基于KPCA和BiLSTM的分解炉出口温度预测
时间:2023-07-01 11:25:01 来源:雅意学习网 本文已影响 人 
孟 忍, 董学平, 甘 敏
(1.合肥工业大学 电气与自动化工程学院,安徽 合肥 230009; 2.福州大学 数学与计算机科学学院,福建 福州 350108)
水泥工业是我国国民经济建设的重要基础材料产业。因为分解炉运行状况的关键性能指标是分解炉出口温度,所以对分解炉出口温度的研究具有重要意义[1]。近年来,有很多学者对分解炉出口温度的预测方法进行研究。文献[2]提出一种出口温度预测模型基于遗传算法优化BP神经网络的方法,进行实验并验证其效果;文献[3]提出一种基于递推最小二乘和ARMAX的分解炉温度预测模型。上述2种方法使用传统神经网络的方法对分解炉出口温度进行预测,因为不具备从过去和将来的数据中学习信息的能力,所以影响分解炉出口温度的预测精度。
上述研究都只在其风、料、煤等主要传统经验的基础上进行研究,具有很大的局限性。因此将数据筛选方法与神经网络算法相结合的方法,能够较为准确地把握分解炉出口温度特性。文献[4]将核主成分分析(kernel principal component analysis,KPCA)非线性降维应用于财务危机预警模型的建立,并进行实验验证其效果,表明KPCA在处理非线性数据方面具有较好的能力;因此文献[5]应用注意力机制的长短期记忆(long short-term memory,LSTM)神经网络建立PM2.5预测模型的方法,并验证其效果;文献[6]应用双向长短斯记忆(bidirectional long short-term memory,BiLSTM)神经网络构建刹车片寿命预测模型,通过对比实验验证了模型的优越性。上述方法均体现了神经网络的优越性,但是由于分解炉出口温度具有非线性、多干扰、大时滞等特性,仅把神经网络的方法运用于分解炉出口温度的预测方面,忽略了出口温度变化的非线性特征,影响了预测精度。
本文提出一种基于KPCA结合BiLSTM的分解炉出口温度预测模型。引入KPCA可有效地提取变量的非线性特征,筛选出包含主要信息的主成分,降低影响因素的变量维度;然后将降维所得的主元作为BiLSTM神经网络的输入,通过分析不同隐含层和神经元个数对模型的影响,建立分解炉出口温度预测模型,并进行实验确定模型精度,从而完成对出口温度的预测。通过仿真实验证明,基于KPCA-BiLSTM的分解炉出口温度预测模型具有良好的预测精度。
1.1 核主成分分析法
模式识别中线性特征的提取和数据表示一般用主成分分析(principal component analysis,PCA),当训练数据集中的样本数量相对少时,较难获得准确的协方差矩阵,并且通常用于非线性数据处理时无法获得最佳的预期效果[7]。作为减少非线性特征维数的算法,KPCA使用核的思想以线性方式将非线性样本空间映射到高维特征空间,然后进行线性降维。在解决提取非线性特征的问题方面,KPCA具有比PCA更好的效果,利用核函数可以有效地保留原始数据的特征,并最大限度地提取数据中包含的非线性信息[8]。KPCA具有以下特点:原始数据通过非线性映射函数映射到高维空间,并且空间中的所有样本都可以线性表示空间中的任何向量。
PCA是一种线性主成分分析方法,对于原始数据构成的矩阵,首先进行标准化处理得到新的样本集xk(k=1,2,3,…,m;xk∈Rn),再对新的样本集计算其协方差矩阵,即
(1)
然后求得矩阵C的特征值和特征向量。
KPCA是PCA的非线性间接扩展[9]。KPCA首先对样本xk进行非线性变换φ(xk),将其映射到高维特征空间F,此时协方差矩阵为:
(2)
上述矩阵的特征值λ和特征向量V满足以下条件:
λV-CV=0
(3)
引入非线性函数φ(xk),可得:
λφ(xk)V-φ(xk)CV=0
(4)
(4)式中的特征向量V可由φ(xi)线性表示,即
(5)
将(2)式、(4)式代入(3)式,并引入核函数Kij=K(xi,xj)=φ(xi)φ(xj),简化后得:
mλα-Kα=0
(6)
其中,α为核矩阵K的特征向量。对于任意样本,在特征空间F中主元φ(x)上的投影为:
(7)
(8)
其中:L为m×m阶单位矩阵,其系数为1/m。
1.2 双向长短期记忆神经网络
LSTM是目前应用比较广泛,并得到高度认可的神经网络,它可以克服循环神经网络(recurrent neural network,RNN)中梯度消失的问题[10]。因为其具有独特的设计结构,所以LSTM适合处理和预测时间间隔长且时间序列延迟的重要事件。LSTM的单元结构由4个部分组成,每个部分之间存在交互,分别为遗忘门、输入门、信息更新和输出门,LSTM内部结构如图1所示。

图1 LSTM内部结构
LSTM内部结构的第1部分为遗忘门,如图1中①所示,即通过sigmoid函数从上一个时刻的输出和本时刻的输入值中丢弃部分信息,其表达式为:
ft=σ(Wf[ht-1,xt]+bf)
(9)
第2部分为输入门,如图1中②所示,该部分的功能是确定需要更新哪些信息,并通过sigmoid和tanh函数进行过滤,需要更新的信息表达式如下。
经过σ函数过滤后可得:
it=σ(Wi[ht-1,xt]+bi)
(10)
经过tanh 函数过滤后可得:
Ct′=tanh(Wc[ht-1,xt]+bc)
(11)
第3部分为信息更新,如图1中③所示,它将遗忘门和上一时间点的信息更新值相乘并与输出门的2个值的乘积相加,细胞状态的更新公式为:
Ct=ftCt-1+itCt′
(12)
第4部分为输出门,如图1中④所示,该输出值是基于以上的3个步骤。首先利用sigmoid函数选择部分输入门的信息;然后利用tanh函数功能用于选择和过滤更新后的信息;最后将2个选定的信息相乘以获得此时的细胞输出值,其表达式如下。
经过σ函数过滤后可得:
ot=σ(Wo[ht-1,xt]+bo)
(13)
ht=ottanh(Ct)
(14)
其中:σ为sigmoid激活函数;xt为时刻t的输入值;ht-1为t-1时刻的输出值;Ct为细胞信息更新值;Wc、Wi、Wo、Wf分别为细胞状态、输入门、输出门和遗忘门;bc、bi、bo、bf分别为细胞状态、输入门、输出门、遗忘门的偏置值。
本文选取神经网络中常用的sigmoid 函数作为σ函数,其表达式为:
s(x)=1/(1+e-x)
(15)
LSTM具有以非常长的时间间隔和时间序列中的延时来处理和预测大型事件的特征,但是它只能根据过去的数据预测信息,BiLSTM具有能够从过去和将来的数据中学习信息的能力,BiLSTM的结构示意图如图2所示,图2从上到下依次为输入层、前向层、后向层和输出层,BiLSTM 的基本思想是每个学习序列分别作为长短期记忆神经网络的向前和向后的2个神经网络,并且这2个层分别连接到输入层和输出层。输出值整合了过去(前向)和未来(反向)的信息,分析了不同隐含层和神经元数量对模型的影响,建立了分解炉出口温度预测模型,并进行仿真实验以确定模型的准确性。

图2 BiLSTM神经网络结构
在BiLSTM中的每一个时间点都有8个唯一的权重值被重复使用,并且每个值对应的8个权重值在前隐藏层和后隐藏层中,输入的权重值(w1,w4)前向隐藏层到前向隐藏层(w2,w3)、后向隐藏层到后向隐藏层(w6,w7)、前向隐藏层和后向隐藏层到输出层(w5,w8)。尤其要注意的是前向隐藏层和后向隐藏层之间没有进行信息传递,这样可以避免2个隐藏层的相邻2个时间点之间形成死循环。其计算方式为:在前向层从1时刻到t时刻正向计算1次,得到并保存每个时间点向前隐藏层的输出;在后向层沿着时刻t到时刻1反向计算1次,得到保存每个时间点向后隐藏层的输出;最后在每个时间点结合前向层和后向层的相应时刻输出的结果得到最终的输出,数学表达式为:
ht′=f(w1xt+w2Ct-1′+w3ht-1′)
(16)
ht=f(w4xt+w6Ct-1+w7ht-1)
(17)
ot=g(w5ht′+w8ht)
(18)
模拟数据取自于实际生产的水泥数据。在变量选择方面,大多数研究者[11-12]围绕三次风温、分解炉喂料量、分解炉喂煤量这3个主要变量对分解炉出口温度进行研究。因为分解炉内部结构复杂且变量众多,所以难以依靠经验法选取变量来全面概括分解炉的内部规律。结合分解炉结构与工况,选取包含分解炉喂料量、分解炉喂煤量、三次风压和出口压力等在内的22个变量用来对分解炉出口温度进行分析,并选用KPCA数据降维的方法对22个变量进行参数估计,用来筛选相关变量。
2.1 KPCA自变量降维处理
KPCA进行自变量的降维,使用Python编程实现,下面对其关键步骤进行说明。
(1)数据预处理。首先对数据进行标准化,处理后均值为0,方差为1。
(2)采用高斯径向基核函数,求核矩阵。高斯径向基核函数为:
(19)
其中:x为空间中任一点;xc为核函数中心;σ为函数的宽度参数,控制函数的径向作用范围。
(3)对矩阵进行中心化,得到一个新的矩阵。
(4)特征值分解。找到协方差矩阵的特征向量和特征值,将对角线矩阵与主对角线上的特征值转换为特征值的列向量,并按降序排列特征值。
(5)对主元的贡献率进行确定。计算每个特征值的贡献率以及累计贡献率,并将主元所在特征值向量中的序号记录下来,同时保存主元序号以及主元的个数。
(6)计算每个主元向量以及各主元所对应的特征向量,并构建主元矩阵。经过KPCA 降维处理之后,分解炉出口温度的影响因素由22维降至4维,累计贡献率达到90%以上。KPCA对前4个主成分的单个贡献率及累计贡献率见表1所列。

表1 KPCA对22个影响因素的处理结果 %
为了更好地验证KPCA在数据筛选方面的优越性,引入用PCA数据筛选方法处理主成分的单个贡献率及累计贡献率,见表2所列。
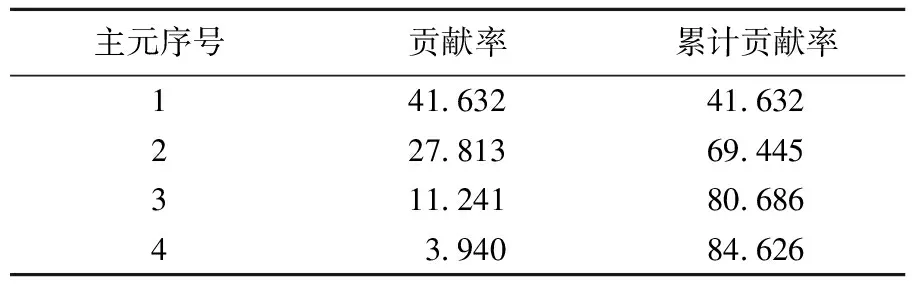
表2 PCA对22个影响因素的处理结果 %
因为分解炉出口温度具有非线性、强耦合性、多干扰、大时滞等特征,所以PCA只能进行线性变化,在非线性数据处理时往往得不到较好的期望效果;而KPCA可以进行非线性变化,能将原数据通过引入隐性非线性映射函数映射到高维空间,然后对此空间执行算法进行线性降维,对数据的筛选效果更好。实验结果表明,KPCA对主成分的累计贡献率要高于PCA。
2.2 KPCA-BiLSTM模型整体流程
为了得到精确的预测结果,使用KPCA数据降维与BiLSTM神经网络相结合的方法,从而给出KPCA-BiLSTM的组合模型。KPCA-BiLSTM组合模型的整体流程如图3所示。

图3 KPCA-BiLSTM模型的整体流程
3.1 实验设计
仿真实验采用某公司6 000 t/d水泥生产线的生产数据,利用所测得的1 100组数据进行分析预测,其中:900组作为训练集;200组作为测试集。由于数据包含温度、压强等不同量纲的变量,需要将输入变量进行归一化处理,计算公式为:
(20)
为进一步验证KPCA-BiLSTM分解炉出口温度预测模型的准确性,将经过归一化处理和KPCA筛选后得到的数据作为BiLSTM神经网络的输入,将得到的预测值与真实值进行对比,通过对比不同的神经网络算法在分解炉出口温度预测的精度,来验证KPCA-BiLSTM模型的有效性。为进一步验证模型的准确性,选取平均绝对百分比误差(mean absolute percentage error,MAPE)和均方根误差(root mean square error,RMSE)作为评价指标对模型的预测精度进行定量分析。计算公式为:
(21)
(22)
其中:n为测试样本数;yt为测试样本实际值;yp为模型预测值。
3.2 组合预测模型在分解炉温度预测中的实现
选取1 100组数据,选取其中200组作为测试集,利用前文2.1节KPCA得到的降维结果作为神经网络的输入,将BiLSTM的时间步数设置为3,优化算法选择随机梯度下降的Adam函数,得到预测值与真实值的变化趋势如图4所示。从图4可以看出,KPCA-BiLSTM模型在真实温度波动较大的情况下仍可以实现较好的预测,预测结果最接近真实值。同时在40~60、80~140、125~150温度波动范围较大的预测点和在25~50温度变化较快的预测点范围内,使用KPCA-BiLSTM模型也能实现较好的预测效果。

图4 KPCA-BiLSTM组合模型拟合曲线
为了更全面地评价模型的有效性与优越性,分别引入不进行数据降维的BiLSTM模型,以及用PCA和KPCA进行数据降维后的KPCA-LSTM组合模型,PCA-BiLSTM组合模型与KPCA-BiLSTM组合模型进行对比,最终预测值和真实值的MAPE和RMSE对比结果见表3所列。
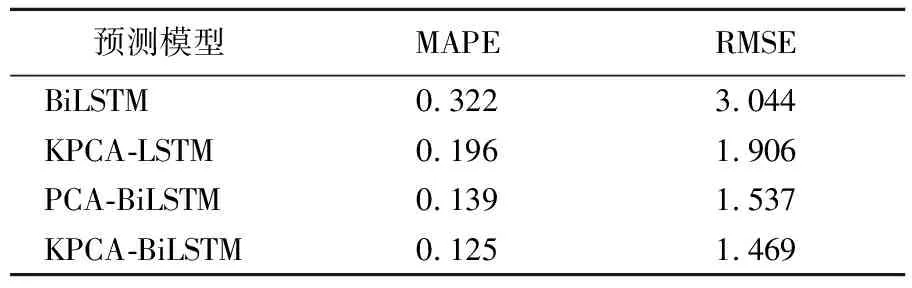
表3 预测结果误差对比
从表3可以看出,KPCA-BiLSTM组合模型具有最好的预测性能。相较于PCA-BiLSTM模型,KPCA-BiLSTM模型的MAPE降低了0.014,RMSE降低了0.068;相较于KPCA-LSTM模型,KPCA-BiLSTM模型的MAPE降低了0.071,RMSE降低了0.437;相较于BiLSTM模型,KPCA-BiLSTM模型的MAPE降低了0.197,RMSE降低了1.575。因此,本文提出的预测模型是可行的。
使用不同预测模型处理变量的预测结果如图5所示。

图5 不同预测模型下的预测值与真实值
从图5可以看出,仅使用BiLSTM神经网络预测的结果整体上与实际值偏差较大,尤其是在温度剧烈变化的预测点处,预测结果均大于真实值。使用KPCA-LSTM组合预测模型,因为LSTM只具备处理和预测时间序列中间隔和延迟比较长的事件,不具备利用过去和未来数据的信息进行学习的能力,所以在经过KPCA降维处理后,预测效果会有提前上升和滞后下降的过程。对比PCA-BiLSTM模型和KPCA-BiLSTM模型,因为BiLSTM具有对过去和未来信息学习的能力,所以相比较而言都有较好的预测精度。因为PCA只能进行线性变化,在非线性数据处理时往往得不到较好的期望效果,而KPCA可以进行非线性变化,所以能将原数据通过引入隐性非线性映射函数映射到高维空间,然后对此空间执行算法进行线性降维,对数据的筛选效果更好。从图5还可以看出,KPCA-BiLSTM模型的拟合效果更优于PCA-BiLSTM模型的拟合效果。由此可见,基于KPCA-BiLSTM模型的分解炉温度预测不仅在总体上提高了分解炉温度预测的精度,而且在各个预测点的值与真实值的差值相对较小。
由于分解炉出口温度具有非线性、强耦合性、多干扰、大时滞等特征,因此本文提出了使用KPCA进行变量筛选从而来降低影响分解炉出口温度数据的维度,在此基础上引入BiLSTM神经网络,提出一种基于KPCA-BiLSTM的组合预测模型。同时与BiLSTM、KPCA-LSTM、PCA-BiLSTM等组合模型进行对比分析,得到KPCA-BiLSTM组合模型能够精确地预测分解炉的出口温度,有效地提高了预测精度。
猜你喜欢降维神经网络出口上半年我国农产品出口3031亿元,同比增长21.7%今日农业(2022年14期)2022-09-15混动成为降维打击的实力 东风风神皓极车主之友(2022年4期)2022-08-27降维打击海峡姐妹(2019年12期)2020-01-14神经网络抑制无线通信干扰探究电子制作(2019年19期)2019-11-23一只鹰,卡在春天的出口学生天地(2017年11期)2017-05-17基于神经网络的拉矫机控制模型建立重型机械(2016年1期)2016-03-01一种改进的稀疏保持投影算法在高光谱数据降维中的应用火控雷达技术(2016年1期)2016-02-06复数神经网络在基于WiFi的室内LBS应用大连工业大学学报(2015年4期)2015-12-11基于支持向量机回归和RBF神经网络的PID整定海军航空大学学报(2015年4期)2015-02-27米弯弯的梦里有什么文学少年(小学版)(2014年2期)2014-11-29







