文本生成图像中语义-空间特征增强算法
时间:2023-05-29 19:40:20 来源:雅意学习网 本文已影响 人 
贺小峰,毛 琳,杨大伟
(大连民族大学 机电工程学院,辽宁 大连 116605)
文本生成图像是利用所给文本中语义信息生成与文本内容对应图像,在图像生成过程中,图像特征与语义特征经生成器多次迭代循环进行特征融合。由于图像生成过程中经过多次特征传递,上下文参考信息丢失从而影响融合效果,生成图像清晰度、多样性和生成图像与原始图像间相似度有待提高。
在基于语义图像处理研究中,文本生成图像更多地借鉴主流深度学习方法。随着生成对抗网络(Generative Adversarial Networks,GAN)的快速发展[1],基于GAN的文本生成图像研究成为目前最热门的方法。Zhang等[2]提出叠加对抗网络(Stacked GAN,StackGAN),该网络使用两阶段GAN生成图像:第一阶段GAN根据文本生成原始形状和颜色,生成第一阶段低分辨率图像;
第二阶段以第一阶段为输入,生成高分辨率图像并纠正第一阶段中的错误。之后,在StackGAN-v2中提出使用由树状结构的多个生成器和鉴别器生成高分辨率图像[3],但该网络生成图像质量不高,没有充分利用文本信息对生成图像进行矫正。在此基础上Xu等[4]提出注意力机制生成对抗网络(Attentional GAN,AttnGAN),在StackGAN-v2的思想上引入长短时记忆网络(Long Short-Term Memory,LSTM)的文本解码器[5],使得语句和单词可以映射到语义空间,使用注意力模型将语义信息与图像特征相融合,从而生成与文本描述信息近似的图像,但使用多生成器结构会缺乏跨生成器间特征传递,特征融合质量下降,并且该网络结构训练数据过大,训练效率较低。
在近期的文本生成图像研究中,单生成器和单鉴别器结构成为新研究趋势。该结构是在单生成器中进行特征融合,从而生成由低分辨率到高分辨率的图像[6-8]。在Tao等[7]提出的深度融合对抗网络(Deep Fusion GANs,DF-GAN)中,设计一种深度文本图像融合块,该模块在生成器生成图像时加深图像特征与文本信息的融合过程,同时DF-GAN中还设计一种匹配感知梯度,用于合成更真实、语义更加一致的图像。以DF-GAN为基础,Hu等[8]提出语义-空间生成对抗网络(Semantic-Spatial Aware GAN,SSA-GAN),设计语义-空间卷积网络使得卷积特征融合时提取更加充分。但单生成器结构在多级特征融合中只使用上级特征信息,从而导致特征多样性不强,特征融合结果不佳。
针对文本生成图像生成器中多特征传递丰富性与特征融合不充分问题,本文提出语义-空间特征增强生成对抗网络(Semantic-spatial Feature Enhancement GAN,SFE-GAN)。该网络借鉴密集连接网络(Densely Connected Convolutional Networks,DensNet)特征增强思想[9],在不同层级中分别引入密集连接结构,对跨层间的特征融合进行加强并提高特征丰富性,增强语义信息对生成图像的约束性,采用分段式结构连接加强特征传递中的稳定性,改善生成图像过程中特征融合不充分和语义与图像不匹配的问题,从而提高生成图像质量。
1.1 语义-空间卷积特征融合问题分析
现有文本生成图像网络SSA-GAN中,输入符合正态分布的噪声z∈100并通过特征映射后重塑为像素特征f∈4×4×512;
输入文本经文本编码器提取语义特征,其中包括语句特征向量e∈256和单词特征矩阵将两种特征输入语义-空间感知卷积进行上采样与特征融合。
定义1:Si(a*b)代表对像素特征a与语义特征b通过语义-空间感知卷积进行特征融合操作。生成图像特征公式:
(1)
式中:F为生成图像特征;
z为输入噪声;
P为特征映射操作;
b为输入文本信息;
T为文本编码器提取输入文本中语义特征并映射到语义空间。输入特征与输出特征之间的传递方式为循环前向传递,所以在上采样和特征融合过程中缺少跨层间特征信息,使得在特征融合时缺少当前层与其余层间联系。
语义-空间感知卷积的作用是使语义信息指导图像生成过程,从而更有效地利用语义空间中的语义信息与输入图像特征融合。但在语义-空间感知卷积的连续特征传递中缺少跨层间特征传递,因此生成图像质量下降。语义-空间感知卷积如图1。

图1 语义-空间感知卷积
语义-空间感知卷积中映射掩码图受语义特征约束,语义特征引导图像生成,在语义-空间感知卷积中掩码图特征ki∈hi×wi与语义特征γ和β融合,特征融合公式:
(2)

在公式(2)中可以明显看出,掩码图特征为输出融合特征的重要参数,对语义-空间感知卷积的输入图像特征加强以提高输入特征的多样性。因为多特征的传递与融合是保证生成图像准确性与高质量的关键,故在特征传递过程中引入密集连接网络如图2。

图2 密集连接网络
在图像生成过程中各级特征对生成图像有着不同程度的影响,传递过程中只输入上层单级特征会导致多特征传递丰富性不足和图像特征与语义特征融合不充分。为融合不同尺度特征,在密集连接模块中引入最近邻插值上采样块,将形状为H×W×C的输入特征图,通过上采样得到形状为2H×2W×C的输出特征图。密集连接网络可充分提取不同分辨率图像中的特征,增加网络宽度,增强多尺度特征传递,使图像特征在上采样过程中和语义特征融合得更加充分。因此在特征融合过程中加入多级信息,加强输入特征多样性,可以使特征融合质量提升。
输入特征经密集连接网络后的输出特征可表示为
xi=Conv([x0,x1,…,xi-1])。
(3)
式中:xi为输出特征;
Conv为使用卷积运算调整特征图的通道数;
[x0,x1,…,xi-1]为各层输出特征进行Concat特征合并。
1.2 SFE-GAN实现
SFE-GAN为保证生成图像的清晰度、多样性和生成图像与图像文本描述的相似性,充分融合不同层间多尺度特征信息,通过以下3个步骤构建SFE-GAN。
(1)在生成器训练过程中,使用双向LSTM构成的文本编码器,提取输入文本中的单词与语句特征向量;
采用InceptionV3模型[10]图像特征提取器,提取训练输入图像特征,特征提取公式:
Ew×n,e=Ls(Tinput);
(4)
Pi=Iv3(Pinput)。
(5)
式中:Ew×n为单词特征矩阵;
e为语句特征向量;
Ls为双向LSTM文本编码器;
Tinput为输入文本信息;
Pi为图像特征;
Iv3为InceptionV3模型的图像特征提取器;
Pinput为输入图像。
(2)在生成图像过程中,低分辨率图像生成过程侧重于图像结构和布局,高分辨率图像生成过程侧重于图像细节和随机变化[11]。因此将语义-空间卷积层分为浅层和深层,其中浅层为低分辨率生成图像层,深层为高分辨率生成图像层(1~3层为浅层,4~6层为深层)。
(3)在深浅层中分别加入密集连接构成深浅层密集连接结构,浅层和深层分别进行特征融合,加强特征提取,保证特征融合过程的充分性。在加强生成图像结构和布局的同时,强化生成图像细节。特征融合公式:

(6)
式中:Fshallow和Fdeep分别为浅层和深层输出图像特征;
xi为各层级输入图像特征;
f为各语义-空间感知卷积中特征融合运算;
⊕为Concat特征合并运算。密集连接采用分段连接结构,目的是将浅层中融合得到的特征信息更稳定地传递到深层中,从而加强深层输入特征信息,强化语义特征与图像特征融合,使得生成图像与文本描述更加相似。SFE-GAN结构如图3。
本文采用的损失函数:
LG=LG1+λLDASMS;
(7)
LGi=-Ex~Pg[D(G(z),e)];
(8)
V(D,G)=Ex~pdata(x)[logD(x)]+Ez~pz(z)[log(1-D(G(Z)))]。
(9)
式中:LG为生成器损失函数;
LG1为SFE-GAN损失函数;
LDASMS[4]为深度多注意力模型损失函数(Deep Attentional Multimodal Similarity Model,DAMSM),该模型可对训练进行约束;
λ为DASMS损失权重;
E为期望值;
x为来自生成器中模型分布Pg;
e为语义特征向量;
V(D,G)为生成器与判别器进行对抗训练,使其在训练过程中不断优化,直到生成质量最优图像。

图3 SFE-GAN结构
2.1 实验环境与数据集
网络运行系统为Ubuntu 16.04,显卡配置为NVIDIA GeForce 1080Ti。编程语言Python,深度学习框架使用Pytorch 1.7.0。实验数据集为CUB 200-2011(Caltech-UCSD Birds 200-2011),该数据集有11 788张鸟类图像,包含200类鸟类子类,每只鸟具有10句文字描述,其中训练集有8 855张图像,测试集有2 933张图像[12]。
在CUB数据集下,将批尺寸设置为8,生成器和判别器学习率分别设置为0.000 1和0.000 4,迭代次数为600,引入Adam优化器对训练进行优化[13],其余参数与原网络保持一致。
2.2 评价指标
为保证网络的有效性,生成模型使用Inception评分(Inception Source,IS)和Fréchet Inception距离(Fréchet Inception Distance,FID)作为评价指标。其中,IS指标由Barratt等[14]提出,目的是将生成图像输入Inception V3模型中,根据生成数值判断生成图像的清晰度和多样性,IS评分越高代表生成图像的清晰度和多样性越高,生成的模型质量越好。IS计算公式:
IS=exp(Ex~pgDKL(p(y|x)||p(y)))。
(10)
式中:x为生成器生成图像;
p(y|x)为生成图像在各类别中的概率分布;
p(y)为概率分布向量;
DKL为对p(y|x)和p(y)计算KL的散度。
FID指标由Heusel等[15]提出,目的是计算真实图像与生成图像间特征向量的距离。将生成图像输入Inception V3模型中计算相似度,FID评分越小代表生成图像与输入图像相似度越高,生成图片的多样性越好。FID计算公式:
(11)
式中:μr、μg分别为真实图像和生成图像的特征均值;
Tr为矩阵的迹;
νr、νg分别为真实图像和生成图像的特征协方差矩阵。
2.3 实验结果与分析
选取训练集中的图像和对应的全部文本描述作为训练图像和文本,选取测试集中的文本描述作为测试文本,输入噪声选取符合正态分布的噪声。在相同硬件环境和参数设置条件下进行对比试验,使用两种模型分别生成30 000张图像,通过IS和FID指标对生成图像进行测试,实验结果对比见表1。
实验结果表明,SFE-GAN的IS和FID评分分别为5.00和20.46,高于改进前原始算法SSA-GAN的4.81和20.73,分别提升4.0%和1.3%。输入文本和输入图像经SFE-GAN处理,多特征传递与特征融合加强。SSA-GAN与SFE-GAN进行特征融合可视化对比如图4。

图4 特征融合可视化对比图
使用相同的输入文本对两种网络的图像特征与语义特征融合进行对比。从图4a、图4b和图4c中可以发现原网络生成的图像映射掩码图的“喙部”“尾部”“头部”和“眼部”等有明显错误,原网络的图像掩码图经语义信息校正后生成输出图像,由于原网络的多特征传递不充分,导致特征融合结果较差,影响生成图像质量。SFE-GAN网络生成的映射掩码图4d、图4e和图4f修正了原网络映射掩码图中的错误,并且生成与输入文本匹配的正确图像,因此可以得出SFE-GAN明显改善SSA-GAN中特征融合与多特征传递不充分的问题,原网络与SFE-GAN网络的文本生成图像可视化结果对比如图5。

图5 SSA-GAN与SFE-GAN文本生成图像对比
总体上,SSA-GAN中输入文本对生成图像的约束作用不佳,进而导致生成图像与输入语义内容不匹配。采用SFE-GAN后,特征丰富性得到提高,图像特征与语义特征的融合得到增强,生成图像充分利用所给语义信息,提升了生成图像的清晰度、图像细节和生成图像与原始图像间的相似度。SFE-GAN针对输入文本特征信息能够清晰地生成与其对应的特征部位,但SSA-GAN生成的“鸟喙”“鸟尾”和“颜色”等内容不佳且生成图像不清晰;
同时SFE-GAN还提升了生成图像背景的清晰度,使得生成图像减少背景信息对内容的影响。本文提出的SFE-GAN可以充分利用语义特征对生成图形进行约束,从而提升生成图像的质量。
2.4 消融实验
为验证SFE-GAN网络结构的有效性,针对所提出的网络模型进行消融实验,采用CUB数据集和FID、IS评价指标。基于SSA-GAN(参考图3),浅层密集网络S-Net(Shallow dense network)在1、2层引入两层密集连接网络,深层密集网络D-Net(Deep dense network)在5、6层引入两层密集连接网络。改进网络消融实验对比见表2。引入深浅层分段密集连接结构后,IS和FID可得到较好的提升。
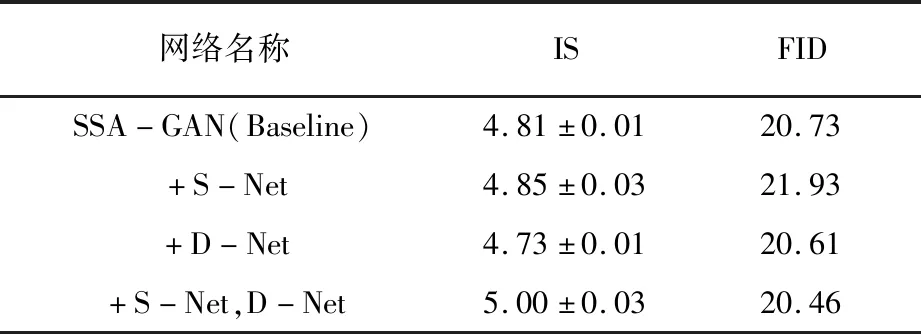
表2 改进网络消融实验对比
本文针对文本生成图像网络中多特征传递与特征融合不充分的问题,提出语义-空间特征增强生成对抗网络SFE-GAN,通过密集连接结构增强跨层特征传递与融合,分段连接使得特征融合过程更加充分,充分利用语义特征与图像特征,从而提高生成图像的清晰度、多样性和与原始图像间的相似度。SFE-GAN为提升特征丰富性和加强特征融合提供一种新思路,使文本生成图像网络更好地应用于视频和图像交互领域。后续工作中,将进一步改善生成图像过程中特征多样性与特征融合的问题,提升生成图像质量。
猜你喜欢 密集语义卷积 真实场景水下语义分割方法及数据集北京航空航天大学学报(2022年8期)2022-08-31耕地保护政策密集出台今日农业(2021年9期)2021-11-26基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02密集恐惧症英语文摘(2021年2期)2021-07-22卷积神经网络的分析与设计电子制作(2019年13期)2020-01-14从滤波器理解卷积电子制作(2019年11期)2019-07-04基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20“吃+NP”的语义生成机制研究长江学术(2016年4期)2016-03-11做个Patty万人迷BOSS臻品(2015年1期)2015-09-10全球导航四大系统密集发射卫星太空探索(2015年5期)2015-07-12








