的需求,数据资源服务迫切需要从共享型向知识型转化。构建统一的语义标准、关联视图和融合服务,形成科学数据知识化服务解决方案和数据基础设施平台,是新型科研范式的核心方向,也是本文研究的重点内容。
本文首先对科学数据语义关联技术进行广泛多层次的调研,进而对其中的关键技术进行了细化研究,并对重点服务系统进行设计研发,力争为数据中心提供初步的数据语义关联服务框架。在化学、植物、微生物等多个领域展开应用实践,探索数据语义关联技术的可行性和有效性。
本文研究的数据语义关联以语义网络、关联数据、知识图谱为核心,围绕RDF[4]、OWL[5]、SPARQL[6]在语法语义层面上进行统一实现。语义网[7]与关联数据[8]是万维网之父Tim Berners Lee 分别在1998年和2006年提出的概念,从基于本体作为知识表示和推理实现的基础,发展到通过URI 方式来开放发布、链接互联网上各类数据资源,实现可动态关联的知识对象网络[9]。2007年,W3C 的关联开放数据(Linking Open Data,LOD)运动正式启动,LOD-Cloud[10]作为LOD 发布的一个全球分布的关联开放数据构成的最大知识图谱,截至2022年10月已涵盖1,568 个数据集,覆盖众多学科领域。关联科学[11]则是由Kauppinen 在 2011年基于关联数据提出的一种全新科研支撑方式,进一步将科学资源中包括过程、模型、数据、方法和评价指标等,在语义上都进行统一关联[12]。近年,关联数据领域国际上研究重点,已经逐渐由理论研究转向实际应用等[13-14]。
伴随信息技术发展,世界范围内科学数据语义关联在学科领域、图书馆、文献知识库中研究和应用实践都在不断深化。Amrapali 等[15]提出关联数据在生命科学领域应用的三个层次,并针对MEDLINE、PubMed、DrugBank 等实现多源数据语义融合。Bilidas 等[16]提出了STRABO 2 模型,用于大规模地理空间RDF 数据的分布式管理。Rojas[17]、Amaral[18]、Maribel 等[19]分别利用语义关联技术实现欧洲铁路领域的数字互操作性,基于维基数据构建口语化数据集WDV,探索使用众包作为检测难以自动发现的关联数据质量问题的手段,并对DBpedia 数据进行了错误分析等。生物医学领域的语义数据集成平台Linked Life Data[20]、中国科学院自动化研究所认知脑建模组开发的Linked Brain Data (LBD)[21]、Diseasome(人类疾病研究网络)[22]、LinkedGeoData[23]、Chem2Bio2RDF 系统[24]、BioNav系统[25]等都面向不同领域数据,实践了关联数据即服务,探索跨领域关联路径挖掘。美国国会图书馆将其主题词表(LCSH)[26]以SKOS 编码发布;
德国国家图书馆(DNB)通过采用RDA、FOAF 和RELATIONSHIP 等词表,将其规范文档发布成关联数据[27]。SN SciGraph[28]是Springer Nature 运行的关联开放数据平台,整合了来自 Springer Nature 和学术领域主要合作伙伴的开放文献资源。
近些年数据关联技术保持蓬勃发展势头,D2RServer、Drupal、Pubby、Jena[29]、Ontop[30]、Virtuoso[31]、SILK 等一系列工具框架可用于支持结构数据RDF 化、关联发布、存储等[32],大部分开放关联数据集和语义搜索引擎都能提供SPARQL 端点、专用API 消费接口等。但科学数据语义融合依然存在不少挑战,部分技术难点有待突破。针对开放数据关联发现和利用方面,LODsyndesis[33]探索了跨领域数据发现、全局命名空间查找等算法,并基于开放数据云进行实践,Mountantonakis 等提出了LODChain 模型[34],对研究者针对自有RDF 数据拓展与开放云关联路径提供具体思路。随着数据挖掘、自然语言处理技术的发展和成熟,文本语义的深度挖掘成为可能,学界近年开始使用基于深度学习的预训练模型来提升效果。王海林[35]对长文本中实体关系的关键性语义挖掘进行了研究;
刘知远提出一种ERNIE模型[36],考虑将知识引入特殊的语义融合模块,来增强文本中对应的信息表示;
Liu W 提出K-BERT模型[37],将知识图谱中的边关系引入预训练模型,来增强文本预训练模型的效果。
伴随语义关联技术不断发展,DBpedia、Yago、Bio2RDF 等国际开放数据加入到LOD 云,越来越多的学科领域开始基于Linked data 机制进行数据开放与共享。但在科学数据方面,多学科数据中心的不同数据源之间由于规范不同、领域不同、存储结构差异,面临“数据流通不畅”和“语义孤岛”等问题,跨数据中心之间的数据处理与语义关联融合存在诸多挑战。本文针对结构化科学数据自动化语义发布、长文本科学数据标准化语义发布、科学数据语义关联融合与服务三个技术难点分别进行突破,实现多源异构数据资源的语义关联与融合发布,探究数据内容层面的语义检索,为科研人员提供数据发现、访问、关联、融合服务。
2.1 结构化科学数据自动化语义发布
结构化科学数据资源广泛存在于多学科领域数据中,表现为关系型数据存储形式,关联性较强,当前主流的关系型数据库有MySQL、Oracle、SQL Server 等。关系型数据库一般只提供系统内部访问,无法在互联网上开放访问,相对封闭;
不同关系型数据库的表结构、字段又存在较大差异,缺乏统一规范,无法直接与Web 上的开放数据进行关联。针对关系型数据库到RDF 的转化工具有很多,如Ontop、D2RQ 等,这些工具都可以通过语义映射规则实现对关系型数据库的开放访问,但普遍存在一些不足之处:一是对使用者有一定的技术要求,无法面向更广泛的用户群体;
二是不支持语义扩展,不支持推理,转化效率较低。
为了适应更广泛用户群体的需求,实现结构化科学数据更加自动化与高效的关联发布,本文针对结构化科学数据自动化语义发布技术开展深入研究,共分为以下几个步骤,详细设计如图1所示。首先,提供可视化配置界面,辅助用户进行数据表映射、语义扩展、推理等多项配置。在进行数据表映射配置时,分别依据表和字段描述信息,通过本体平台提供的开放API 自动匹配符合条件的术语,将表与本体中的Class 相匹配、字段与本体中的Property 相匹配。如需手动调整,输入关键词即可再次进行术语实时匹配;
在进行语义扩展和推理配置时,可配置字段的文本语义扩展规则等来实现推理规则定义。第二步,基于可视化配置结果,由程序自动化处理和执行配置内容。本体映射与追加,依据数据表映射配置将表、字段与本体进行匹配映射,未匹配内容则基于自建本体进行术语自动追加,待匹配完成后,基于开源RDB2RDF 转化工具,完成关系型数据库到RDF 的初步转化。语义自动扩展依据用户配置的语义扩展规则对文本形式的字段值进行语义扩展,将字段值与国际知识库中的资源、国际本体库中的实例相匹配。对于无法匹配关联的资源,进行URI 分配。自动推理发现,依据推理规则并使用RDF 推理机进行,将新发现的关系自动追加到上述步骤已产生的RDF 三元组中。为了高效执行,充分利用系统CPU 及内存,线程数、缓存空间大小可动态选取和提前设置,提升整体转化的速度。通过上述配置和执行过程,实现了结构化科学数据更加自动化与高效的语义发布。

图1 结构化科学数据自动化语义发布实现流程Fig.1 Implementation process of automated semantic publishing of structured scientific data
本文提出了一种面向结构化科学数据的自动化语义发布方法,支持全面的可视化操作并结合自动化方式,在数据标准化映射的基础上增加了文本语义扩展与推理发现的支持,使用者不需要具备专业技术知识即可完成结构化科学数据语义发布的所有步骤,本文与目前主要的RDB2RDF 工具的对比结果如表1所示。

表1 本文与目前主要的RDB2RDF 工具功能对比Table 1 This article is compared to the main RDB2RDF tool
本文依据上述设计流程,设计了一套支持可视化配置的结构化科学数据自动化语义发布工具,用户可通过可视化操作进行数据表映射关系配置、语义扩展配置、RDF 推理规则配置,配置完成后一键执行即可实现结构化科学数据自动化语义发布,页面效果如图2所示。
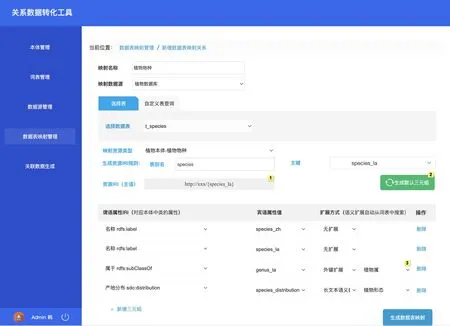
图2 结构化科学数据自动化语义发布可视化配置页面Fig.2 Structured scientific data automated semantic publishing and configuration
2.2 长文本科学数据标准化语义发布
目前科学数据中存在大量的长文本数据资源,例如植物学领域的物种产地分布数据、冰川冻土沙漠科学领域的土壤类型分布数据等。这些长文本资源蕴含丰富的语义知识有待发掘,但文本的存储形式,使得内容层面的知识发现难以进行。当前国内外自然语言处理技术日趋成熟,例如哈尔滨工业大学的语言技术平台(LTP)[38]、美国斯坦福大学的NLP 等,都提供了词性标注、语义依存分析、命名实体识别等常用的文本处理算法。尽管基于LTP 等平台可以将长文本处理为若干个主谓宾三元组,但文本形式的主谓宾依然存在缺乏数据的规范性和语义关联性等问题。
目前针对上述问题的研究尚不够充分,本文针对长文本科学数据提取的主谓宾进行标准化映射与语义发布的过程,进行了详细设计,共分为以下3个步骤,如图3所示。第一步,基于领域科学数据叙词表进行归一化处理,以便提升数据处理的准确性。第二步涵盖3 种策略,分别对应主谓宾三者的语义处理。一是基于Linked Data 机制,为主语分配URI 使Web 可访问,提高数据可发现性,便于其他开放资源与之关联。二是谓语的标准化处理,基于国际本体平台EBI-OLS、Ontobee 提供的开放API,匹配符合条件的术语,进行谓语与标准化本体属性的映射;
对于无法匹配的谓语,构建本体并追加属性,便于后期数据的标准化。三是对宾语进行关联匹配。如宾语为资源实体,则与国际知识库中资源、国际本体库中实例、本流程中已产生的资源实体进行匹配,目前主流的国际知识库有DBpedia、Yago,以及深具学科领域特色的Pubchem、Bio2RDF 等。对于无法在Web 中关联发现的宾语资源,分配URI 使Web 可访问,并记录宾语的词性及对应的谓词,以便后期数据与之匹配。如宾语为字面量,采用XML Schema 来描述Data type。第三步,以RDF 三元组的形式描述标准化后的主谓宾,形成知识库,使机器可读,并通过SPARQL Endpoint 进行关联发布,提供检索服务。通过上述步骤,实现了长文本科学数据的标准化语义发布。

图3 长文本科学数据标准化语义发布实现流程Fig.3 Implementation of standardized semantic publishing of long-text scientific data
本文提出了一种面向长文本科学数据的标准化语义发布方法,采用同义词归一提升长文本知识抽取的准确性,通过与标准化术语对齐、开放资源关联匹配,完成主谓宾的语义化、标准化及关联化,最终实现长文本科学数据标准化语义发布。
本文依据上述设计流程,采用LTP、Apache Jena、OpenLink Virtuoso 等自然语言处理及语义网技术,研发了长文本科学数据标准化语义发布工具,图4以植物物种产地分布数据为例,展示了程序执行结果。

图4 长文本科学数据标准化语义发布示例Fig.4 Example of standardized semantic publishing of long-text scientific data
2.3 科学数据语义关联融合与服务
多学科领域存在丰富的科学数据资源,但目前跨学科领域间的数据关联关系并没有得到有效揭示。虽然通过本章前两个技术方法可以实现不同领域科学数据资源的语义关联发布和机器可读,但在数据融合方面仍存在以下问题:一是多学科领域中进行语义关联检索需要编写复杂的SPARQL 语句,具有较高技术要求,不适用于普通研究者;
二是目前国际上针对分布式开放数据源的语义关联融合服务方面研究不足,无法实现精准化、细粒度、多元化的跨领域科学数据检索。
本文针对科学数据语义关联融合与服务展开研究,基于分布式的SPARQL Endpoint,将已发布的数据关联融合起来,开展多元化的语义关联融合服务,具体包括4 个方面,如图5所示。关联图谱方面,通过SPARQL 联邦查询技术查询数据资源在分布式数据源之间的关联关系,以关联图谱的形式进行直观展示。全文检索方面,将资源实体的名称(rdfs:label)存储在大规模的全文索引中,以弥补SPARQL 在文本检索上的不足,提升跨领域文本检索的性能,目前采用的是全文检索技术Elasticsearch[39]。路径检索方面,探索将数据资源之间的关联关系存储在大规模的图数据库中,采用图检索技术检索不同资源间的关联路径,并以有向图的形式可视化展示,弥补了SPARQL 在路径检索上的不足。语义检索方面,将数据资源存储在大规模的问答系统中,解析用户的问句并提供语义检索服务。通过上述步骤,实现了科学数据语义关联融合与服务。

图5 科学数据语义关联融合与服务实现流程Fig.5 Implementation of scientific data semantic association and fusion
本文提出了一种面向科学数据的语义关联融合与服务方法,充分结合语义网、Linked data 技术的优越性,针对跨领域科学数据资源提供关联图谱、全文检索、路径检索、语义检索等语义关联服务,实现精准化、细粒度、多元化的跨领域科学数据检索,为广大科研人员提供便捷的语义关联融合服务。
依据上述设计流程,基于SPARQL、Apache Jena、OpenLink Virtuoso、Elasticsearch、gStore[40]等技术,构建了科学数据资源网络开放服务平台v1.0[41]。针对平台上已发布的科学数据资源,实现了跨学科领域的数据检索,为广大科研用户提供语义关联融合服务,页面效果如图6所示。
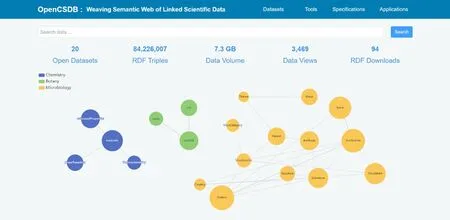
图6 科学数据资源网络开放服务平台Fig.6 Scientific data resources network open platform

图7 化学主题库入驻LOD 云Fig.7 Chemical theme library in LOD cloud
本文基于对科学数据语义关联技术的研究及开发实践,构建了一套针对科学数据进行融合、关联发布和知识发现的技术体系,并与化学化工、植物、微生物等科学数据中心进行对接,在领域数据处理、关键技术运用、关联融合路线方面进行了实践。
3.1 化学领域应用实践
与中国科学院化学化工科学数据中心联合,针对化合物科学数据资源构建了化学领域本体和词表,实现化学化工科学数据中心不同分中心化合物数据资源及其元数据间的多属性语义描述、化合物标识语义对齐与映射、数据资源RDF 定义和关联等语义服务,形成化合物数据关联融合服务。2022年10月,化学主题库语义关联数据ChemDB 整体入驻关联开放数据云平台LOD 云,成为国内化学领域中首个入驻国际化关联开放数据平台的学科数据资源。
ChemDB 数据集主要包括Basic Info、Thermochemistry、Phase Transition、Estimated Properties 四类资源,合计发布39 万+化合物结构及物性等相关数据,1,200 万+RDF 三元组,实现ChemDB 化合物数据资源的结构语义化以及在科学数据资源网络开放服务平台[41]上的解析展示。通过本体映射和语义关联发现,ChemDB 与LOD-Cloud 上的bioportalcheminf、bioportal-sio、bioportal-chebi 数据分别建立了数百万条语义关联关系,拓展了ChemDB 关联科学数据的领域及资源映射,并提供SPARQL 端点服务。
在平台上检索化合物时,会获得该化合物相关联的跨越四类资源的属性信息及与外部资源的关联关系。图8显示了检索 “乙醇Ethanol”时,所关联获取的来自相变数据、热化学数据等属性信息,与此同时,该关联图谱展示出与国际数据平台PubChem、Wikidata 等数据内容的关联。

图8 化合物语义关联图谱示例Fig.8 Example of semantic association graph of compounds
3.2 植物领域应用实践
与植物学科科学数据中心联合,以物种拉丁文名为核心,结合植物领域国际主流的数据规范,打通植物领域的多源异构数据,形成领域数据深度融合的集成与发现服务,最终建成植物领域数据的关联数据网络,以期为特定问题和研究提供相应的知识发现服务。
实践中首先完成对植物领域数据资源梳理,主要包括物种名录、数字标本、彩色图片、文献、专家等数据,同时参考国际知名本体规范、Flora Phenotype Ontology (FLOPO)、Plant Ontology (PO)、The Phenotype And Trait Ontology (PATO)进行本体词表设计,并初步通过复用标准化The Darwin Core Standard,进行规范化RDF 描述,完成对植物物种相关数据的语义化转换。
目前已完成3 个数据源试点关联发布,包括11.8 万物种数据以及 10 万余文献数据,51 万+RDF三元组,构建形成植物领域关联数据网络[42],并与dbpedia 建立14,825 条关联关系,提升了与国际权威关联数据的互操作能力。
3.3 微生物领域应用实践
与国家微生物科学数据中心联合,基于微生物学科领域国际主流的数据规范,首先建立起完整覆盖性状功能数据、组学数据、酶数据、代谢网络、临床、流行病、文献、专利数据等九类核心数据的微生物领域通用本体。基于通用本体,实现分布式多中心的微生物数据的语义关联化发布,覆盖微生物领域新冠病毒数据13 个主要数据源和数据格式,主要包括新冠基因序列、蛋白质、核酸序列、专利、文献等,类型及格式多样,形成基于关联数据的语义融合服务平台。

图9 植物领域关联数据应用服务Fig.9 Linked data application service in plant domain
微生物应用通过路径检索发现技术实现了不同数据资源间的关联路径查询,如图10所示,当任意探索某Gene 序列数据与SARS-CoV-2 病毒数据间的关联关系时,可以通过关联数据发掘出以这两点作为起点终点的2 条链接蛋白质、核酸等信息的路径,并以有向图的形式可视化展示。

图10 微生物领域关联路径检索Fig.10 Linked Path Search in microbiology
目前已完成该领域7,000 万+RDF 数据的开放发布,并且基于微生物关联发布数据,与国际微生物领域本体库信息Gene Ontology、Sequence Ontology、Protein Ontology 等进行关联发现,构建形成微生物领域关联数据网络[43]。目前微生物数据已与LOD-Cloud 上知识库BioPortal Protein Ontology关联链接数目为7,412,与BioPortal-NCBITAXON关联数目为7。
本文在广泛调研的基础上,通过研究结构化科学数据语义关联发布技术,解决了多源异构数据缺乏统一规范、关联融合困难等问题;
针对长文本数据无法被机器所理解、缺乏关联化,设计研究了长文本科学数据语义挖掘方法;
通过科学数据语义融合技术,研发了科学数据语义化融合服务系统;
进而在化学、植物等多个领域进行了应用实践,验证了语义关联技术在解决数据知识化方面的重要性和可行性。然而,本文缺乏对非关系型数据库语义发布的支持,跨领域科学数据资源之间隐藏关联关系也有待深入挖掘。关联科学的全面实现目前还存在缺乏统一机制、技术和资源基础建设不完全等诸多问题,国内相关研究和应用尚未形成规模,重心也主要集中在理论探讨和技术实现上。加之科学领域数据的独特性,使得跨领域的科学数据关联网络应用研究工作更加复杂。综上,本文将持续在语义关联技术以及多领域应用上展开探索实践,扩充对NoSQL 查询结果的RDF 化研究,并结合语义相似度计算、RDF 推理等相关技术,提升跨学科科学数据语义关联能力,紧扣新型科研范式的特点,持续为科学数据中心科研工作者赋能。
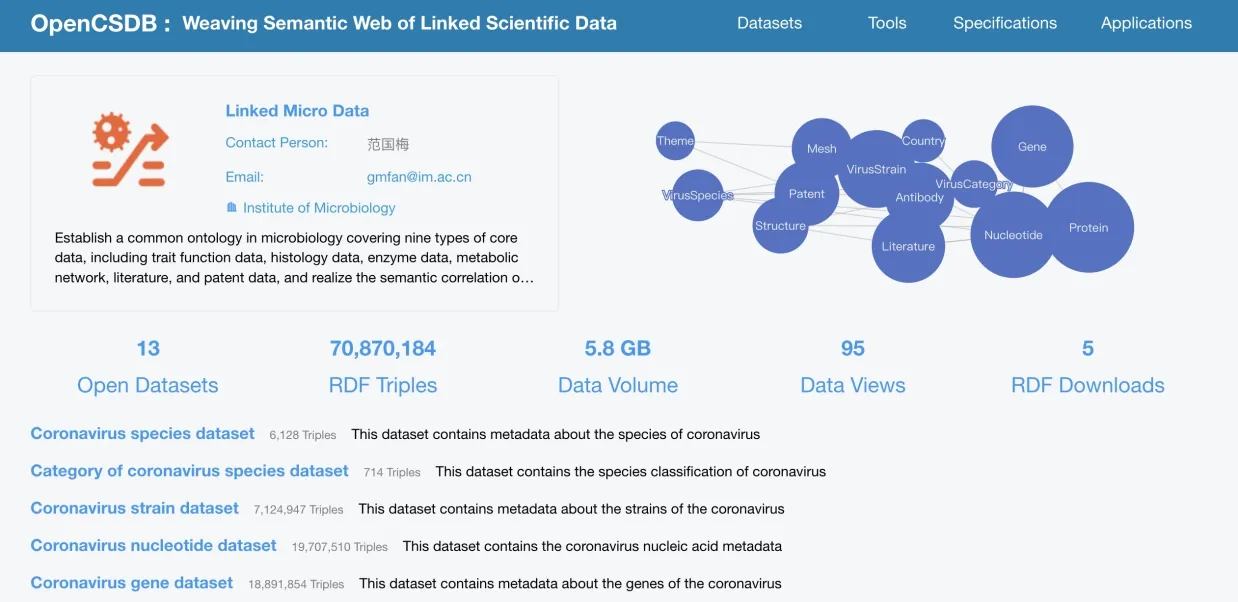
图11 微生物领域关联数据应用服务Fig.11 Linked data application services in microbiology
可以设想,随着数据中心语义挖掘、发布和融合服务的持续开展,科学数据的语义关联融合网络将逐渐扩大。该网络是在数据资源层和数据应用层之间的一个完整的数据知识化服务基础设施。它将有效解决传统端到端范式的不足、数据淹没、数据协议差异化和关联融合不足的问题。大规模科学数据的增长,新的学科分支仍在不断涌现,学科的深度交叉融合势不可挡。科学数据关联网络作为一个由应用驱动的语义化数据网络,在任何跨领域数据共享、发现、集成和重用的场景,如地球科学、数字人文学等,都可以更好地支撑业务场景分析,为深度挖掘交叉学科数据潜在关系和知识提供精准服务。作者相信,科学数据关联网络必将成为打破科学数据“语义孤岛”,实现跨领域科学数据精准化语义融合服务的利器,同时基于开放协作环境下科学数据利用的PARIS 原则[44],真正形成满足数据密集型、融合科学新范式需求,助力深度科研创新的新一代数据基础设施和解决方案。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢关联语义领域不惧于新,不困于形——一道函数“关联”题的剖析与拓展新世纪智能(数学备考)(2021年9期)2021-11-24语言与语义开放教育研究(2020年2期)2020-03-312020 IT领域大事记计算机世界(2020年50期)2020-01-15领域·对峙青年生活(2019年23期)2019-09-10“一带一路”递进,关联民生更紧当代陕西(2019年15期)2019-09-02奇趣搭配学苑创造·A版(2018年11期)2018-02-01智趣读者(2017年5期)2017-02-15“上”与“下”语义的不对称性及其认知阐释现代语文(2016年21期)2016-05-25新常态下推动多层次多领域依法治理初探中共南宁市委党校学报(2015年4期)2015-02-28认知范畴模糊与语义模糊大连民族大学学报(2015年2期)2015-02-27







