基于图卷积集成的网络表示学习
时间:2023-05-31 11:15:24 来源:雅意学习网 本文已影响 人 
常新功,王金珏
(山西财经大学 信息学院,山西 太原 030006)
近年来,基于网络数据结构的深度学习十分流行,广泛应用于学术领域和工业领域。网络包括节点和边,其中节点表示实体,边表示节点之间的关系。现实世界中很多数据都可以表示为网络,例如社交网络[1-2]、生物-蛋白网络[3]等。利用网络分析挖掘有价值的信息备受关注,因为高效的网络分析不仅处理节点分类[1]、链路预测[2]、网络可视化[4-5]等下游任务时有着很好的效果,而且在金融欺诈、推荐系统等场景下都有实际的应用价值。例如,在社交网络中通过节点分类可以对不同的用户推荐不同的物品;
在生物网络中,可以通过分析已知的疾病与基因关系预测潜在的致病基因等。
由于网络数据的非欧几里得结构,大多数传统的网络分析方法不适合使用机器学习技术解决。网络表示学习[6-8]很好地解决了上述问题,通过将节点映射到低维空间中,节点用学习生成的低维、稠密的向量重新表示,同时尽可能保留网络中包含的结构信息。因此,网络被映射到向量空间中就可以使用经典的机器学习技术处理很多网络分析问题。现有的网络表示学习方法主要分为以下3 类:
1)基于矩阵分解的网络表示学习。Roweis 等[9]提出的局部线性表示算法(locally linear embeding,LLE)假设节点和它的邻居节点都处于同一流形区域,通过它的邻居节点表示的线性组合近似得到节点表示;
He 等[10]提出的保留局部映射算法(locality preserving projections,LPP)通过对非线性的拉普拉斯特征映射方法进行线性的近似得到节点表示;
Tu 等[11]提出的图形分解算法(max margin deep walk,MMDW)通过对邻接矩阵分解得到节点表示。Cao 等[12]提出的GraRep 算法通过保留节点的k阶邻近性保留全局网络结构。
2)基于浅层神经网络的网络表示学习。Perozzi等[13]提出的DeepWalk 算法通过随机游走遍历网络中的节点得到有序的节点序列,然后利用Skip-Gram 模型预测节点的前后序列学习得到节点的向量表示;
Grover 等[14]提出的Node2Vec 改进了DeepWalk 的随机游走过程,通过引进两个参数p和q控制深度优先搜索和广度优先搜索;
Tang等[15]提出的Line 算法能够处理任意类型的大规模网络,包括有向和无向、有权重和无权重,该算法保留了网络中节点的一阶邻近性和二阶邻近性。
3)基于深度学习的网络表示学习。Wang 等[16]提出的SDNE 算法利用深度神经网络对网络表示学习进行建模,将输入节点映射到高度非线性空间中获取网络结构信息。Hamilton 等[17]提出的GraphSAGE 是一种适用于大规模网络的归纳式学习方法,通过聚集采样到的邻居节点表示更新当前节点的特征表示。Wang 等[18]提出的Graph-GAN 引入对抗生成网络进行网络表示学习。上述研究方法大多是设计一种有效的模型分别应用不同的数据集学习得到高质量的网络表示,但是单一模型的泛化能力较弱。为了解决此问题,目前有学者提出使用集成思想学习网络表示,Zhang等[19]提出的基于集成学习的网络表示学习,其中stacking 集成分别将GCN 和GAE 作为初级模型,得到两部分节点嵌入拼接后作为节点特征,其与原始图数据构成新数据集,最后将三层GCN 作为次级模型处理新数据集,使用部分节点标签进行半监督训练。
本文引入了stacking 集成方法学习网络表示。集成方法是对于同一网络并行训练多个较弱的个体学习器,每个个体学习器的输出都是网络表示,然后采用某种结合策略集成这些输出进而得到更好的网络表示。stacking 集成方法是集成方法的一种,结合策略是学习法,即选用次级学习器集成个体学习器的输出。次级学习器的选择是影响结果的重要因素,现有工作证明Kipf 等[20]提出的图卷积神经网络[21](graph convolutional network,GCN)在提升网络分析性能上有着显著的效果,GCN 通过卷积层聚合网络中节点及邻居的信息,根据归一化拉普拉斯矩阵的性质向邻居分配权重,中心节点及邻居信息加权后更新中心节点的特征表示。
综上所述,本文的贡献有以下几点:
1)提出了基于stacking 集成学习的网络表示学习,并行训练多个较弱的初级学习器,并将它们的网络表示拼接,选用GCN 作为次级学习器,聚合中心节点及邻居信息得到最终的网络表示,这样可得到更好的网络表示。
2)利用网络的一阶邻近性设计了损失函数;
3)设计了评价指标MRR、Hit@1、Hit@3、Hit@10,分别评价初级学习器和集成后的网络表示,验证了提出的算法具有较好的网络表示性能,各评价指标平均提升了1.47~2.97 倍。
定义1给定网络G=
定义2[6]给定网络G,每个节点的属性特征是m维,G有n个节点,则网络G对应的节点特征矩阵H∈Rn×m。网络表示学习的目标是根据网络中任意节点vi∈V学习得到低维向量Z∈Rn×d,其中d≪n。学习到的低维向量表示可客观反映节点在原始网络中的结构特性。例如,相似的节点应相互靠近,不相似的节点应相互远离。
定义3一阶邻近性[15]。网络中的一阶邻近性是指两个节点之间存在边,若节点vi和vj之间存在边,这条边的权重wi,j表示vi和vj之间的一阶邻近性,若节点vi和vj之间没有边,则vi和vj之间的一阶邻近性为0。
定义4二阶邻近性[15]。网络中一对节点vi和vj之间的二阶邻近性是指它们的邻域网络结构之间的相似性,令li=(wi,1,wi,2,···,wi,|V|)表示节点vi与其他所有节点的一阶邻近性,vi和vj的二阶邻近性由li和lj的相似性决定。
定义5集成学习[22]。集成学习是构建多个个体学习器 ℓ1,ℓ2,…,ℓn,再用某种结合策略将它们的输出结合起来,结合策略有平均法、投票法和学习法。给定网络G,定义2 中的网络表示学习方法可作为个体学习器,其结构如图1。若个体学习器是同种则是同质集成,否则是异质集成。
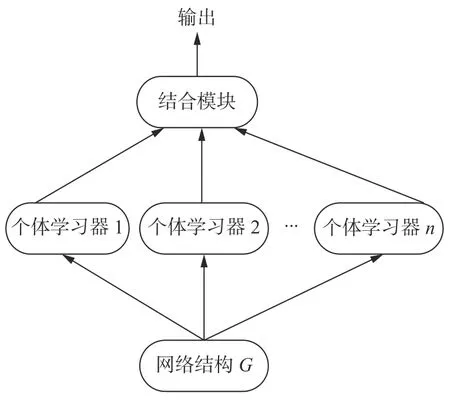
图1 集成学习结构Fig.1 Structure of ensemble learning
定义6stacking 集成学习[22]。stacking 集成学习的结合策略是学习法,对于同一网络通过k个初级学习器 ℓ1,ℓ2,…,ℓk学习得到k部分节点嵌入的特征向量z0,z1,…,zk−1,其嵌入维度均为d维,然后按节点将zi,i∈[0,k−1]对应拼接得到嵌入z,其嵌入维度是k×d维,最后使用次级学习器ℓ得到最终的嵌入z",为了方便对比设置其嵌入维度也是d维。
本文将stacking 集成思想引入网络表示学习,对于同一网络数据基于3 个初级学习器生成3 部分嵌入并将其拼接,然后选取GCN 作为次级学习器得到最终的嵌入,最后使用评价指标进行评价,具体流程如图2 所示。
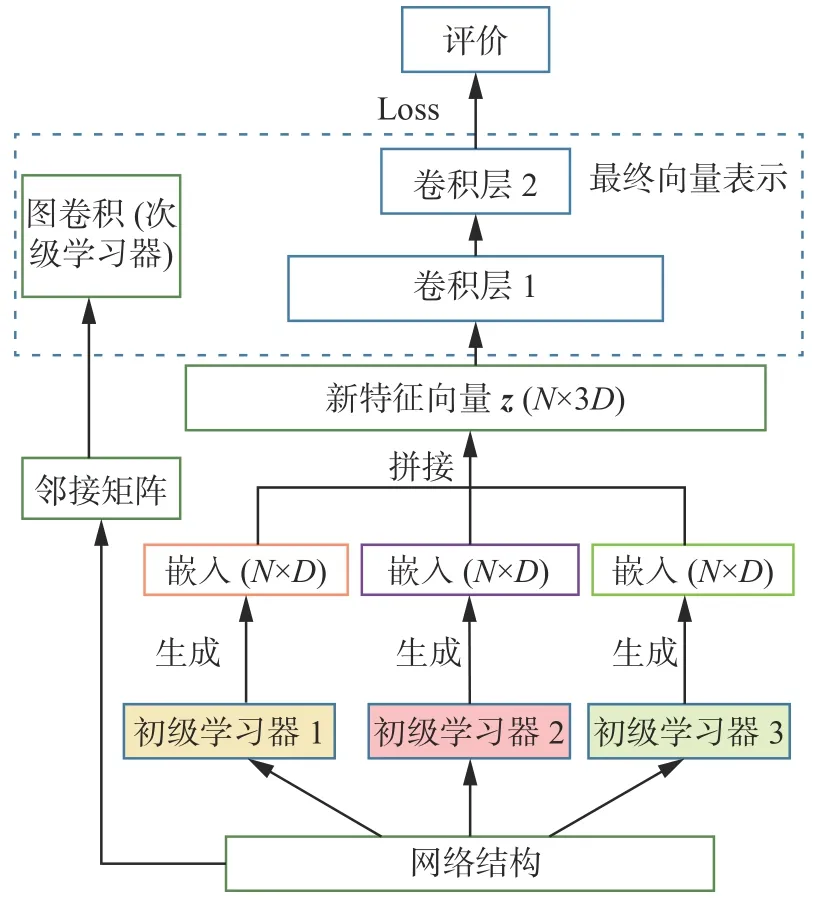
图2 基于GCN 集成的网络表示学习结构Fig.2 Network representation learning structure based on GCN ensemble method
2.1 初级学习器
初级学习器选择DeepWalk[13]、Node2Vec[14]和Line[15]。DeepWalk[13]发现在短的随机游走中出现的节点分布类似于自然语言中的单词分布,于是采用广泛使用的单词表示学习模型Skip-Gram模型学习节点表示;
Node2Vec[14]认为DeepWalk的表达能力不足以捕捉网络中连接的多样性,所以设计了一个灵活的网络邻域概念,并设计随机游走策略对邻域节点采样,该策略能平滑地在广度优先采样(BFS)和深度优先采样(DFS)之间进行插值;
Line[15]是针对大规模的网络嵌入,可以保持一阶和二阶邻近性。图3 给出了一个说明示例,节点6 和节点7 之间边的权重较大,即节点6 和节点7 有较高的一阶邻近性,它们在嵌入空间的距离应很近;
虽然节点5 和节点6 没有直接相连的边,但是它们有很多共同的邻居,所以它们有较高的二阶邻近性,在嵌入空间中距离也应很近。一阶邻近性和二阶邻近性都很重要,一阶邻近性可以用两个节点之间的联合概率分布度量,vi和vj的一阶邻近性如式(1):
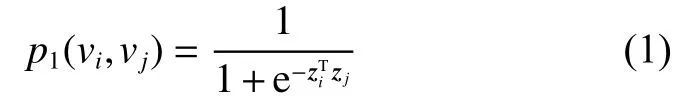
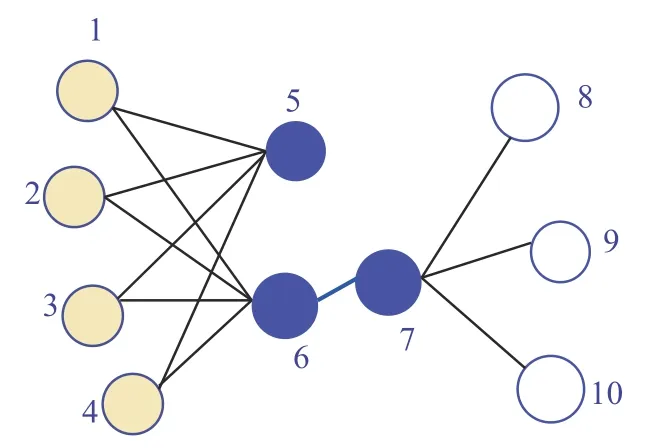
图3 网络简单示例Fig.3 Simple example of network
二阶邻近性通过节点vi的上下文节点vj的概率建模,即
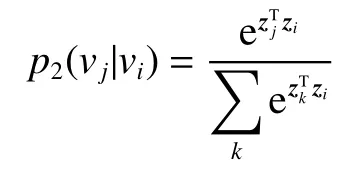
条件分布意味着在上下文中具有相似分布的节点彼此相似,通过最小化两种分布和经验分布的KL 散度,可以得到既保持一阶邻近性又保持二阶邻近性的节点表示。
2.2 次级学习器
引入stacking 集成方法学习网络表示,选择DeepWalk[13]、Node2Vec[14]和Line[15]作为初级学习器。若初级学习器是同种的则为同质集成,否则为异质集成。3 个初级学习器学习得到的嵌入分别是z1、z2、z3,且维数均设为d,并将z1、z2、z3拼接得到嵌入z",维数为3×d。这个过程中不使用节点的辅助信息,仅利用网络的拓扑结构学习节点的特征表示。选用GCN 图卷积网络模型[21]作为stacking 的次级学习器,学习得到最终的嵌入z,维数是d。
GCN 模型的输入有两部分,若网络G有N个节点,则一部分是嵌入z",每个节点有H维,其大小为N×H,另一部分是网络G的邻接矩阵A,其大小为N×N。首先,通过计算得到归一化矩阵∈Rn×n,如式(2):

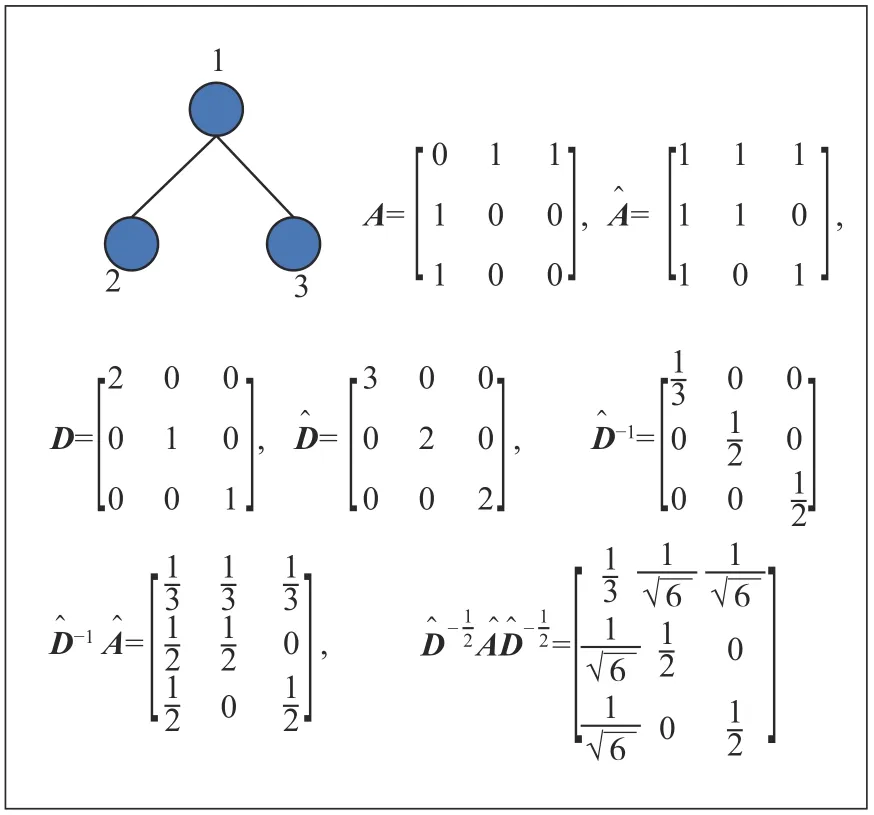
图4 拉普拉斯矩阵示例Fig.4 Example of Laplacian matrix
然后,GCN 的整体结构如图5 所示,用式(3)、(4)描述:
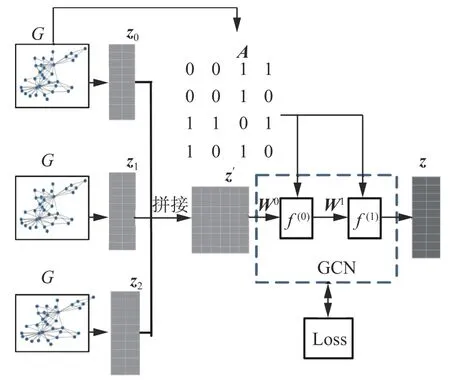
图5 图卷积集成网络模型结构Fig.5 Structure of GCN ensemble model
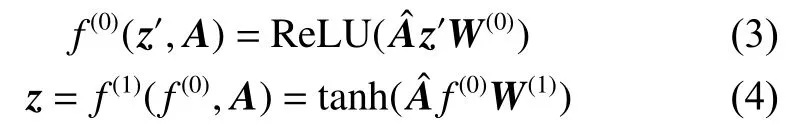
2.3 损失函数
利用网络的一阶邻近性设计损失函数,根据噪声分布对边采样负边,任意边的损失函数为
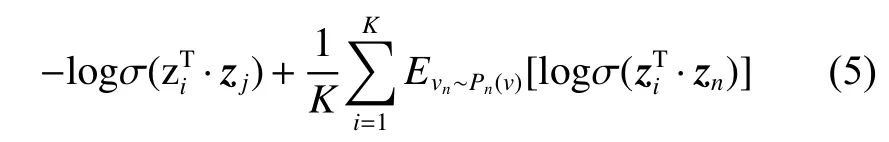
式中:第一项是根据观测到的边即正例的loss;
第二项是为正例采样的负例的loss;
K是负边的个数;
σ(x)=1/(1+exp(−x))是 sigmoid 函数;
设置Pn(v)∝,其在文献[23]中提出,dv是节点v的出度。
边采样根据边的权重选用alias table[15]方法进行,从alias table 中采样一条边的时间复杂度是O(1),负采样的时间复杂度是O(d(K+1)),d表示出度,K表示K条负边,所以每步的时间复杂度是O(dK),步数的多少取决于边的数量 |E|,因此计算损失的时间复杂度为O(dK|E|),与节点数量N无关。此边采样策略在不影响准确性的情况下提高了效率。
2.4 评价指标
通过2.3 节损失函数影响模型的训练学习,得到最终的网络嵌入表示z,对于网络表示学习的无监督性,设计评价指标[24]评价网络表示学习的好坏。对于节点vi和vj之间的边即一个正例,由一对节点(vi,vj)表示,一个正例对应采样K条负边,即采样K个点(n1,n2,···,nk),其中i,j∉(1,K),构成负例集合{(vi,n1),(vi,n2),···,(vi,nk)}。
衡量一对节点的相似度可计算它们网络表示的内积,正例(vi,vj)的相似度s=,负例的相似度sp=,p=(1,2,···,K),相似值越大越好,所以将sp的值由大到小排序,记录s插入{sp}的索引ranking,索引是从0 开始的,衡量指标需要的是排名位置,所以令ranking=ranking+1,ranking 越小说明网络表示学习的嵌入越有效。
上文针对一个正例计算得到了一个ranking,对于整个网络设计指标如表1 所示。

表1 评价指标Table 1 Evaluating indicator
评价数据边的数量为 |E’|,时间复杂度为O(K|E’|)。
2.5 算法描述
基于图卷积集成的网络表示主要包括3 个步骤,首先得到初级学习器的网络表示,然后用stacking 集成,其中次级学习器选用GCN。对于网络表示学习的无监督性在GCN 模型中设计了损失函数,也设计了其测试指标,相关算法如算法1所示。


训练阶段进行模型计算和损失计算,所以训练阶段的时间复杂度是O(|E|HTF+dK|E|),测试阶段的时间复杂度是O(K|E′|),其中H是特征输入维数384,T为中间层维数256,F为输出层维数128,数据边的数量是 |E|,测试数据边的数量是 |E′|。综上所述,总体时间复杂度是O(|E|HTF+dK|E|)。
在6 个数据集上分别对比DeepWalk、Node 2Vec、Line 这3 个经典的网络表示学习方法和stacking 集成后的实验效果,验证GCN 作为stacking 集成次级学习器的有效性。实验环境为:Windows10 操作系统,Intel i7-6 700 2.6 GHz CPU,nvidia GeForce GTX 950M GPU,8 GB 内存。编写Python 和Pytorch 实现。
3.1 实验设定
1)数据集
实验使用6 个真实数据集,即Cora、Citeseer、Pubmed、Wiki-Vote、P2P-Gnutella05 和Email-Enron,详细信息见表2。Cora 是引文网络,由机器学习论文组成,每个节点代表一篇论文,论文根据论文的主题分为7 类,边代表论文间的引用关系。Citeseer 也是引文网络,是从Citeseer 数字论文图书馆中选取的一部分论文,该网络被分为6 类,边代表论文间的引用关系。Pubmed 数据集包括来自Pubmed 数据库的关于糖尿病的科学出版物,被分为3 类。Wiki-Vote 是社交网络,数据集包含从Wikipedia 创建到2008 年1 月的所有Wikipedia 投票数据。网络中的节点表示Wikipedia 用户,从节点i到节点j的定向边表示用户i给用户j的投票。P2P-Gnutella05 是因特网点对点网络,数据集是从2002 年8 月开始的Gnutella 点对点文件共享网络的一系列快照,共收集了9 个Gnutella 网络快照。节点表示Gnutella 网络拓扑中的主机,边表示Gnutella 主机之间的连接。Email-Enron 是安然公司管理人员的电子邮件通信网络,覆盖了大约50 万封电子邮件数据集中的所有电子邮件通信,这些数据最初是由联邦能源管理委员会在调查期间公布在网上的,网络的节点是电子邮件地址,边表示电子邮件地址之间的通信。
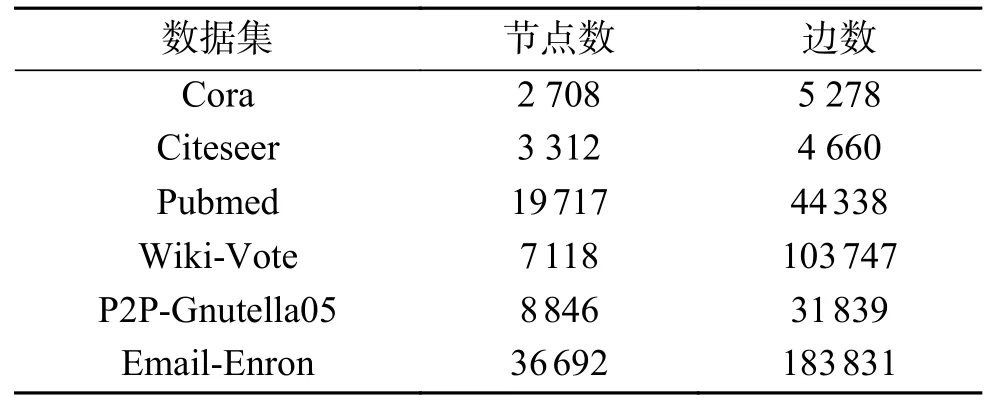
表2 数据集信息Table 2 Dataset information
2)参数设定
对于stacking 集成方法中的GCN 模型,使用RMSProp 优化器更新训练参数,学习率设为0.001,训练次数设为200,卷积层为2 层。对于Deep-Walk 和Node2Vec 共同参数,节点游走次数设为10,窗口大小设为 10,随机游走的长度设为40。Node2Vec 的超参数p=0.25、q=4。对于Line,负采样数设为10,学习率设为 0.025。为了方便比较,上述方法的节点表示维度均设为128。
3.2 异质集成实验结果
实验选择4 个领域的数据集,包括Cora、Citeseer、Pubmed、Wiki-Vote、P2P-Gnutella05 和Email-Enron。对于同一数据集,对比各初级学习器、GCN和stacking 异质GCN 集成的特征表示的质量。GCN的参数设定同stacking 集成方法中的GCN 模型参数。GCN 集成过程中仅使用网络结构,GCN 使用网络结构和数据集的属性特征,数据集没有的使用单位阵代替属性特征。图6 展示了各数据集上的评价指标MRR、Hit@1、Hit@3、Hit@10 的比较,各评价指标平均提升了1.47~2.97 倍。
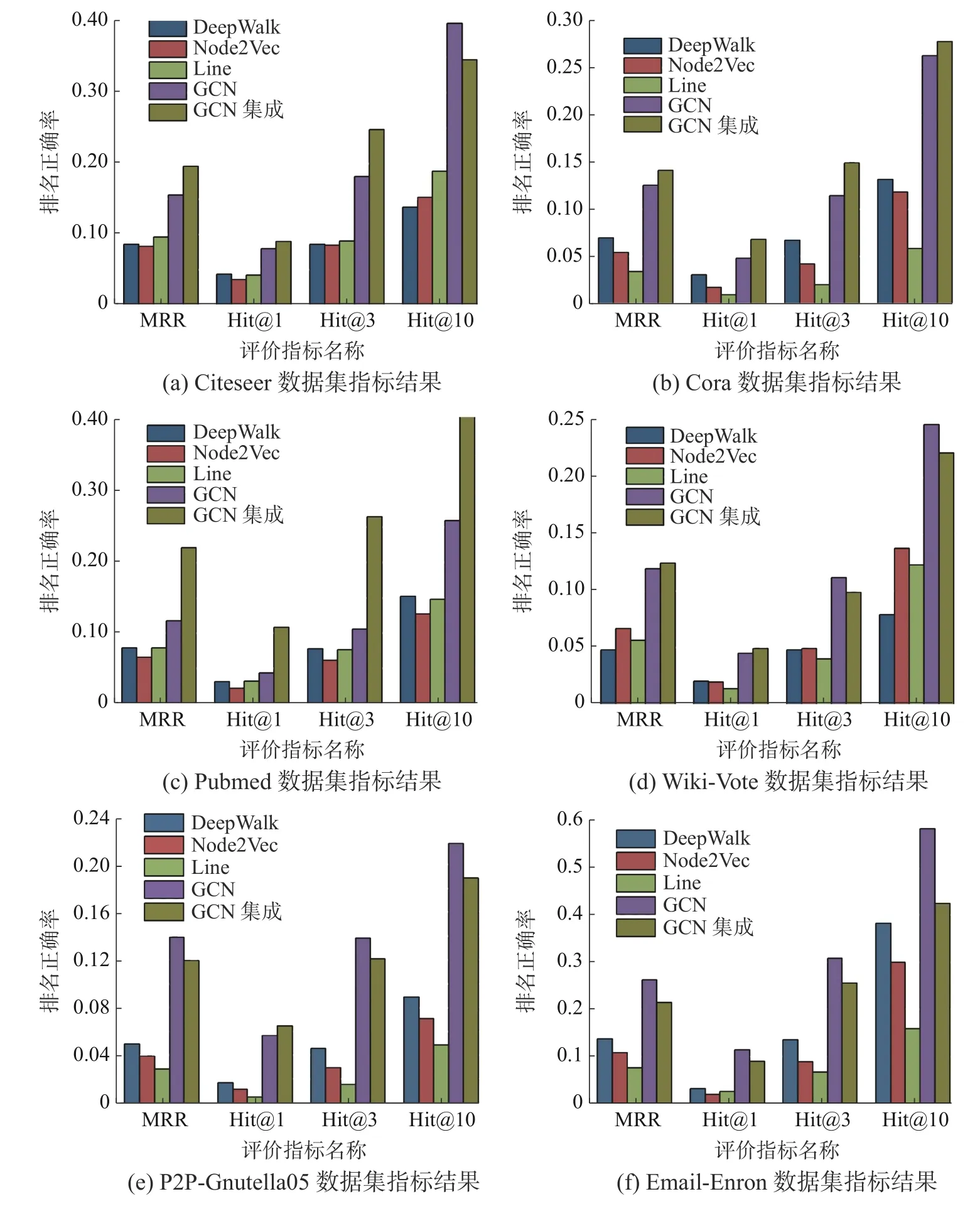
图6 各数据集异质集成评价指标结果Fig.6 Heterogeneous integration of evaluation index results of all datasets
实验结果显示,在各数据集上stacking 集成后的效果明显优于各初级学习器,仅使用网络结构的GCN 集成与使用网络结构和属性特征的GCN效果相当。这一方面归功于初级学习器的“好而不同”,即初级学习器有一定的网络表示学习能力,并且学习器之间具有差异性,会有互补作用;
另一方面归功于GCN 作为stacking 集成次级学习器的有效性,GCN 根据对称归一化拉普拉斯矩阵的性质为邻居分配权重,然后聚合邻居信息。
3.3 损失函数有效性验证
本文根据网络的一阶邻近性设计了损失函数,通过设计使用损失函数和未使用损失函数的实验来验证损失函数的有效性。表3 展示了各数据集评价指标的比较,图中数据集名称的表示未使用损失函数,数据集名称中的“-loss”表示使用了损失函数。实验结果表明,使用损失函数的评价指标与未使用损失函数的相比平均提升了0.44~1.79 倍,验证了本文损失函数的有效性。
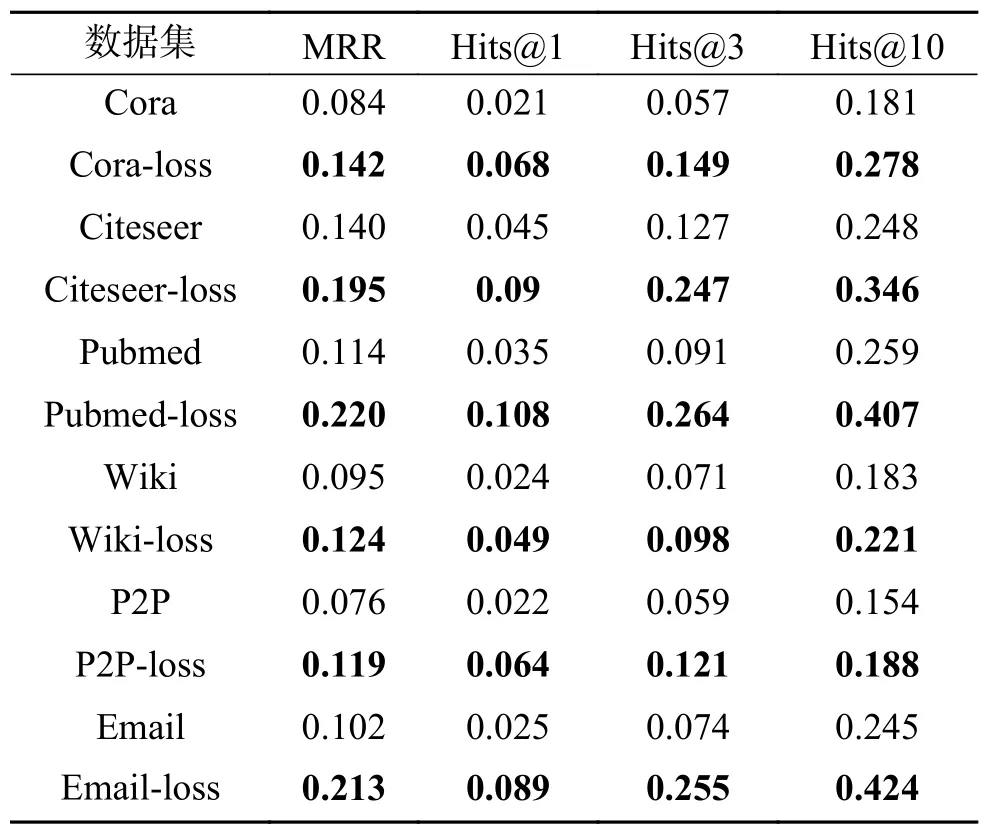
表3 损失函数有效性验证指标结果Table 3 Results of validation index of loss function
3.4 同质集成实验对比
本节对比算法分别进行同质stacking,对比设计如表4 所示,第1~3 行是同质集成,第4 行是3.2 节的实验设定。图7 展示了Cora、Citeseer和P2P-Gnutella05 数据集同质、异质集成及3 个初级学习器对比的实验结果。
表4 对比算法设计Table 4 Design of contrast algorithms
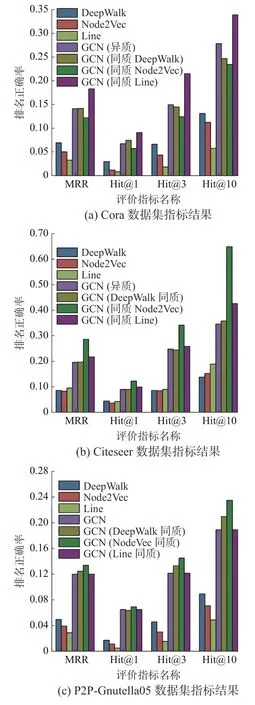
图7 各数据集同质/异质集成对比Fig.7 Comparison of homogeneous/ heterogeneous integration among datasets
实验结果表明,在不同数据集上不同的同质集成各评价指标的表现不同。但是同质集成效果均明显优于初级学习器的效果,平均提升了1.46~1.91 倍,所以异质集成的效果平均优于同质集成。在Cora 数据集上,DeepWalk 和Node2Vec 同质集成的效果略差于异质集成,Line 同质集成略好于异质集成;
在Citeseer 数据集上,DeepWalk 同质集成效果与异质集成相当,Line 和Node2Vec同质集成略好于异质集成;
在P2P-Gnutella05 数据集上,Line 同质集成效果与异质集成相当,Node-2Vec 和DeepWalk 同质集成略好于异质集成。因为数据集网络结构具有多样性和复杂性,所以在不同数据集上表现效果不同,有的同质集成效果略优于异质集成。GCN 不仅可以作为集成器,本身也是学习器,有一定的学习能力。
3.5 参数敏感性分析
本节进行参数敏感性实验,主要分析不同特征维度对性能的影响。实验选用Cora 数据集,图8 分别展示了MRR 和Hit@1、Hit@3、Hit@10 的实验结果。
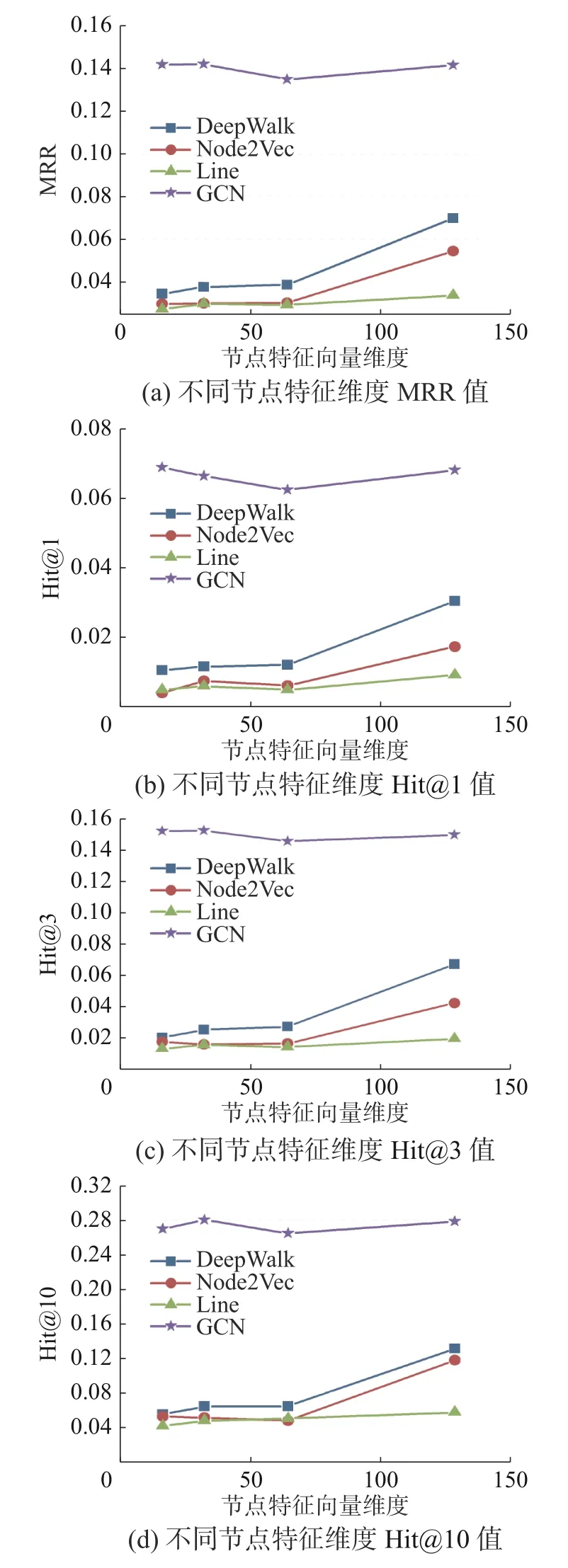
图8 参数敏感性分析Fig.8 Parametric sensitivity analysis
实验结果表明,节点特征向量维度增加到128 时,初级学习器的效果没有明显提升;
但是GCN 异质集成的效果却没有大幅受节点特征向量维度的影响,说明节点特征维度不是实验结果的重要影响因素。
在网络表示学习中,如何设计算法学习到高质量的节点表示仍是一个重要的研究课题。本文引入了stacking 集成方法学习网络表示。首先并行训练多个简单的初级学习器,并将它们的嵌入拼接,选用GCN 作为次级学习器,聚合得到最终的网络表示,然后对网络表示学习的无监督性,利用网络的一阶邻近性设计损失函数;
最后改进了评价指标MRR、Hit@1、Hit@3、Hit@10,分别测试初级学习器和集成后的节点特征向量表示,验证了提出算法具有较好的网络表示性能。
在6 个数据集上进行实验,在各数据集上stacking 集成后的效果明显优于各初级学习器,因为GCN 作为stacking 异质集成次级学习器的有效性及初级学习器的“好而不同”。对比算法选择stacking 同质集成进行比较,实验结果表明同质集成的效果均明显优于初级学习器,且异质集成的效果平均优于同质集成,有的数据集同质集成效果由于异质集成是由于GCN 不仅是集成器,更是学习器,有一定的学习能力。对于参数敏感性分析,实验结果表明节点向量维度不是实验结果的重要影响因素。
未来研究工作包括探索其他算法作为初级学习器、次级学习器对集成的影响和探索如何提高不同网络结构的适应性去处理归纳性任务。
猜你喜欢 同质集上异质 GCD封闭集上的幂矩阵行列式间的整除性四川大学学报(自然科学版)(2021年6期)2021-12-27基于异质分组的信息技术差异化教学家庭教育报·教师论坛(2021年42期)2021-12-23《拉奥孔》中“诗画异质”论折射的西方写实主义传统河北画报(2021年2期)2021-05-25“对赌”语境下异质股东间及其与债权人间的利益平衡北方论丛(2021年2期)2021-05-22基于互信息的多级特征选择算法计算机应用(2020年12期)2020-12-31“形同质异“的函数问题辨析(上)理科考试研究·高中(2017年7期)2017-11-04近现代中国与西方体育文化间性研究首都体育学院学报(2017年3期)2017-06-05浅谈同质配件发展历程汽车零部件(2015年1期)2015-12-05师如明灯,清凉温润文苑(2015年9期)2015-09-10聚焦国外同质配件发展历程汽车维修与保养(2015年7期)2015-04-17






