深度聚类索引下的海量地震数据快速三维可视化
时间:2023-06-09 10:55:10 来源:雅意学习网 本文已影响 人 
汤文琳,谢 凯,文 畅,贺建飚
(1.长江大学 电子信息学院,湖北 荆州 434023;
2.长江大学 电工电子国家级实验教学示范中心,湖北 荆州 434023;
3.长江大学 西部研究院,新疆 克拉玛依 834000;
4.长江大学 计算机科学学院,湖北 荆州 434023;
5.中南大学 计算机学院,长沙 410083)
三维可视化技术在计算机图形学的发展过程中起重要作用,是对数据对象进行多方位呈现和分析的有效方法,已经渗透到医学[1-2]、海洋[3]、地质[4]、油气勘探等领域。三维可视化技术中的体绘制算法[5-6]已应用在地质勘探方面,能够清晰地描绘地质体内部层次细节信息和特征,为相关研究人员提供数据支持。
目前,三维可视化技术的发展面临诸多问题:一方面,传统体绘制算法复杂度较高,需要较大的内存空间,对计算机硬件的要求较高;
另一方面,对于一定规模的体数据而言,传统算法的计算速度较慢,在进行交互显示时容易出现画面延时、波动卡顿等问题。因此很多三维可视化方案均存在一定局限性。
为此,研究人员提出了诸多相关的优化方案。文献[7-8]提出基于硬件方面的体绘制算法,并在传统光线投射算法和三维纹理映射算法的基础上使用硬件设备提高渲染性能。文献[9]针对海量点云数据索引时间过长且内存占用过大的问题,提出使用八叉树(Octre,OCT)重新组织数据并分块保存,但八叉树最小叶节点的确定较困难。文献[10]针对大量的地理空间数据,使用并行框架构建R 树及其变体,以减少索引更新的时间,但R 树本身结构导致存在部分数据节点空间的重叠浪费问题。文献[11]考虑构造R 树的最小外接矩形框的影响,采用动态K-means 聚类算法,在R 树的基础上对结构进行优化,从而提高算法的检索速度。文献[12]将数据按照时空周期划分,结合动态K 值的聚类算法构建希尔伯特R 树(Hilbert R-Tree,HRT)结构,通过聚类和空间填充曲线在一定程度上降低节点之间的覆盖交叠,能很好地支持海量时空特征数据的索引。
除了从数据结构的角度解决快速可视化的问题,还有一些方案从预测视点的运动轨迹角度出发,结合调度加载算法解决当数据规模较大时出现的显示卡顿问题。文献[13]基于拉格朗日插值算法预测视点的运动轨迹,通过设置不同的插值步长决定最终预测的正确率和渲染效果,但其预测误差会随着阶次增加而增大。文献[14]在视点运动的预测上应用堆叠的长短时记忆(Long Short Term Memory,LSTM)网络,相比传统的估算方法预测精度有所提升。文献[15-16]基于深度学习模型对相关时间轨迹数据进行预测,得到较好的预测效果。文献[17-18]基于可见性判断的角度,通过结合视锥体裁剪算法加速绘制大规模数据,提高交互性能。文献[19-20]除了在数据结构上直接改善索引效率,还结合了动态调度的思想来提高数据加载速度。
本文提出一种面向海量地震数据的快速三维可视化方法,在HRT 结构的基础上使用深度聚类优化结构,改善因空间数据分布不均造成的节点重叠问题,以提高索引查询效率。通过时序卷积模型提前预测下一视点位置,动态划分可视区域,并提前将潜在区域的数据加载到内存中,避免因集中加载引起画面卡顿。此外,在不影响图像质量的前提下提前剔除不必要的节点,避免系统资源浪费,从而加快渲染速度。
本文可视化算法的总体框架结构如图1 所示,主要分为3 个模块,包括建立高效的数据索引结构(a)、视点运动轨迹的预测(b)以及体数据的调度加载(c)。

图1 本文算法的总体框架Fig.1 Gerneral framework of algorithm in this paper
由图1 可知,本文算法首先读取地震数据文件,将原地震数据格式映射到空间的三维结构中,并根据计算机内存划分最小边界立方体(Minimum Bounding Cube,MBC)数据块,在提取数据特征时利用变分深度嵌入聚类(Variational Deep Embedding Clustering,VDEC)完成聚类操作,将聚类之后的数据子块的中心点经过Hilbert 曲线进行降维转换,然后根据节点生成时间和内存重组R 树的结构。当数据进入下一模块时,确定当前视点位置坐标,此过程有两条分支:一是使用视锥体模型对当前视点位置对应的可见空间数据进行剔除并渲染显示;
二是根据当前视点位置利用时序卷积网络模型预测未来视点的位置,通过比较视点动态划分模型,应用双层视锥体裁剪算法得到预测视点所涉及到的数据范围,对潜在数据进行加载渲染,并根据索引结构确定新的视点坐标,绘制下一帧图像。
2.1 数据的索引结构
针对因数据规模的扩大导致的索引结构复杂、效率过低等问题,仅靠改进硬件远远不够,还需改进算法的软件,才能高效解决海量地震数据的快速三维可视化问题。
本文算法的索引模块采用HRT 结构,其思想是采用Hilbert 空间填充曲线,将无序数据按照特定方式连接,令曲线穿过高维空间中的数据,对数据的位置坐标进行编码排序,将高维空间的数据拉直转换成一维空间的数据,然后用最小边界矩形将相邻元素框住,节点越往上,框住空间越大,从而形成HRT结构。
虽然HRT 结构有相对较高的存储利用率,但由于其被应用在大型体数据时,若数据分布不均,则容易出现节点空间重叠问题,即空间上数据对象相近,但经过空间曲线转换后的数据码值所属节点空间不相邻。对于大规模的数据集,可以通过合理的聚类算法将空间特征相似的数据聚集在一起,避免后续码值转换后数据错分的情况发生,以此来提高结构的空间利用率,实现快速索引。
2.2 变分深度嵌入聚类VDEC
为优化索引技术,本文使用变分深度嵌入聚类VDEC 算法,相比传统的聚类算法而言,VDEC 算法使用变分自编码器VAE[21],采用无监督的算法反映输入数据分布的本质特征,并通过深度嵌入聚类(Deep Embedding Clustering,DEC)[22]学习数据潜在隐变量空间的特征表示和聚类分配,以迭代优化目标,提升聚类性能。
变分自编码器VAE 主要通过无监督算法将隐变量空间的数据特征重构输出。VAE 的网络结构包括编码器和解码器。包含地震特征的数据集经过隐变量分布p(z)生成隐变量空间表示z,再通过p(x|z)重构生成其中编码器和解码器的权重和偏差模型分别表示为φ、θ。根据贝叶斯公式可以得到p(z|x),其表达式如式(1)所示:

由于后验分布计算困难,因此通过引入近似后验分布qφ(z|x)逼近真实的后验分布p(z|x)。KL 散度定义为:

采用证据下界ELBO 为变分自编器的损失函数,其表达式如下:
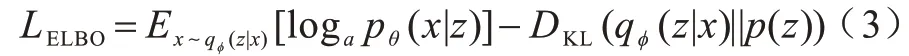
设z服从正态分布:

变分自编码网络VAE 在隐藏层输出的参数有2 个维度,即均值μ和方差σ2:

从近似后验分布qφ(z|x)重采样得到z:

将采样得到的z输入至生成模型pθ(x|z)中,生成新的取qφ(z|x)与先验分布p(z)之间的KL 散度作为编码模型的损失:

对于生成模型,定义解码器的重构误差为其损失:

取经过训练后的自编码器编码部分作为学习到的信息特征z,比较其与聚类中心的相似度,其中相似度及目标分布的定义如下:

其中:j为隐变量空间的维度。
另外定义目标变量P与相似度变量Q的损失函数的表达式如下:

根据特征表示信息特征z与聚类中心之间的相似度表达式(9)得到数据x的聚类标签,如式(12)所示:

用梯度下降法迭代优化总体的目标函数,表达式如式(13)所示:

其中:α为权重参数。
2.3 VDEC-HRT 算法结构
变分深度嵌入聚类融合HRT 树(下文简称为VDEC-HRT)的具体算法如下:
算法1VDEC-HRT 算法

少量数据可以直接加载到内存显示,但当数据规模增大时,则需要将数据分块动态地加载和释放,在动态掉队加载之前根据视点运动轨迹,提前将数据加载到内存等待渲染,以避免大规模数据集中载入引起渲染画面延迟和卡顿。
本文视点预测模块根据持续变化的视点位置和视角预测未来视点的预期位置,并采用时间序列卷积网络(Temporal Convolutional Network,TCN)[23]进行辅助。TCN 网络相比RNN 等网络,具有并行性高、梯度稳定、感受野灵敏等特点。
本文数据集中的每个点代表不同时刻连续运动轨迹的视点坐标,Tc时刻的坐标为pc(uc,vc,wc),其中u、v、w代表不同方向的维度。将当前时刻以及之前时刻的坐标序列X=(p1,p2,…,pc)作为模型的输入,令卷积核F=(f1,f2,…,fk),其中k为卷积核的大小。将当前以及历史时刻的坐标点构成的坐标序列X=(p1,p2,…,pc)输入如图2 所示的因果卷积结构,该结构为单向的时间约束结构,即当前时刻c的卷积操作仅在历史时刻c-1及之前的信息上。pc处的因果卷积输出为:

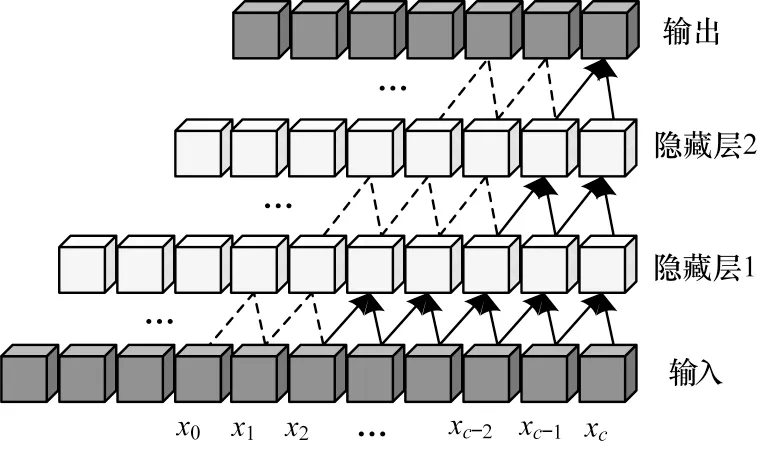
图2 因果卷积结构Fig.2 Structure of causal convolution
之后将pc处的因果卷积输出F(Pc)输入如图3所示的膨胀卷积结构中,其中d为空洞系数。

图3 膨胀卷积结构Fig.3 Structure of expansion convolution
经过膨胀结构的输出公式为:

使用正则化规范隐藏层的输入,并在正则化之后引入Relu 函数:
在经过图2 和图3 的结构之后,引入Dropout 函数简化网络,从而避免过拟合:

为获得长时间序列信息,且由于加上膨胀卷积后,网络模型加深会影响其稳定性,因此本文在网络结构中加入恒等映射,以增加网络稳定度,最终输出结果为:

将每2 个因果膨胀卷积基础层、归一化线性单元块与恒等映射一起作为一个残差模块,令网络模型以跨层方式传递信息。整体时序卷积网络的结构如图4 所示。

图4 时序卷积网络的结构Fig.4 Structure of sequential convolutional network
最后输出结果的表达式如式(19)所示:

时序卷积网络模型可以选择是否由残差模块堆叠起深度网络,且前一个残差模块的输出可以作为下一个残差模块的输入,以此加深网络层数,提取本质特征。输出特征在最后使用全连接层,并添加LeakyRelu 修正线性单元,输出预测视点的坐标位置。
随着数据量的增大,在加载过程中需绘制的对象数量也不断增加。可见性判断方法在不影响渲染质量的前提下,在加载大规模数据时能够减少系统负荷,加快图像渲染的速度。其中,视锥体裁剪方法是可见性判断方法之一,其操作开销相对较小,且易于修改,能够快速准确地加载图形对象。
将原数据等量划分成最小边界立方体子块,之后用VDEC-HRT 算法对原本的地震数据结构进行重组,这部分的数据调度加载利用视锥体对每个MBC 子块进行空间位置关系判断,并在绘制阶段将不在范围内的节点裁剪,从而缩短结构中对象遍历的时间,提高渲染速度。
本文采用的双层视锥体裁剪算法的具体流程如下:
步骤1采用粗裁剪算法,将视锥体简化为圆锥体,判断圆锥体和空间对象的位置关系,减少整体判断次数以提高裁剪效率。粗裁剪算法流程如下:
1)将视锥体六面体简化为一个简易圆锥,其剖面图如图5 所示,其中A 为某一MBC 块的中心坐标,C 为视轴上某点,AC 垂直于圆锥面于点B,d为MBC块中心到任意顶点的距离。从视点位置作最小圆锥包含视锥体,使用简易圆锥检查其与最小边界立方体MBC 之间的位置关系。

图5 MBC 块与简易圆锥的位置剖面图Fig.5 Position profile of MBC block and simple cone
2)如果某一MBC 块的中 心A(x,y,z)∉cone 不在圆锥内部,且AB ≥d,则判断MBC 块在圆锥的外部,对该MBC 块进行裁剪,算法结束,否则继续。
步骤2精细裁剪算法在粗裁剪的基础上进一步使用标准视锥体截棱锥对空间对象进行精细裁剪,提高裁剪的精确性。
使用标准视锥体进行裁剪时,先使用数据的MBC 块对视锥体的6 个平面(即图6 中六面体的上、下、左、右、近、远平面)依次判断空间位置。

图6 视锥体示意图Fig.6 Schematic diagram of visual cone
精细裁剪算法的总体思想:当MBC 块位于视锥体某一平面方程的外部时,即为不可见,则裁掉该物体对象;
当MBC 块在上述过程并未被裁剪,则说明其与视锥体的位置关系为包含或相交,具体来说为下面2 种情况:
1)位置关系为包含。当MBC 块处于6 个平面内,说明空间对象位于视点区域内,则将空间对象直接送入GPU 绘制管线中并进行渲染显示。
2)位置关系为相交。当截锥体某一平面的内侧包含MBC 的一部分,且该平面外侧也包含一部分,说明空间对象与视锥体是相交关系,则继续对下层物体进行判断,依次遍历完所有的空间对象。
具体来说,视点位置位于世界坐标系的零点,首先将视锥体模型沿Z轴正向放置,使用设定的投影矩阵转换顶点,进而得到截锥体对应的6 个平面方程。然后找出MBC 块的顶点n点和p点,p点是距离平面最近的顶点,n点是最远对角线的顶点(距离p最远的顶点):设 2 个顶点的坐标分别为p(xmin,ymin,zmin),n(xmax,ymax,zmax),视锥体的6 个平面方程为ax+by+cz+d=0,将n、p分别带入6 个平面方程中,若axmin+bymin+czmin+d>0,则可以判断该MBC块离平面最近的顶点在平面外侧,则此MBC 块在平面外侧,对该MBC块进行裁剪。同理,若p(xmin,ymin,zmin)在平面内侧,n(xmax,ymax,zmax)在平面外侧,说明MBC 块与视锥体相交。如果p点和n点都在视锥体平面方程的内侧,则说明MBC 块在平面内侧,直接将该MBC 块的数据送入绘制管道渲染显示。
将视点移动过程看作如图7所示的视点动态模型,移动过程将整个数据对象范围划分为当前可见区域、潜在预加载区域以及释放卸载区域。在经过时序卷积模型预测得到下一视点坐标之后,通过比较视点划分的区域,结合视锥体模型进行卸载和加载渲染。具体来说,当视点处于A 位置时,图7 中的1、2 部分即为当前可见区域,对其进行渲染显示,潜在预加载区域则是划分为预测下一视点B的可见区域,即图7的2、3部分。当视点移动到B 时需要提前将该区域的数据标记为可见数据,并载入到内存等待渲染,便于用户在持续浏览时直接对数据对象进行读取显示,避免交互时出现画面卡滞的现象。另外当视点由A 运动到B 时,将区域1标记为释放卸载域以减少系统负荷。

图7 视点动态模型示意图Fig.7 Schematic diagram of viewpoint dynamic model
体数据调度加载的流程如图8 所示。首先,根据当前视点坐标并结合视点动态划分模型,通过约束条件构建视锥体,获取当前视点范围内必须绘制的数据块,将当前可见的数据块送入GPU 渲染管线。其次,若视点持续进行匀速规则运动,则通过算法预测下一视点坐标,根据预测的坐标并结合视点动态区域模型获取潜在预加载区域的数据块,通过视锥体裁剪潜在区域范围内的必要绘制数据,并将其载入内存等待显示。最后,释放卸载区域的数据,开始下一帧的绘制。
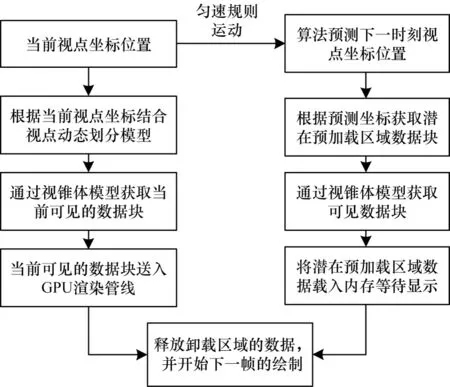
图8 体数据调度加载流程Fig.8 Procedure of volume data scheduling loading
5.1 实验平台及设置
实验中用到的硬件设备为Dell G5-5500,处理器为Intel Core i7-10750H,芯片类型为GeForce RTX 2060,CPU 主频2.60 GHz,内存16 GB。应用程序使用Visual Studio 2015+PyCharm2019+QT5.7 进行代码编写。
实验所用的数据为我国某油田部分的地震工区数据,并以SEG-Y 格式进行存储。数据分为3 组,数据集A 为469.7 MB,数据集B(体数据分布较均匀)为3 348.5 MB,数据集C(数据量较大且较分散)为14 643.4 MB,地震数据信息中包含埋藏深度、范围、厚度、伸展趋势等信息。
5.2 实验结果
本文分别针对索引结构、视点预测以及体数据调度加载模块进行对比评估,以证明本文方法的有效性。
5.2.1 数据结构的索引效率
为评估VDEC 模型聚类的有效性,本文在MNIST 手写数据集[24]上对其进行验证,首先采用K-means 算法初始化簇中心,使用编码器预训练,其中优化器采用Adam 优化器得到模型最佳参数,将学习率设置0.002,每训练10 个epoch 更新一次参数,输出维度设置为10,训练200 次,并根据encode 编码层返回的均值和方差构建隐藏特征空间z。用TSNE降维方法将采样的小部分z映射到二维空间,并进行可视化,其潜在空间中的数据聚集分布如图9 所示,可以看出数据的聚类效果较好,这说明潜在特征表示适合聚类。

图9 VDEC 潜在空间的数据聚类分布Fig.9 Data clustering distribution of VDEC potential space
此外,本文选择聚类准确率(Accuracy,ACC)、标准互化信息(Normalized Mutual Information,NMI)以及调整兰德指数(Adjusted Rand Index,ARI)作为聚类指标[25],这3 类指标的值均是越靠近1,表明聚类效果越好。在MNIST 数据集上用不同算法测试聚类效果,结果如表1 所示。根据实验结果,本文算法在3 个评价指标上依次比K-means 算法提高了44.79%、44.44%、59.78%,相比AE 和DEC 算法,其聚类效果也有一定提升。这说明本文算法相对于传统聚类算法的效果更好,能够为HRT 树的建树过程奠定良好的结构基础,避免数据节点在建树过程中出现空间重叠问题,进而提高索引的效率。

表1 不同算法在MNIST 数据集上的结果对比Table 1 Comparison of results of different algorithms under MNIST dataset
本文通过与其他索引结构算法的查询效率进行对比,评估本文算法整体的数据结构索引效果。具体来说,为证明数据量大小的差异对索引结果的影响,对A 组数据分别取2%、4%、6%的数据量比率,同理B、C 两组也取2%、4%、6%比率的数据,并比较OCT、HRT、基于K 均值算法的HRT(KHRT)、变分深度嵌入聚类下的HRT(Variational Deep Embedding Clustering-HRT,VDEC-HRT)等结构查询数据块算法的查询时间,结果如图10 所示。

图10 不同结构查询数据块算法的查询时间对比Fig.10 Comparison of query time of different structure query data block algorithms
由图10 可以看到,对于A 组数据而言,本文算法(VDEC-HRT)相比OCT、HRT 和KHRT 算法的查询时间有所减少,但差距不明显。对于B 组数据,与OCT 算法相比,本文VDEC-HRT 索引数据块的时间减少了65.05%~66.96%,与HRT 算法相比,本文算法索引时间减少了63.10%~66.01%,与KHRT 相比减少了42.27%~51.74%。对于查询C组数据子块,与OCT、HRT和KHRT算法对比,本文算法的时间分别减少了67.69%~72.22%,64.14%~66.37%,54.10%~55.89%。所以即使对于规模较大的数据,本文算法能通过改进聚类使数据节点空间减少重叠,从而有效减少频繁访问的次数,提高查询索引的效率。
5.2.2 对视点预测的评估
为评估预测算法的准确率,本文与拉格朗日插值、堆叠LSTM 算法进行对比,分别在时长1 min、5 min、10 min下预测数据块的准确率,结果如表2所示。由表2可知,本文算法的精度相比拉格朗日插值、堆叠LSTM算法分别提高了12.08%~22.70%,2.24%~4.34%。虽然随着时长和数据集的增大,预测的正确率有所下降,但本文算法相对于另外2种算法的预测正确率仍然有一定提升。

表2 不同算法在不同时长下预测数据块的准确率对比Table 2 Comparison of accuracy of algorithm prediction data blocks in different time periods %
此外,本文取35 frame/s左右的平均帧率预测采样部分位置坐标的X和Y分量,对比使用TCN和LSTM网络预测位置坐标的效果,TCN 网络的参数设置nb_filters=64,kernel_size=3,残差块中使用relu 激活函数,时间步长选取20。迭代20次后得到的拟合结果如图11所示。在本文坐标数据集中,TCN、LSTM 网络的预测精度分别为97.68%、96.92%。由图11 可以看出,TCN 网络在X、Y坐标分量上的预测精度比LSTM 网络稍好,说明其在本文预测视点的任务中是有效的,有利于后续数据调度加载的准确性。

图11 不同网络的拟合结果对比曲线Fig.11 Comparison curve of fitting results of different networks
为测试步长对预测结果的影响,在平均帧率不变的情况下,分别设置步长为10、20、30,并随机改变摄像机的位置和方位,使视点保持匀速运动持续10 min,同时为了避免不同平均帧率实验的干扰,本文选择24、48 和96 frame/s 的平均帧率进行非同步长计算和对比预测错误率,结果如图12 所示。

图12 不同步长对预测准确率的影响Fig.12 Influence of asynchronous length on prediction accuracy
由图12 可知,误差会随着步长增加而增大,但步长越小,预测精度相对越低,因此可以通过调节步长参数来达到提高预测准确性的目的。
5.2.3 对数据加载渲染的评估
为测试本文算法的稳定性,选择60 帧采样点作为X轴分量,分别在A、B、C 数据集上比较无预测算法(即在本文算法基础上去除视点运动轨迹预测模块的算法)与本文算法的帧率,结果如图13 所示。由图13 可知,在A 组数据集上,即使数据量较小,帧率也能保持在50 frame/s 左右。在B、C 组数据集上采用本文算法的帧率,相比无预测算法来说,即使在数据规模较大时,帧率仍然相对较高且较稳定,这意味着渲染效果更加稳定平滑,能够避免交互时产生波动。

图13 不同算法在3 组数据集下的帧率对比Fig.13 Comparison of frame rates of different algorithms under three sets of datasets
5.2.4 对整体性能的评估
为整体评估算法,将本文的VDEC-HRT、OCT、HRT、KHRT 分别与基于TCN 和双层视锥体裁剪的调度模型(Scheduling Model Based on TCN and Double-Layer Visual Cone Clipping,TDVSM)算法进行组合,并测试各算法组合的整体交互性能。以B 组数据为例,每隔10 片图像对地震数据进行切片,并记录各算法查询切片的时间,结果如图14 所示。可以看出,与其他算法相比,本文算法查询切片的时间明显减少。

图14 不同算法查询切片的时间对比Fig.14 Comparison of query slice time of different algorithms
最后,本文对系统的整体显示效果进行测试,系统平台设置有不同显示模式下的渲染效果,图15 是体数据显示的蓝白红模式(彩色效果见《计算机工程》官网HTML 版),图16 是地震数据沿不同测线方向切片显示效果(彩色效果见《计算机工程》官网HTML 版)。在运行观测实际的地震数据时,由图15和图16 可以看出,本文系统平台能够高质量地描绘出地震体数据的内部结构和信息。

图15 地震体数据显示效果Fig.15 Display effect of seismic body data

图16 地震数据沿不同测线方向切片的显示效果Fig.16 Effect of slice display of seismic data along different survey lines
针对海量地震数据体绘制在集中载入时存在画面显示延迟和卡顿的问题,本文提出一种快速三维可视化算法。在HRT 结构的基础上通过变分深度聚类改善节点数据因分布不均造成的空间重叠问题,提高数据索引的效率。使用时序卷积模型预测视点的运动轨迹,并与双层视锥体裁剪算法相结合,以更精确地将数据提前载入内存等待渲染,避免画面显示延迟,提高渲染速度。实验结果表明,本文算法相较于OCT、HRT、KHRT 等算法的查询时间均有所减少,且渲染帧率波动较为稳定平滑,能够实现海量地震数据的快速三维可视化。下一步将使用其他类型的大规模数据集对本文算法进行测试,尝试采用wassterient 距离代替KL 散度,并在视点预测模块中引入注意力机制,从而提高图像质量。
猜你喜欢 锥体视点聚类 专家视点机械研究与应用(2022年2期)2022-05-21CBL型裂解炉急冷锅炉入口锥体的腐蚀与防护措施石油化工腐蚀与防护(2021年5期)2021-11-01搜集凹面锥体小猕猴智力画刊(2020年5期)2020-06-01基于K-means聚类的车-地无线通信场强研究铁道通信信号(2019年6期)2019-10-08锥体上滚实验的力学分析物理实验(2019年4期)2019-05-07基于微多普勒的空间锥体目标微动分类北京航空航天大学学报(2017年7期)2017-11-24基于高斯混合聚类的阵列干涉SAR三维成像雷达学报(2017年6期)2017-03-26环境视点环境(2016年7期)2016-05-14基于Spark平台的K-means聚类算法改进及并行化实现互联网天地(2016年1期)2016-05-04基于加权模糊聚类的不平衡数据分类方法现代计算机(2016年17期)2016-02-28






