支持语义标注的办公文档格式扩展方法
时间:2023-06-08 15:15:23 来源:雅意学习网 本文已影响 人 
范博珩,李宁,田英爱
(北京信息科技大学 计算机学院,北京 100101)
随着各类文档数量日益增多以及传播日益广泛,人们希望计算机能够自动处理和理解文档,而这些一般需要通过语义标注来实现。语义标注是指利用本体(ontology)或词汇表(vocabulary)对文档的特定内容添加语义标记,标识出与之对应的概念或实体,并且建立起标注内容与本体之间的联系。语义标注是文档的核心技术之一[1]。语义标注的结果使文档具有了语义元数据,使得机器可以自动理解和处理文档,也便于文档信息的共享和有效利用,可以高效实现文档的语义检索、内容提取和自动分类等智能化处理。
近年来,Web上的语义标注研究成果十分丰富,Google、Yahoo和Yandex等公司共同创建了一个共享词汇表——Schema.org[2]。在线商店将schemas标记嵌入至描述产品的超文本标记语言(hypertext markup language,HTML)页面中,以使搜索引擎能够轻松识别产品价格并为网站增加流量[3]。经过语义标注后得到的产品结构化数据也为产品分类、产品匹配、推荐系统、产品知识图谱等新兴研究领域的发展提供了支持。
然而,文本不仅仅来自HTML文档,也来自办公文档、版式文档以及复杂混合格式的文档。其中,仅有少数研究针对办公文档进行语义标注。Tallis[4]提供了一套针对DOC格式的文档半自动化标注系统Semantic Word,Carr等[5]提出了WICKOffice系统,Fink等[6]开发了一个Word插件,用户可使用SmartTag和自定义XML标记对文档中的生物医学领域的专业术语进行手工标注。但这些标注系统无法支持标准的办公文档格式,也无法支持多源语义标注。
办公文档语义标注之所以研究成果较少,大多因办公文档的复杂性所致。在对办公文档进行语义标注时,需要满足以下的条件:1)能够在文档格式中记录语义元数据;
2)能够支持OOXML(office open XML)、ODF(open document format)、UOF(unified office document format)等主流办公文档格式标准;
3)能够经受对语义元数据的编辑和修改;
4)能够在文档编辑过程中保持文档内容与语义元数据的同步一致;
5)能够支持多源语义标注,即允许同一标注内容对应多个本体或词汇表。正是因为流式文档语义标注的复杂性,至今尚未见到在办公文档中进行语义标注的成熟方法。
针对上述问题,本文提出一种在办公文档中支持语义标注的方法,包括对办公文档格式的扩展,标注规则的设计以及在主流办公软件中支持语义标注的方法。本文的成果已经被团体标准T/CESA 1176—2021《信息技术 电子文档语义元数据嵌入方法》[7]所采纳。
目前虽然办公文档语义标注的研究较少,但仍有一些相关的成果可以借鉴。例如,HTML中文本的存储方式与办公文档相似;
PDF(portable document format)中也有成熟的语义标注技术。因此,这些研究均可为本文提供参考。
在HTML中,语义标注的具体形式主要以嵌入式为主,标注结果作为相关元素的属性加以记录。Tittel等[8]在关于中世纪法语的HTML网页内容中嵌入RDFa(resource description framework in attributes)标记的词汇,将网页中的实体与词汇表中的概念和属性对应起来;
Beno等[9]构造了Doc2RDF,能够自动对法律领域的HTML文本进行标注;
Salem等[10]在Beno研究的基础之上,实现了标注多个领域的HTML文本的功能;
Mbouadeu[11]、Albukhitan等[12]利用深度学习的方法自动标注HTML文档,并使用microdata或microformats将标注结果记录于原文档中。
在PDF中,语义标注的具体形式主要以分离式为主,标注结果存放在PDF文档的单独数据块中,并与原文档建立关联。Eriksson[13]、Kim等[14]通过使用可扩展元数据平台(extensible metadata platform,XMP)[15]技术在PDF文档中建立内容与本体的映射关系。
上述研究中,嵌入式标注结果易于管理且能保证语义元数据与文档内容同步,但是会给原文档格式带来一定的影响。与之相比,分离式标注结果需要单独进行存放,难以保证语义元数据与文档内容同步,但是对原有文档格式的影响较小。本文采用嵌入式标注方法对办公文档进行语义标注。
在几种嵌入式语义标注技术中,RDFa[16]具有更强的表达力与适用性[17],能够支持多词汇表。因此,鉴于RDFa应用在HTML流式文档中的诸多优点,本文基于RDFa对办公文档格式OOXML进行扩展,以使办公文档中可以加入语义元数据标记。目前OOXML格式在办公文档中应用最广,以之为研究对象具有典型意义,其他基于XML的办公文档格式标准ODF和UOF等与之类似,本文的方法也同样适用。
采用RDFa对OOXML进行语义标注前,首先需要分析HTML和OOXML的文档结构。下面以图1中的新闻为例加以说明。

图1 一个新闻的例子
对于一篇HTML文档,文档的主体内容通过组合不同的块级元素和行内元素进行显示。块级元素如div、p等通常表示文本段落或片段,而行内元素如span等则通常用来更细粒度地分割局部文本。RDFa是万维互联网联盟(World Wide Web Consortium)W3C制定的标准,它能够在这些元素中增加下列属性:
@vocab:当前所用的默认词汇表;
@typeof:资源的概念(类型);
@property:某类型所具有的属性。
RDFa不会影响HTML的浏览。使用RDFa对HTML进行语义标注如图2所示。

图2 RDFa在HTML中的标注示例
图2中,有两个标注内容,即“新闻社”和“东非”,它们分别为词汇表Schema.org中表示组织(typeof="Organization")和地点(typeof="Place")的两个实体名称(property="name")。
与HTML格式不同,OOXML文档的存储基于ZIP压缩打包格式[18],文档的主体内容记录在文件包内的document.xml文件中。段落在OOXML格式中均以段落元素p存储,是构成文档的基本单元。p下包含段落属性元素pPr和句元素r,段落中的文本根据式样的不同会形成多个句(run)。r下包含句属性元素rPr和文本元素t。句中的文本记录在t下。语义元数据主要在段落或句一级进行标注。
可以借鉴RDFa在HTML中的用法,将RDFa属性嵌入到t或其他元素中,如图3所示。

图3 RDFa在OOXML中的标注示例
虽然对于上述的一般情况,这种基于RDFa对OOXML进行扩展的方式是可行的,但是OOXML毕竟与HTML不同,OOXML主要用于办公文档编辑,其文档数据与语义信息存在较为复杂的对应关系,可能导致以下问题。
1) OOXML中语义标注的范围可能与文本元素的范围不一致,具体体现在两个方面:
① 单一文本可能对应多个语义标注内容,如上例中的“埃塞俄比亚”、“肯尼亚”等地名实体出现在同一个t下,而由于t已是构成文本的最小单元,因此无法为不同的实体指定不同的RDFa属性,参见图4;

图4 文本元素中包含多个实体的OOXML源码
② 一个待标注内容可能分散在多个句或文本之中,在Microsoft Word等办公软件中,往往会自动把中英文文本和数字分在不同的句中,难以获得一个完整的标注,如上例中的“2月14日”会放在多个句元素和文本元素中,参见图5。

图5 实体分散成多个句元素和文本元素的OOXML源码
2) 对于一般用户来说,HTML仅供浏览,不需进行编辑。而OOXML则要能支持编辑,因而嵌入了语义元数据的文档需要能够被办公软件打开和编辑。另外,嵌入的语义元数据需要具备鲁棒性,经得起反复编辑。
上述问题,需要专门设计流式文档的语义标注规则,并找到办公软件支持语义标注的方法。
为解决前文所述的问题,本文专门设计了用于办公文档标注的结构模型。标注模型如图6所示。

图6 标注模型结构
该标注模型用XML Schema来描述,根元素为“metadata”,该元素具有@ID、@Seq和@Begin三个属性,也可使用任何RDFa的属性。
对于单一文本对应多个语义标注内容的情况,可将文本元素中的多个待标注内容分别放入多个metadata元素节点进行描述,并将相关的文本设为metadata元素的内容。以图4中的“埃塞俄比亚”、“肯尼亚”和“蝗灾”为例,其标注的结果如图7所示。

图7 单一文本对应多个语义标注内容的标注方法
图7中,“埃塞俄比亚”和“肯尼亚”为词汇表Schema.org中的地点(typeof="Place")名称(property="name"),“蝗灾”为词汇表Schema.org中的事件(typeof="Event")名称(property="name")。
对于一个待标注内容分散在多个句或文本之中的情况,可以通过指定metadata元素中@ID和@Seq两个属性,将多个语义标注内容按顺序进行组合。@ID为标注实体的编号,@Seq为标注的顺序号,@ID结合@Seq可以实现同一实体的多段标注。@Begin指示某一标注的开始或结束。
例如,对应图5的情况,“2月14日”为事件的发生日期,在一些词汇表中,日期进一步分解为年、月、日,因此,“2月14日”要按两个实体来标注,即“2月”和“14日”。

图8 一个待标注内容分散在多个句或文本之中的标注方法
图8中,1~4行以及5~8行描述的两个metadata元素节点具有同样的@ID,表示它们共同标注一个日期元数据。第1行的metadata元素节点其属性Begin="true",第4行的metadata元素节点其属性Begin="false",它们具有同样的@Seq属性(Seq="1"),表示是词汇表Schema.org中事件(typeof="Event")的发生日期(property="startDate")的第一部分标注内容,对应两个句中的文本“2”、“月”。同理,5~8行表示事件发生日期的第二部分标注内容,对应两个句中的文本“14”、“日”。
在OOXML格式的文档中添加RDFa属性得到扩展的OOXML文档,称之为语义文档。然而这种扩展将导致文字处理软件无法正常打开和编辑语义文档。本文提出了一种解决方法,即通过预处理和后处理方法实现语义文档与普通办公文档之间的无缝切换。
4.1 语义文档的预处理转换
预处理时,利用办公文档中的批注机制作为文字处理软件中记录语义元数据的载体,将语义文档中标注的语义元数据存储至批注元素中。办公文档中的批注是附加在文档内容片段上的注释信息。批注与办公文档中的文本、图片等内容独立显示并相互关联。同时,用户在编辑文档内容时,也能够直接编辑和修改批注,对于编辑具有很好的鲁棒性。因此,采用批注来存储语义元数据,可以支持用户在编辑过程中对语义元数据进行编辑和修改,也可保持在编辑过程中语义元数据的同步一致。
在OOXML打包文件中的document.xml内,批注由commentRangeStart、commentRangeEnd和comment-Reference三种元素描述。其中,commentRangeStart和commentRangeEnd确定批注的起始位置和结束位置,表示批注的范围;
commentReference与OOXML打包文件中的comment.xml内的comment元素的内容相关联,用于在文字处理软件中显示批注的内容。在一个批注中,上述4个元素具有相同的属性@ID。例如,图1中的“东非”添加批注后,document.xml中将会呈现如图9的结构。

图9 document.xml中的批注引用
在comment.xml文件中的批注结构如图10所示。

图10 comment.xml中的批注引用
为能够区分一般的批注和包含语义元数据的批注,本文采用特殊的用户名称用于语义元数据批注。未来,建议为文档批注增加一个特殊的类型,用于在办公文档中记录语义元数据。但是这要通过标准制定组织改进相关的标准。目前,采用特殊用户名的方式也是完全可以的,其前提是该用户只可进行语义标注,不能进行一般的批注。
预处理算法的核心思想是找到每一个语义标注内容的范围,即语义元素metadata的范围,以此来确定批注的范围,并根据记录的语义元数据确定批注的内容。在确定批注范围时,会出现两种情况:1) 单一文本下具有多个语义标注实体;
2) 标注实体由多个文本描述。对于情况1,需要调整文档结构,复制多个r和t元素节点并保证每个t下只包含一个metadata元素节点,以符合OOXML添加批注的标准格式。对于情况2,则直接根据两个metadata元素节点确定批注范围即可。本文采用如下算法进行语义文档的预处理转换。

Algorithm1:CreateCommentNodeInput:m as metadata, r as range, u as userOutput:c as the comment node1 Function CreateCommentNode(m,r,u)2 Create a new comment node c;3 c.content ← n.metadata; // n is the semantic node in r4 c.range ← Range(t); // t is the text node in r;Range(t) means get range of t5 c.user ← "dsm";// Set user of c as "dsm"6 Output c;7 End Function

Algorithm2:ForwardTransformInput:D as the semantic documentOutput:D as the transformed document in the standard format1 Function ForwardTransform(D)2 Letc-list be the comment list to be added into D;3 c-list ← null;4 For each paragraph p in D5 For each run node r in p6 Ifr contains multiple semantic nodes Then7 Split r into multiple nodes r-list,each of which contains a single semantic node;

8 End If9 End For10 End For11 For each semantic node n in D12 Ifn spans multiple text nodes Then13 Group the text nodes of same semantics into one segment;14 For each text segment s which n spans15 c ← CreateCommentNode(n.metadata,Range(s),"dsm");16 Add c into c-list;17 End For18 Else // n spans single text node t19 c ← CreateCommentNode(n.metadata,Range(t),"dsm");20 Add c into c-list;21 End If22 End for23 Add c-list into D;24 Output D;25 End Function
算法1用来生成批注元素,包括批注的范围和内容。算法2是预处理算法的流程。算法2中,步骤2~3声明待添加的批注元素集合并赋值为空。步骤4~22是生成语义批注的过程。其中,步骤4~10用于调整文档结构,对应前文所述确定批注范围的第一种情况。步骤11~22中,若标注实体由多个文本描述,即前文所述的第二种情况,则执行13~17步骤。确定标注实体的起始和结束位置后,调用算法1生成语义批注,否则根据步骤4~10调整好的文档结构,直接调用算法1生成语义批注。步骤23~25输出转换完成的文档。
4.2 语义文档的后处理转换
后处理的目的与预处理相反,核心思想是找到办公文档每一个带有语义元数据的批注及其范围,以此来确定语义标注的内容和范围。在进行后处理转换时,首先要找到语义元数据批注的所有元素,即批注范围元素和批注内容元素。在确定语义标注范围和内容时,同样会出现两种情况:1) 实体由单一文本描述;
2) 实体由多个文本描述。对于情况1,将实体放入metadata元素节点进行描述,批注的内容放至metadata属性中。对于情况2,需要添加两个metadata元素节点,设置相应的@Begin,并分别将其插入在批注起始位置后和批注结束位置前。批注的内容放至@Begin值为true的metadata属性中。本文采用如下算法进行语义文档的后处理转换。

Algorithm3:BackwardTransformInput:D as the document in the standard formatOutput:D as the semantic document1 Function BackwardTransform(D)2 For each comment node c in D3 Ifc.user is "dsm"Then4 Letn be the semantic node;5 Ifc spans multiple text segment Then6 n.id ← GenerateID();// Generate ID7 n.metadata ← c.content;8 Insert n at the first text node;9 Add end tag of n with n.id at the end of c.range;10 Else // c spans single text node t11 n.id ← GenerateID();12 n.metadata ← c.content;13 Insert n at t;14 End If15 Remove c;16 End If17 End For18 Output D;19End Function
在算法3中,步骤2~17是添加语义元素metadata的过程。步骤3根据批注用户名判断该批注是否为语义批注,若判定为真则执行步骤4~15。步骤5~14用于添加语义元素metadata的位置和内容。其中,若实体由多个文本描述,即前文所述第二种情况,则执行步骤6~9,将批注内容赋值给@Begin值为“true”的语义元素metadata的属性中,并在实体文本的结束位置添加@Begin值为“false”的语义元素;
否则,执行步骤11~13,将批注内容赋值于语义元素metadata的属性中,并将metadata插入至文本元素t下。步骤18~19输出转换完成的文档。
本文基于C#和winform窗体设计器实现了一个办公文档语义标注工具,具有语义标注、预处理转换和后处理转换3个功能。以图1的新闻为例,根据前述办公文档语义标注方法进行标注。
图1的新闻案例中涉及多个实体对象,如“2月14日”、“新闻社”、“蝗灾”等。应用本文的方法进行实体标注时,需要根据对象的性质从Schema.org词汇表中选择合适的类型,同时还要选择合适的属性。以新闻示例的正文第一段为例,标注结果如图11所示。

图11 语义标注后的扩展OOXML文档示例
上述扩展的OOXML文档经过预处理转换,生成标准的OOXML文档,图12展示了办公软件Microsoft Word打开该文档后的编辑界面。从图12中可以看到,语义文档中的语义元数据在Word文档中以批注的形式呈现,每个语义批注对应一个命名实体,允许用户按批注方式进行编辑。同时,也允许用户在Word文档中的任意位置添加语义批注。
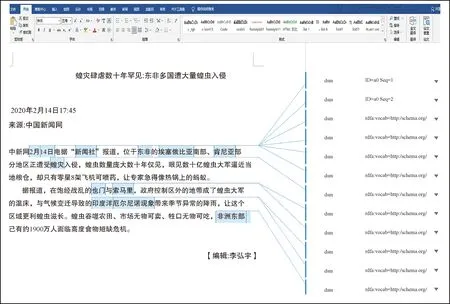
图12 Microsoft Word中打开经过预处理的文档示例
图12的文档经过后处理转换后,可以生成新的语义文档。图13展示了“新闻社”、“东非”、“埃塞俄比亚”3个实体在新的语义文档中的标注示例。
从图13中可以看到,“新闻社”、“东非”、“埃塞俄比亚”3个实体的标注方式与图11不同,这是因为在进行前一步的预处理转换时,将同一文本元素t下的多个语义标注实体分配了多个r和t元素,调整了文档结构,使每一个语义标注实体对应一个r和t。图13与图11文档的语义逻辑是一致的。

图13 后处理转换生成的语义文档示例
语义文档可使用Google结构化测试工具或者RDFa.info[19]验证器检测RDFa语法的正确性,并可使用GRDDL(gleaning resource descriptions from dialects of languages)[20]或W3C的RDFa解析器从中提取出RDF三元组结构的语义元数据,生成Turtle、RDF/XML或N-Triples等文件。图14为解析的结构化数据。由图14可知,语义文档可以通过RDFa.info测试工具验证。以检测到的“Event”为例,“Event”有两条数据,即语义文档中标注的事件名称(name)“蝗灾”及事件发生的时间(startDate)“2月14日”。

图14 文档结构化数据
基于RDF数据,可进一步使用RDFa.info生成知识图谱。图15为图11部分语义标注内容对应的知识图谱。

图15 基于文档语义元数据生成的知识图谱
上述结果表明,本文提出的方法能够成功实现办公文档的语义标注,方便计算机对文档的知识提取。
本文的方法适用于其他以XML为基础的办公文档格式,比如ODF和UOF。在版式文档格式中,国内的OFD(Open Fixed-layout Document)也可被本文的方法所支持。这3种文档格式标准的XML Schema框架与OOXML十分相似,因此本文的方法可以扩展到上述的3种文档格式中,具有通用性。此外,本文采用RDFa作为语义标注技术,能够实现多个词汇表的标注,具有很强的语义表达能力。用户可以选择不同的词汇表对文档中的实体进行标注,标注后文档所蕴含的语义信息也会不同。
本文以流式文档的典型格式OOXML为研究对象,详细分析了OOXML格式与HTML格式在文本描述方面的差异性。在此基础上,提出了流式文档语义格式扩展方法。针对流式文档格式特点,设计了特定的语义标注规则。同时,提出通过预处理和后处理实现语义文档与办公文档之间无缝切换的方法,以保证标注后的文档经过预处理能够被文字处理软件支持,经过后处理能够使带有语义批注的办公文档重新形成语义文档。实验证明,使用本文的标注方法能够增强办公文档的语义表示能力,便于计算机对文档的自动理解和处理。
本文主要针对OOXML格式的办公文档进行语义标注,后续可扩展到ODF、UOF等格式,为更多的办公文档格式增加语义标注的支持能力。本文的标注对象是文档中的文本,尚未考虑其他对象,比如图像、表格、公式等元素的语义标注,它们的结构更加复杂,需要进一步研究和完善标注方法,使得标注内容更加全面。此外,可考虑利用自然语言处理技术实现自动化或交互式的语义标注,提高标注的效率。
猜你喜欢 词汇表文档办公 浅谈Matlab与Word文档的应用接口客联(2022年3期)2022-05-31AKTION MENSCH总部办公空间现代装饰(2021年5期)2021-12-02有人一声不吭向你扔了个文档中国新闻周刊(2021年26期)2021-07-27Peritoneal dissemination of pancreatic cancer caused by endoscopic ultrasound-guided fine needle aspiration: A case report and literature reviewWorld Journal of Gastroenterology(2021年3期)2021-02-04Sharecuse共享办公空间现代装饰(2020年3期)2020-04-13X-workingspace办公空间现代装饰(2020年3期)2020-04-13Word文档 高效分合有高招电脑爱好者(2017年7期)2017-05-06Persistence of the reproductive toxicity of chlorpiryphos-ethyl in male Wistar ratAsian Pacific Journal of Reproduction(2015年1期)2015-12-22词汇表双语时代(2009年3期)2009-09-24广场办公环球时报(2009-07-08)2009-07-08








