面向真实道路驾驶行为训练环境研究
时间:2023-06-20 19:55:04 来源:雅意学习网 本文已影响 人 
李康成,徐 野,哈 乐
(1.沈阳理工大学 自动化与电气工程学院,沈阳 110159;
2.北部战区总医院 医学工程科,沈阳 110013)
虚拟驾驶仿真教学是推进现代信息技术与教 学深度融合的重要举措[1],驾驶员的驾驶行为、驾车环境与行车安全密不可分,早期国内车辆保险公司没有考虑驾驶行为与机动车辆保险费的关联,投保人的车险保费设定存在严重不合理现象[2]。应该从驾驶行为的从车因子和从人因子衡量被保险人的风险水平,确定车险费率,但是上述因子并不能很好地反映驾驶人的风险水平[3],“从人”因素记录的多为静态驾驶数据,比如车主的性别、年龄等[4],不能代表车主的实际驾车习惯,无法与实际车辆驾驶风险合理匹配。国外研究人员通过安装车载诊断硬件收集驾驶员驾驶车辆过程中的行为数据[5],包括驾驶员的发动机转数、节气门位置、发动机负载等数据,并对用户驾驶行为数据进行分析与处理,从而识别从事不安全驾驶行为的驾驶员。目前该种方式在国内显然不具备可行性。
强化学习是机器学习的范式和方法论之一,用于描述和解决智能体在与环境的交互过程中通过学习策略达成回报最大化或实现特定目标的问题[6],深度学习(Deep Learning,DL)的基本思想是通过多层的网络结构和非线性变换,组合低层特征,形成抽象的、易于区分的高层表示,以发现数据的分布式特征表示[7]。谷歌的人工智能研究团队DeepMind将具有感知能力的深度网络和具有决策能力的强化学习结合,即深度强化学习(Deep Reinforcement Learning,DRL)[8]。DRL广泛应用于机器人[9]、象棋游戏[10]、斗地主[11]、自动驾驶[12]等诸多领域。
针对训练环境无法与现实驾驶环境规范匹配问题,本文重点研究如何构建基于强化学习算法、面向真实道路行车规则的驾驶行为仿真训练平台UBI_Robot-v0。该方法通过从模拟驾驶环境交互数据中实现状态到动作决策的映射规律;
模拟驾驶环境设计上引入高德人地关系大数据,实现面向真实道路驾驶行为训练;
针对驾驶行为智能体与环境的交互特点进行马尔科夫决策过程(Markov Decision Process,MDP)设计。
1.1 驾驶行为属性描述
驾驶模式受驾驶员、车辆、天气、时间、速度限制、道路类型、街道功能、路口密度和交通状况等因素的影响[13]。对评判驾驶行为智能体而言,统计如表1的驾驶行为属性信息,记录车辆驾驶过程关键风险因素,可较好描述驾驶模式。

表1 驾驶行为属性描述
驾驶仿真参考了以下运动学原理。
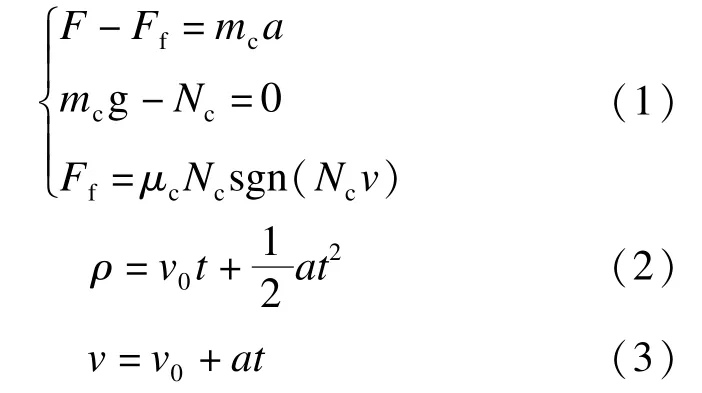
式中:F为汽车牵引力;
Ff为汽车与路面的摩擦力;
mc为车身质量;
Nc为支持力;
μc为动摩擦因数;
g为重力加速度;
ρ、v、a为t时刻的路程、速度、加速度;
sgn()为符号函数,作用是限制车在垂直方向上运动;
v0为驾驶的初速度。不同类型车面临不同的驾驶属性,如车身质量、驱动力,为统一描述,驾驶属性把前进方向加速度a作为最终决策变量。
1.2 道路环境属性描述
驾车问题中影响驾驶员驾驶行为的关键外部因素是变化的道路状况。不同路段的道路等级和道路类型限速标准不同,当车主驾驶距离越长,风险暴露越大,事故发生概率越大[14],需挑选影响驾驶安全程度较大的驾驶行为因子作为评价驾驶行为的指标[15],道路环境属性描述见表2。
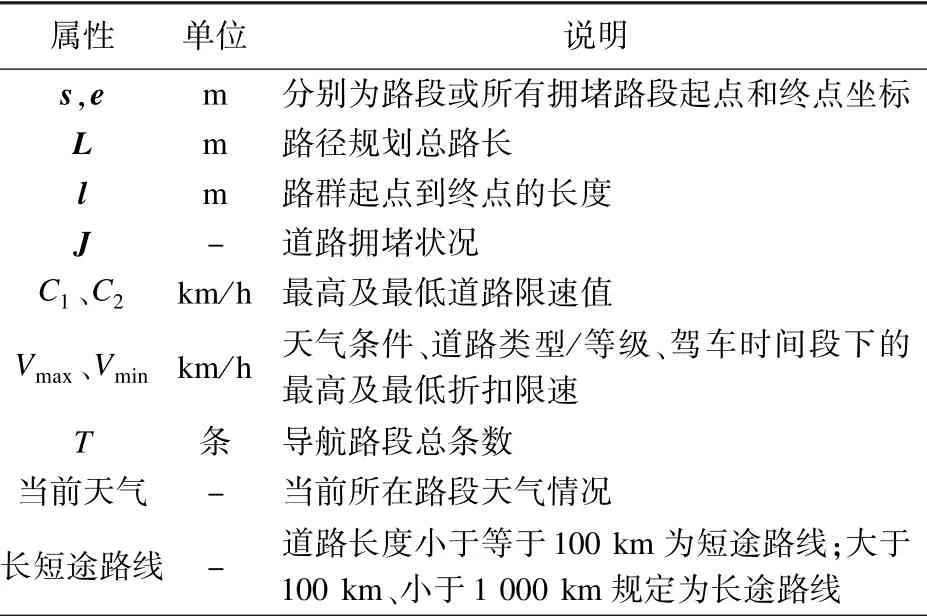
表2 道路环境属性描述
1.3 高德数据驱动的道路仿真环境模型
1.3.1 道路环境生成
高德开发平台具有国内领先的人地关系大数据平台,数据采集能力覆盖国内300余城市,含有超650 km的导航道路数据,超400种道路属性,构建的道路状况稳定可靠。UBI_Robot-v0高德数据处理模型如图1所示。
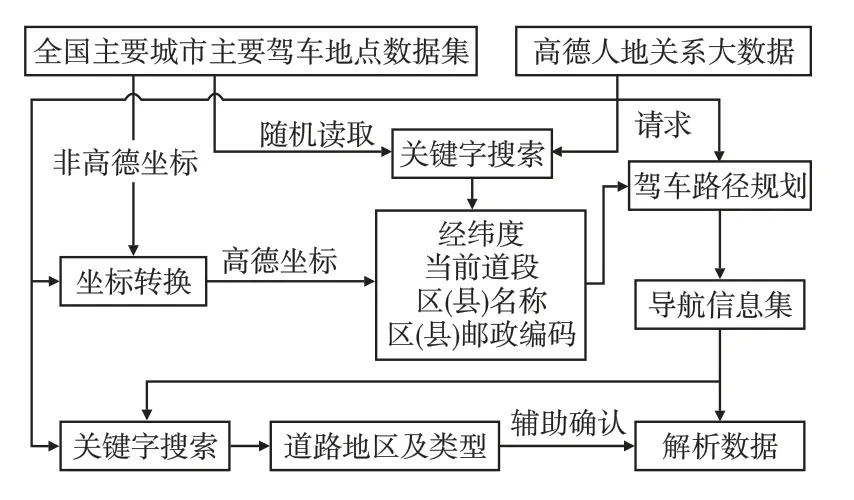
图1 高德数据处理模型图
模型从全国主要城市驾车地点数据集中设定此次驾驶任务的起点和终点,关键字搜索返回起点和终点的经纬度及所在区(县)名称与邮编信息;
信息经高德驾车路径规划获取原始导航信息集λ(λ1,λ2,…,λT),λ含T条成串的道路名称、地区信息集D,路径规划的路线总长为L(l1,l2,…,lt),t≤T,其中lt为第t次导航道路群的总路长。通过数据解析,生成表2的道路环境属性,该解析处理过程如下。
(1)语句字段识别。高德导航有规范的导航主要、辅助动作语句字段,两种字段把导航信息分割成三类或三类以下的分路提示字段U、有效路字段R、无效信息字段Q,其中U={U1,U2},U1为标点符号字段,U2为导航动作语句字段。
(2)道路属性生成。将所有T条导航有效路字段,即∀Rt,0<t≤T,经U1字段对语句进行分块,再通过U2字段对导航道路群lt进行字符串分割、拼接,生成的t条驾车导航路线的路段为

式中n、m、r为对应第l1、l2、lt道路群分割出来的路段数。此时表征所有路段终点e向量为

由于路段间存在连接关系,即后一个路段的起点为上一个路段的终点,s和e可表示为

式中:s(1)1表示L或R(1)1的起点坐标;
·表示第t-1条道路群路段数;
其路段分界随路段信息Rt的个数不同而变化,但导航道路群长度之和l1+l2+…+lt计算的总路长不变,这样能确保仿真的道路都有其路长属性。
对处于第t条驾车导航路线的地区信息群Dt,通过兴趣点搜索可提升地区识别的精度,同时方便辨别驾驶地天气。
(3)道路环境分类。现实的道路类型繁杂,有必要进行量化分析,本文归结为9大类,其限速标准参考《道路交通安全法》,如表3所示。

表3 道路类型属性
道路天气查询流程如图2所示。在不考虑极端天气的情况下,天气类型归结为晴天类、雨天类、雪天类、雾天类四大类。

图2 道路天气查询流程图
将上述道路环境分类结果写成一个独热(one-hot)编码向量,以便更好区分不同天气状况、道路环境状态的描述。
1.3.2 道路拥堵规则
引入路径规划路线上高德拥堵预警信息,并且定时更新拥堵情况J,同时定义拥堵探测距离返回值d,利于智能体学习拥堵状况而提前做出反应。现有T条导航信息,则第t条导航路线上的第j处拥堵点拥堵向量为


若该路线有拥堵,h(j)t为拥堵的长度值,若该路线无拥堵则为畅通长度值。
当车处于前方最近拥堵点1 000 m范围内时,此时的拥堵返回值是基于1 000 m探测距离的百分比。设p为当前驾车位置,则有

式中min(J(j)t)为对所有拥堵点起始坐标升序排序获得离车前方最近拥堵的s(j)t坐标及其索引j。当d(j)=-1时表示车前方1 000 m内无拥堵的情形;
d(j)=-2时表示车辆与拥堵点碰撞的情形。对于驾车路线中车后方的拥堵点,可利用与实时p的关系及时删除并更新J。
为使用较为统一的方法将强化学习方法应用到不同的领域,MDP过程可将问题进一步抽象为状态空间、动作空间、奖赏函数、状态转移矩阵,即MDP通常为一个四元组,其形式为〈S,A,B,P〉,其中S为状态集合,A为有限的动作集合,奖赏值函数B:S×A×S→B为状态-动作好坏的程度,P:S×B×S×A→[0,1]为状态转移概率,即某一状态执行某一动作后到达另一状态的概率。本文面向无模型的强化学习方法,UBI_Robot-v0的MDP设计不涉及状态转移概率部分。
2.1 状态描述与交互
2.1.1 状态描述
为模拟智能体在道路上行驶,选取影响道路驾驶行为的主要因素并包含在状态集合中。对于n种主要行车状态,其状态描述为

式中si(i=1,2,…,n)表示第i位驾车状态的归一化离散值。
UBI_Robot-v0环境中智能体执行相应的驾驶动作,更新状态参数,环境返还智能体更新好的观察状态组,状态处理流程如图3所示。

图3 状态处理流程图
每一个控制周期都会返回智能体观测到的环境信息,本文选取观测的驾驶环境信息和车辆信息作为状态的输入,环境信息选择解析好的高德数据驾驶地天气、驾驶路段坐标(s,e)和相应道路等级的one-hot向量及日夜限速(22时至次日凌晨5时为夜间驾驶)、基于拥堵起点坐标与当前位置的拥堵探测返回值d;
车辆信息借助运动学方程式(1)和(2)更新,包括启动时间ts、驾车所处的时间段tn或ts+t、当前驾车位置p、车速v、累计驾驶时长t、疲劳时长tf;
上述构成驾驶过程中的观察状态组S,智能体通过深度学习网络对状态S进行好坏程度感知。由于组内多个特征属性量纲不一,梯度下降迭代更新模型参数时采用数据归一化处理,在一定程度上增加了模型的学习能力,减少了训练时间。
2.1.2 状态交互
状态交互与判别为智能体提供合理的环境信息,利于智能体决策。
驾驶过程中的拥堵返回值判别和疲劳驾驶判别过程如图4、图5所示。
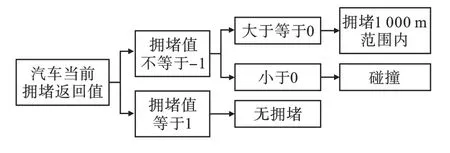
图4 拥堵返回值判别
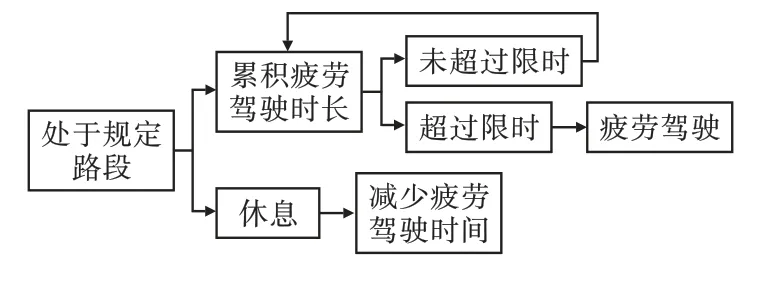
图5 疲劳驾驶判别
由图4可知,根据拥堵返回值可判别无拥堵、1 000 m拥堵探测范围内、碰撞三种情况。图5为疲劳驾驶判别,条件为单次连续计时超过交通运输行业规定的4 h且休息时间少于20 min或累计时间超过8 h。
UBI_Robot-v0环境的速度判别分为限速判别和超速判别两大类;
限速值如表3道路类型属性所示,定义其9种道路类型最高最低限速矩阵为C1、C2,具体为

天气状态为晴天类、雨天类、雪天类、雾天类情况下对应的道路等级/类型折扣加权限速矩阵定义为

车辆在夜间行驶限速值不得超过日间限速值的80%,故日间、夜间行驶的限速折扣加权为离散值k(取1或0.8)。
因此考虑道路类型/等级、天气条件、驾驶时间段的最高折扣限速矩阵为

最低折扣限速矩阵为

超速判别过程如图6所示。

图6 超速判别
采用式(14)、式(15)计算当前路段折扣限速,与当前车速进行对比:若当前车速处于最高限速的90%以内,属于驾车的正常速度范围;
若处于最高限速90%以上且未超速,属于平稳驾车的最优速度范围;
若超速,根据超速程度百分比分为四个等级,表示不同的超速危险级别。
2.2 驾驶动作集合
智能体收集车辆驾驶过程中观察状态组S,提交给神经元算法进行评估,算法评估并优化学习经验,给出理想的驾驶动作;
驾驶动作分为轻加速、急加速、轻减速、急减速、匀速。以一辆正常状态下的汽车作为参考,由道路运输行业相关经验,设定晴天条件下,轻加速动作、急加速动作、轻减速、急减速和匀速动作下的加速度参数值[16]为
A=[1.11 3.09 -1.11 -3.09 0](16)
不同天气条件下采取同一个驾驶动作的刹车滑行距离或者踩油门加速距离不同,本文中晴天类、雨天类、雪天类、雾天类的加速度折扣因子为

驾驶员平稳驾驶动作的加速度集合应为

上式中行向量γT1,γT2,γT3,γT4分别为晴天类、雨天类、雪天类、雾天类天气条件下的4种驾驶动作对应的折扣加速度。
2.3 奖赏值函数设计
智能体会感知来自驾驶环境的奖赏信号,其目标是根据自身策略最大化其奖赏。本文设计的奖赏函数为
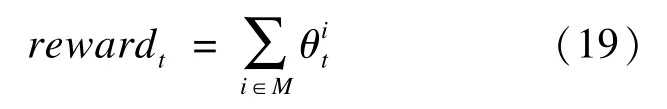
式中:rewardt为在t时刻的累积奖赏反馈值;
为某个状态交互判别的具体奖赏值;
集合M为t时刻所有触发的状态交互判别类型对应的奖赏值,其具体情况如图7所示。

图7 驾驶状态与奖励
以真实路网仿真、驾驶速度与加速度关系、归一化位置轨迹、拥堵探测、折扣限速判别以及超速轨迹生成、驾驶控制效率指标对交互规则进行测试,最后从强化学习智能体驾车平均奖励分析驾驶行为训练环境的有效性。
环境运行日志如图8所示,驾车仿真路网信息如图9所示。为方便描述,已对部分状态进行编号,例如图中道路类型序号3、4、5、7表示城市大路、城市小路、环路、桥梁;
天气序号0表示晴天;
文化路向西的拥堵起点值为9.11,表示在路程总长的91.1%处出现拥堵;
日间/夜间序号1表示驾车时间段为日间。

图8 环境运行日志

图9 高德驾车路网信息
该仿真实验中,环境生成一条起点为“沈阳理工大学北门”、终点为“盛京医院南湖院区”的短途路程,图中起点为汇泉东路,终点为三好街36号,路程总长12 233 m,路段属性包括路长、道路限速以及折扣限速。驾驶行为智能体在环境内驾车运行,总仿真时间为到达终点的时间。
图10为驾车智能体的交互过程,该双轴图描述了智能体驾车速度与加速度、归一化位置轨迹随驾车运行时间的交互情况。
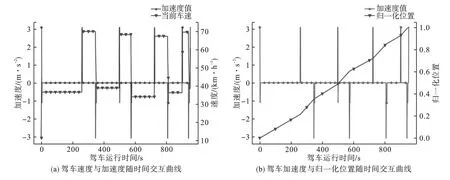
图10 驾车智能体的交互过程
由图10可知,车速关于运行时间的变化率为其驾车方向上的加速度,两者作用方向相同时,归一化位置轨迹曲线斜率变陡,表示离终点越近,反之亦然。图10(a)表示晴天类路网下折扣加速度向量为γ1T的驾驶动作折扣加速度值,可实现车辆的加速、减速、匀速,驾驶动作作用的大小、方向及时长可遍历驾驶动作集合,为智能体的决策变量;
由图10(b)可见,该智能体驾驶全程未停车,故有tf=t,归一化位置最高值为1,表示到达此回合设定的终点。
针对拥堵路段的拥堵位置进行碰撞测试,结果如图11所示。图11中未进入拥堵1 000 m范围内时,拥堵返回值d为-1;
进入1 000 m拥堵探测距离时,返回值d∈(0,1];
返回值d为-2时,表示发生了车辆与拥堵点的碰撞,驾驶结束。
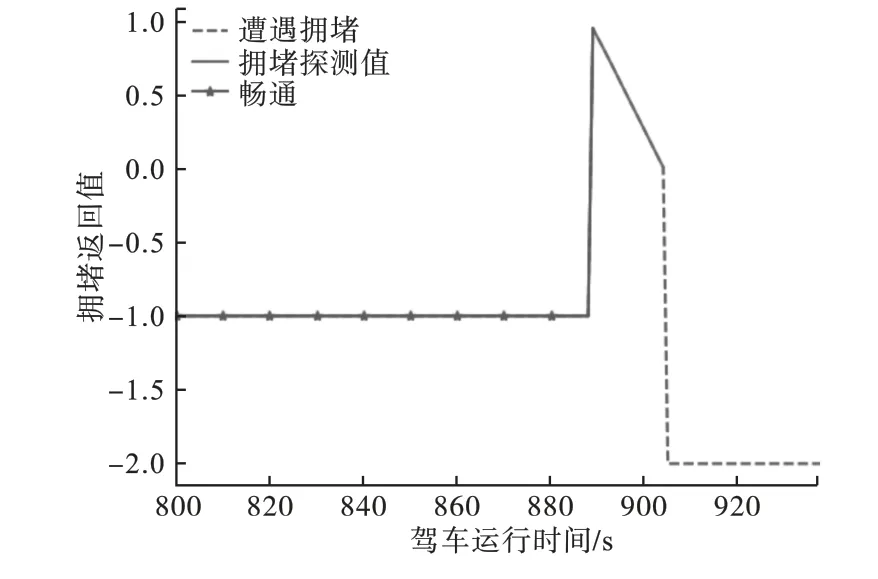
图11 环境探测拥堵返回值
UBI_Robot-v0路网下折扣限速判别曲线、超速轨迹生成曲线如图12所示。

图12 速度曲线
由图12可知,UBI_Robot-v0驾车过程中能生成实时路段、实时地点、实时驾车环境的动态超速识别曲线,驾驶过程中最高、最低、最优速度曲线随道路环境、所处天气、驾驶时间段的不同而动态调整。图12中驾驶智能体为获得更平稳的驾驶奖励,其当前车速尽可能地拟合最优驾车速度;
在未极端超速的前提下,采取良好的驾驶动作以快速地通过目的点。
图13是环境驾车控制效率散点图。
驾驶控制效率指标Z是指经智能体驾驶动作后产生小于最高折扣限速的有效控制比,定义为

即有效控制比越接近1,控制效率越好。图1 3中驾驶智能体在面对环境道路属性、天气状态及驾驶时间段转换时有效控制比接近于1,控制效率较好。

图13 驾车控制效率
为验证UBI_Robot-v0环境的适应性与稳定性,采取强化学习A3C算法,在不同的随机种子干扰条件下,对此驾驶环境的奖励进行得分测试,每迭代100回合计算一次平均奖励,得到平均奖励学习曲线,如图14所示。
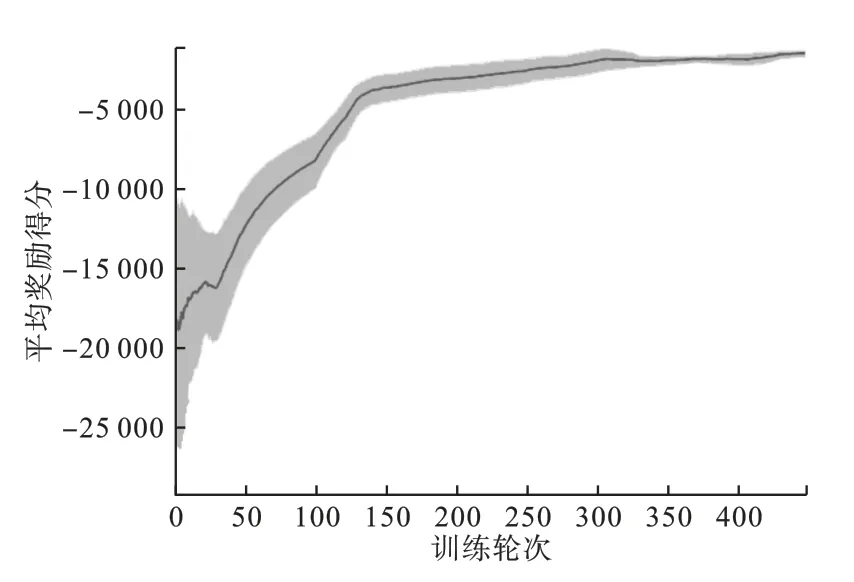
图14 A3C平均奖励学习曲线
由图14可见,迭代训练前期发生微小震荡,但随着训练轮数的提高,平均奖励呈上升趋势并最终趋于收敛;
在不同随机种子下平均奖励曲线保持良好的鲁棒性和稳定性,说明智能体学会如何提高驾驶的奖励分值。
运行于真实道路仿真环境的用户驾驶行为智能体训练有助于驾驶行为智能体进行学习,在满足提升驾车奖励的同时,学会如何在复杂环境下更安全更快速地到达目的点。UBI_Robot-v0训练环境可动态仿真车主驾车环境,执行更为全面、多风险维度结合下的驾驶行为,为驾驶智能体的算法分析与训练研究提供条件;
通过对复杂环境下驾驶行为的仿真分析,不仅有利于驾驶员驾驶习惯的改善、无人自主驾驶策略的研究,同时可尝试车险计价的创新。








